

1. SystÃĻmes de fichiers distribuÃĐs▲
Cette version est une version allÃĐgÃĐe de mon livre sur le cloud computing. La version complÃĻte se trouve ici.
Un systÃĻme de fichiers distribuÃĐ est un systÃĻme oÃđ le poste client accÃĻde à un espace de stockage virtuel unique. Les donnÃĐes peuvent Être rÃĐparties/dupliquÃĐs sur plusieurs machines de façon transparente pour celui-ci. C'est le moteur du systÃĻme de fichiers distribuÃĐ qui a la charge de rÃĐpartir les donnÃĐes et de les dispatcher au client.
Les systÃĻmes de fichier distribuÃĐs les plus rÃĐpandus sont :
- CephCeph ;
- GlusterFSGlusterFSÂ ;
- Hadoop Distributed File System (HDFS)Â ;
- Lustre (utilisÃĐ par les super-calculateurs)Â ;
- NFSNFS - Network File System.
Sur les tests effectuÃĐs, il ressort deux approches :
- une approche en blocs (chunks) rÃĐpartis sur plusieurs machines et pour lesquels les mÃĐtadonnÃĐes peuvent Être centralisÃĐes ou distribuÃĐes et permettent de reconstruire les fichiers ;
- une approche reposant sur la notion de fichiers et utilisant ou non des mÃĐtadonnÃĐes. Certains nÃĐcessitent d'avoir une ou plusieurs machines dÃĐdiÃĐes aux mÃĐtadonnÃĐes, d'autres permettant d'intÃĐgrer les mÃĐtadonnÃĐes sur les machines stockant les donnÃĐes, ou ÃĐventuellement sur des machines autonomes.
Ceci a un impact sur le minimum de machines requis pour crÃĐer le systÃĻme de fichiers distribuÃĐs, sur la souplesse de retrait et dâajout de machine, sur les performances, la maintenance et la sauvegarde.
Ce tutoriel couvre les systÃĻmes de fichiers suivants :
- GlusterFSÂ ;
- OCFS2 couplÃĐ Ã DRBDÂ ;
- Ceph ;
- Minio.
En rÃĐalitÃĐ, OCFS2 (Oracle Cluster File System) n'est pas un systÃĻme de fichiers distribuÃĐ, mais un systÃĻme de fichiers gÃĐrant la concurrence d'accÃĻs aux fichiers entre plusieurs machines. Cela permet de gÃĐrer les accÃĻs concurrentiels, la rÃĐpartition de charge sur plusieurs machines (deux dans notre cas) sera à gÃĐrer à part. C'est une approche intÃĐressante pour un petit cloud.
Ceph, Ã son niveau le plus bas, va stocker des objets (des couples de clÃĐ/valeur). Un cache d'abstraction nommÃĐe RBD (Rados Block Device) fournira un accÃĻs en mode bloc. Par-dessus cela, CephFS fournira une abstraction permettant l'accÃĻs en mode fichier.
1-1. NFS▲
NFS n'est pas en lui-mÊme un systÃĻme de fichiers rÃĐpartis. Du point de vue utilisateur, vous pouvez le comparer à SMB : c'est un point d'exposition d'un systÃĻme plus bas niveau pouvant lui Être rÃĐparti. Pourquoi en parler ici alors ? Car certains systÃĻmes de fichiers rÃĐpartis comme GlusterFS â que nous allons voir dans le prochain chapitre â implÃĐmentent directement un accÃĻs NFS.
NFS (Network file System) est un protocole historique de partage rÃĐseau sous Unix. Les anciennes versions n'ÃĐtaient pas sÃĐcurisÃĐes.
Sur les anciennes versions de NFS, avec un serveur NFS installÃĐ, pour partager un dossier, il suffisait d'ajouter une entrÃĐe dans le fichier /,etc/exports comme ceci :
/dossier_partage 192.168.1.0/24(rw)pour permettre à toutes les machines du rÃĐseau 192.168.1.0 de se connecter au partage en lecture/ÃĐcriture.
NFS fait un contrÃīle d'accÃĻs au niveau de l'hÃīte, pas du nom d'utilisateur.
L'accÃĻs client se fera soit par la commande mount, soit par une entrÃĐe dans le fichier /,etc/fstab comme ceci :
adresse_ip:/partage /point_de_montage nfs user,noauto 0 0La version 4 a crÃĐÃĐ une rÃĐelle rupture permettant :
- la sÃĐcurisation et le chiffrement des communications (support de Kerberos)Â ;
- dÃĐlÃĐgation de la gestion d'un document en local pour un client ;
- Migration possible d'une machine à l'autre du serveur de façon transparent pour le client.
Les systÃĻmes Linux, Mac OS, Windows (seulement la version Pro, pour les versions home, il faut utiliser un logiciel externe) intÃĻgrent nativement un client NFS.
Mac OS, Linux, la plupart des NAS intÃĻgrent un serveur NFS (bien qu'en gÃĐnÃĐral on va plutÃīt utiliser un partage SMB). Windows Server intÃĻgre ÃĐgalement un rÃīle serveur NFS.
VMWare permet de stocker ses machines virtuelles dans un partage NFS, ce sera par contre moins efficace qu'avec le filesystem VMFS natif, mais permettra par contre de facilement crÃĐer un stockage partagÃĐ.
Un volume GlusterFS, que nous verrons dans le prochain chapitre peut Être montÃĐ en NFS.
1-2. GlusterFS▲
GlusterFS est un systÃĻme de fichiers distribuÃĐ relativement souple. Il vient se greffer sur le systÃĻme de fichiers local existant. Il permet de facilement ÂŦ concatÃĐner Âŧ plusieurs volumes locaux de plusieurs machines en un seul volume. Il possÃĻde plusieurs modes (distribuÃĐs ou non) de fonctionnement. Certains dâentre eux permettent la redondance. C'est un systÃĻme relativement simple à mettre en place et efficace. Voici une explication des modes de fonctionnement.
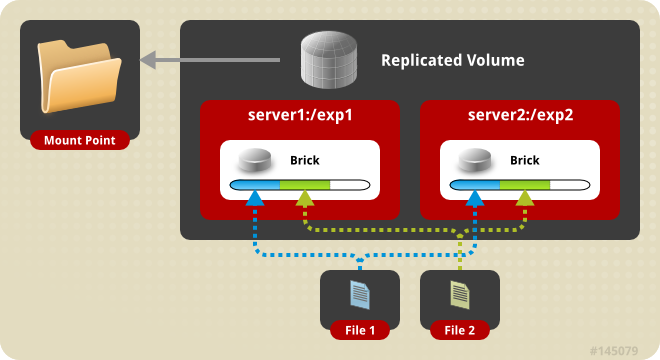
Mode rÃĐpliquÃĐ
Ce mode de fonctionnement rÃĐplique les fichiers sur les diffÃĐrents nÅuds du volume. Il s'agit là uniquement de l'aspect redondance, les fichiers ne sont pas rÃĐpartis sur les diffÃĐrentes machines, ils sont rÃĐpliquÃĐs.
|
|
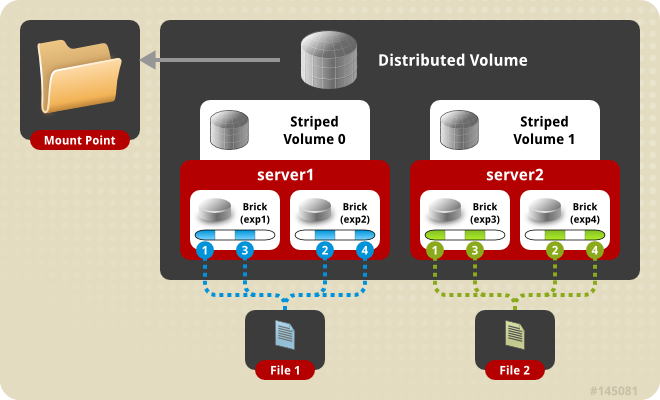
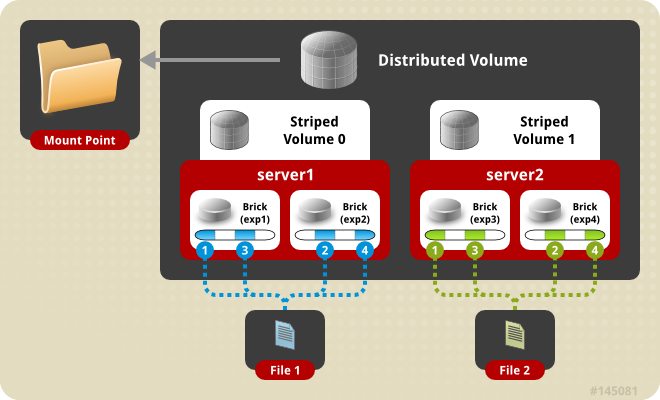
Mode distribuÃĐ
Dans ce mode, les fichiers sont rÃĐpartis entre les diffÃĐrentes machines du volume. Il n'y a pas de redondance. Vous devez donc vous assurer de la sauvegarde des donnÃĐes.
|
|
Mode distribuÃĐ-rÃĐpliquÃĐ
Ce mode cumule la rÃĐpartition et la redondance. Chaque nÅud du volume distribuÃĐ est redondÃĐ sur une autre machine. Il vous faut donc au minimum X machines multipliÃĐ par 2 pour un volume consistant, X reprÃĐsentant le nombre de nÅuds rÃĐpartis.
Autres modes possibles
Volumes strippÃĐs : les fichiers sont ÃĐclatÃĐs en plusieurs morceaux, ceux-ci ÃĐtant rÃĐpartis sur les machines membres du volume. Ce mode pourrait Être comparÃĐ Ã du RAID 0 via le rÃĐseau.
|
|
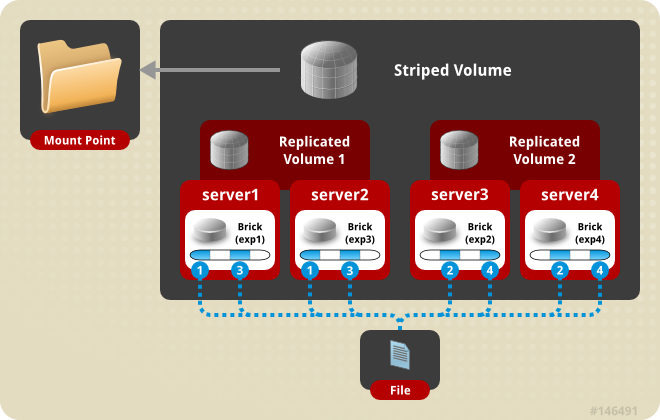
Volumes strippÃĐs distribuÃĐs : les fichiers sont ÃĐclatÃĐs en plusieurs morceaux comme pour les volumes strippÃĐs, mais sont rÃĐpliquÃĐs sur plusieurs machines. Ce mode peut Être comparÃĐ Ã du RAID 0+1 (encapsulation de RAID 0 dans un RAID 1) via le rÃĐseau.
|
|
Volumes dispersÃĐs : les fichiers sont morcelÃĐs sur plusieurs machines avec des fragments supplÃĐmentaires permettant la reconstruction de fichiers suite à une perte de fragments prÃĐsents sur une machine en panne. Ce fonctionnement est comparable à du RAID 5 via le rÃĐseau.
Volumes dispersÃĐs distribuÃĐs : il s'agit de volumes distribuÃĐs rÃĐpliquÃĐs utilisant des sous-volumes dispersÃĐs plutÃīt que rÃĐpliquÃĐs.
GlusterFS utilise la nomenclature suivante :
- pool de machines : machines qui sont appairÃĐes pour gÃĐrer un ou plusieurs volumes en commun ;
- brique : une brique est un point de stockage sur une machine d'un pool. Plusieurs briques font un volume.
1-2-1. Installation de GlusterFS▲
Pour crÃĐer un volume GlusterFS, il faut installer les paquets glusterfs-server et attr :
apt-get install glusterfs-server attrVotre systÃĻme de fichiers doit supporter les attributs ÃĐtendus. C'est le cas pour ext4.
1-2-2. Installation mode rÃĐpliquÃĐ▲
Une fois les paquets GlusterFS installÃĐs sur srv1, nous crÃĐons un dossier à la racine que nous nommons srv1_data et qui accueillera le point de partage.
Nous crÃĐons ensuite le volume que nous nommerons VOLÂ :
gluster volume create VOL srv1:/data_srv1 forceLa commande retourne lâindication suivante :
volume create: VOL: success: please start the volume to access dataOption force : GlusterFS exige ce paramÃĻtre au cas oÃđ le point de montage utilisÃĐ pour le volume est dans la partition principale (ce que GlusterFS ne recommande pas).
La commande gluster volume list permet l'affichage des volumes visibles sur le systÃĻme :
root@srv1:~# gluster volume list
VOL
root@srv1:~#Nous pouvons voir l'ÃĐtat du volume avec la commande gluster volume info :
gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3fa199d1-7e7f-4ec5-985f-abf0f1f18ed4
Status: Created
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Options Reconfigured:
transport.address-family: inet
performance.readdir-ahead: on
nfs.disable: onNous pouvons voir que le volume est en mode distribuÃĐ (distribute), avec une seule brique.
Une fois le volume crÃĐÃĐ, il nous faut l'activer :
root@srv1:~# gluster volume start VOL
volume start: VOL: success.Ã ce stade, le volume est montable, mais nous verrons cela dans le prochain chapitre.
Une fois les paquets installÃĐs sur srv2 et le dossier du point de montage crÃĐÃĐ, nous commençons par effectuer le jumelage GlusterFS de srv2 à srv1 depuis srv1 .
root@srv1:~# gluster peer probe srv2
peer probe : successLa commande suivante permet de voir les machines membres du pool :
root@srv1:~# gluster pool listEt qui donnera un rÃĐsultat comme ceci :
root@srv1:~# gluster pool list
UUID Hostname State
bca2bdf3-ec7e-4e26-8d5e-01584b09d604 srv2 Connected
ffaa8716-0a58-4cea-b01d-70f49bcbe998 localhost ConnectedLes fichiers /,etc/hosts de chaque machine doivent contenir les noms des nÅuds participant aux volumes GlusterFS.
La mÊme commande exÃĐcutÃĐe sur la seconde machine donnera le mÊme rÃĐsultat, les deux lignes seront juste interverties.
Nous ajoutons ensuite la brique de srv2 au volume :
gluster volume add-brick VOL replica 2 srv2:/data_srv2 force
volume add-brick: successNous affichons les informations du volume :
gluster volume info
Volume Name: VOL
Type: Replicate
Volume ID: 3fa199d1-7e7f-4ec5-985f-abf0f1f18ed4
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv2:/data_srv2
Options Reconfigured:
nfs.disable: on
performance.readdir-ahead: on
transport.address-family: inetNous pouvons voir les deux briques et pouvons voir que le type de rÃĐplication est maintenant ÂŦ replicate Âŧ.
Nous aurions pu ÃĐgalement crÃĐer le volume comme ceci à partir du moment oÃđ Gluster ÃĐtait installÃĐ sur les deux postes et les deux machines jumelÃĐes :
root@srv1:~# gluster create volume VOL replica 2 srv1:/data_srv1 srv2:/data_srv1 force
volume create: VOL; success: please start volume to access dataVoici le dÃĐtail des paramÃĻtres passÃĐs à la commande gluster create volume :
- VOLÂ : nom du volume crÃĐÃĐÂ ;Â
- replica : nombre de machines nÃĐcessaires au volume rÃĐpliquÃĐ (deux minimum) ;Â
- srv1:/data_srv1 : srv1 correspond au nom de la machine, /data_srv1 correspond au point de montage/dossier contenant les donnÃĐes du volume. Le nom de la machine et le chemin sont sÃĐparÃĐs par le caractÃĻre : ;
- srv2:/data_srv2: srv2 correspond au nom de la machine, /data_srv2 correspond au point de montage/dossier contenant les donnÃĐes du volume. Le nom de la machine et le chemin sont sÃĐparÃĐs par le caractÃĻre :.
Pour que la rÃĐplication fonctionne, il ne faut pas accÃĐder au contenu directement depuis les dossiers /data_srv1 ou /data_srv2 dans notre exemple, mais depuis un point de montage GlusterFS.
1-2-2-1. Montage d'un volume gluster▲
Pour monter un volume gluster, vous aurez besoin du paquet glusterfs-client. Si vous souhaitez monter un volume gluster sur une machine faisant office de serveur gluster, vous n'en aurez pas besoin, le paquet glusterfs-client ÃĐtant installÃĐ en mÊme temps que glusterfs-server.
Le montage sâeffectue de la mÊme façon que pour tout autre type de volume :
# mount -t glusterfs [nom d'hÃīte ou adresse IP]:/[nom du volume] [point de montage]Ou dans le /etc/fstab sur srv1 par exemple :
srv1:/VOL /mnt glusterfs defaults,_netdev 0 0Il est possible de monter un volume gluster via NFS. Cela n'est pas recommandÃĐ, car la sÃĐcuritÃĐ de NFS, notamment en troisiÃĻme version est rudimentaire.
1-2-2-2. Ajout d'une machine supplÃĐmentaire au pool▲
Dans notre exemple, le serveur supplÃĐmentaire sera nommÃĐ srv3.
Lors de lâajout dâune machine au pool, il ne faut pas oublier dâajouter la nouvelle machine au fichier /,etc/hosts des machines dÃĐjà existantes ou s'assurer que l'entrÃĐe soit prÃĐsente dans les DNS utilisÃĐs.
La commande suivante ajoute srv3 au pool :
root@srv1:~#gluster peer probe srv3Nous ajoutons ensuite la nouvelle machine :
gluster volume add-brick VOL replica 3 srv3:/data_srv3 forceIl faut passer le bon nombre de machines à l'option replica.
Si nous appelons la commande gluster volume info, nous pouvons constater que le nombre de briques est passÃĐ de 1 x 2 = 2 Ã 1 x 3 = 3.
1-2-2-2-1. Mise à jour de srv3▲
Une fois la brique intÃĐgrÃĐe, aucune donnÃĐe n'est automatiquement rÃĐpliquÃĐe dessus. à ce stade, si nous ajoutons un nouveau fichier au volume, une copie sera bien prÃĐsente dans srv3, mais les anciens fichiers ne le seront pas. Pour pallier ceci, il faut lancer la commande suivante :
gluster volume heal VOL full1-2-2-3. Retrait d'une brique▲
Dans notre cas, nous allons retirer srv2 avec la commande suivante :
gluster volume remove-brick VOL replica 2 srv2:/data_srv2 forceLa commande demande confirmation avant de procÃĐder au retrait.
replica doit Être ÃĐgal au nombre final de briques aprÃĻs opÃĐration.
Dans notre cas oÃđ les volumes sont rÃĐpliquÃĐs, il est possible de diminuer le nombre de volumes jusquâà nâen garder plus quâun. Le volume dans ce cas passera en mode distribuÃĐ.
Le retrait de la brique du volume ne supprime pas les donnÃĐes de celle-ci, mais il n'y a plus aucun lien entre celles-ci et le volume. Il ne sera pas possible de rÃĐintÃĐgrer la brique telle quelle.
Si vous souhaitez retirer la machine du pool :
gluster peer detach srv21-2-3. Test de mise en panne, simulation perte de srv1▲
L'arrÊt de srv1 ne provoque aucune erreur. Comme nous avons appairÃĐ srv2 à srv1, nous pouvons voir l'ÃĐtat de la connexion (et donc sa perte) avec la commande :
root@srv1:~# gluster peer status
Number of Peers: 1
Hostname: srv1
Uuid: c0c487b3-1135-41c7-b160-b8a061c10e9d
State: Peer in Cluster (Disconnected)Si vous souhaitez garder l'adresse IP de la machine perdue, la reconnexion est plus complexe.
1-2-3-1. Remplacement avec une nouvelle adresse IP▲
Nous appairons le nouveau serveur :
root@srv2:~# gluster peer probe srv1Nous remplaçons ensuite la brique :
root@srv2:~# gluster volume replace-brick VOL srv1:/data_srv1 [nouvelle ip/hote]/data commit forcePour que les machines se synchronisent, il faut ensuite lancer la commande :
gluster volume heal VOL full1-2-3-2. Remplacement en gardant la mÊme adresse IP▲
Il faut d'abord retirer la brique dÃĐfectueuse :
root@srv2:~# gluster volume remove-brick VOL srv1:/data_srv1 force
Removing brick(s) can result in data loss. Do you want to continue ? (y/n) y
volume remove brick commit force:successPuis :
root@srv2:~# gluster peer detach srv1
peer detach: successà ce stade, et comme dÃĐjà vu, le volume ne contenant plus qu'une seule brique, passe en mode distribuÃĐ.
Une fois le nouveau serveur prÃĐparÃĐ, nous le rÃĐappairons :
root@srv2:~# gluster peer probe srv1Nous ajoutons la nouvelle brique :
root@srv2:~# gluster volume add-brick VOL replica2 srv1:/data_srv1 forceNous resynchronisons le volume :
gluster volume heal VOL full
Launching heal operation to perform full self heal on volume VOL has been successful
Use heal info commands to check statusComme indiquÃĐ, nous pouvons voir le rÃĐsultat avec la commande :
gluster volume heal infoSi vous rencontrez des difficultÃĐs, consultez le chapitre 1.3.5.1Ajout dâune troisiÃĻme machine pour la sauvegarde.
1-2-4. Installation en mode distribuÃĐ▲
Certaines notions sont identiques ou de simples variantes du mode rÃĐpliquÃĐ. Il est important pour la suite d'avoir lu le chapitre prÃĐcÃĐdent.
Nous prÃĐparons une machine srv1 qui contiendra le fichier fichier1.txt dans /data_srv1.
Nous y crÃĐons un volume avec une brique unique.
gluster volume create VOL srv1:/data_srv1 force
volume create: VOL: success: please start volume to access dataNous pouvons voir l'ÃĐtat du volume avec la commande gluster volume info :
root@srv1:~# gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3f0a379a-921a-4c63-a5cc-7a62c3c39d19
Status: Created
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1Nous pouvons constater que le volume est en mode distribuÃĐ (distribute)
DÃĐmarrons ensuite le volume :
root@srv1:~# gluster volume start VOLNous prÃĐparons ensuite un serveur srv2 avec le fichier /data_srv2/fichier2.txt. Il nous faut appairer la nouvelle machine :
root@srv1:~# gluster peer probe srv2Puis ajouter la nouvelle brique :
root@srv1:~# gluster volume add-brick VOL srv2:/data_srv2
volume add-brick: successNous pouvons voir le nouvel ÃĐtat du volume :
root@srv1:~# gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3f0a379a-921a-4c63-a5cc-7a62c3c39d19
Status: Started
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv2:/data_srv2Si nous montons le volume, nous pourrons voir les deux fichiers fichier1.txt et fichier2.txt. L'arrÊt d'une des deux machines fera disparaÃŪtre les fichiers prÃĐsents dans le nÅud coupÃĐ. Le premier accÃĻs sera lent, gluster cherchant la machine manquante. Le volume continue de fonctionner, il reste possible d'ajouter des fichiers. Le redÃĐmarrage de la machine manquante fera instantanÃĐment rÃĐapparaÃŪtre les fichiers inaccessibles.
CrÃĐez quelques fichiers pour tester le comportement. J'ai crÃĐÃĐ plusieurs fichiers nommÃĐs fichier3.txt, fichier4.txt, etc. Tous restant dans /data-srv1.
Gluster gÃĻre cela lui-mÊme et du point de vue extÃĐrieur, cela n'a pas d'importance pour l'accÃĻs. Lisez cette partie de la documentation pour plus d'informations.
Il est possible de changer la rÃĐpartition avec la commande rebalance :
gluster volume rebalance VOL startSelon le volume de donnÃĐes à traiter, la rÃĐpartition peut prendre du temps. Il est possible de voir l'ÃĐtat de celle-ci via la commande :
gluster volume rebalance VOL statusJ'ai pu constater que certains fichiers apparaissent en doublon dans les dossiers contenant les briques, ceux-ci restant uniques dans le point de montage GlusterFS. Je prÃĐsume que gluster est suffisamment intelligent pour les conserver tant qu'il y a de la place.
Rappel : si vous insÃĐrez un fichier dans un dossier faisant partie d'un volume gluster sans passer par le point de montage gluster, celui-ci nâapparaÃŪtra pas dans le volume et ne sera ni rÃĐpliquÃĐ, ni distribuÃĐ.
1-2-5. Test du mode distribuÃĐ-rÃĐpliquÃĐ▲
Pour ce mode, je vais repartir sur la configuration prÃĐcÃĐdente : deux machines en mode distribuÃĐ que je vais passer en mode distribuÃĐ-rÃĐpliquÃĐ.
Je vais rajouter deux machines supplÃĐmentaires aux deux machines dÃĐjà prÃĐsentes de façon à ce que chacune soit rÃĐpliquÃĐe.
Une fois les deux serveurs supplÃĐmentaires prÃĐparÃĐs et appairÃĐs, je les intÃĻgre au volume :
gluster peer probe srv3
gluster peer probe srv4gluster volume add-brick VOL replica 2 srv3:/data_srv3 srv4:/data_srv4 forceNous obtenons le rÃĐsultat suivant :
Volume Name: VOL
Type: Distributed-Replicate
Volume ID: 8f4d1305-7f28-41eb-bc76-85132c009c51
Status: Started
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv3:/data_srv3
Brick3: srv2:/data_srv2
Brick4: srv4:/data_srv4L'ajout d'un fichier dans le point de montage du volume GlusterFS, point de montage depuis srv1 et donc crÃĐation du fichier depuis srv1 va gÃĐnÃĐrer l'ajout de celui-ci dans /data_srv2 et /data_srv4. Nous avons donc bien la rÃĐplication ainsi que la distribution rÃĐpartie.
Seuls les nouveaux fichiers ou fichiers modifiÃĐs aprÃĻs l'ajout des briques bÃĐnÃĐficieront de la rÃĐplication.
Pour que tous les fichiers soient rÃĐpliquÃĐs, il faudra exÃĐcuter la commande rebalance comme vu prÃĐcÃĐdemment.
gluster volume rebalance VOL startLa rÃĐpartition devient donc :
- srv1 : fichier1.txt, fichier2.txt ;
- srv2 : fichier2.txt, fichier3.txt ;
- srv3 : fichier2.txt ;
- srv4 : fichier2.txt, fichier3.txt ;
Chaque fichier est donc bien rÃĐpliquÃĐ.
1-2-5-1. Simulation de perte de srv2▲
La manipulation la plus simple est de prÃĐparer une nouvelle machine, de lui affecter une nouvelle adresse IP, de l'appairer et d'utiliser replace-brick comme vu prÃĐcÃĐdemment.
Si vous souhaitez garder la mÊme IP, il va falloir effectuer plusieurs opÃĐrations.
La difficultÃĐ ici est qu'un nouveau serveur n'aura pas le mÊme UUID. Il y aura donc des manipulations supplÃĐmentaires à effectuer une fois le serveur prÃĐparÃĐ.
Il va nous falloir rÃĐcupÃĐrer l'ancien UUID de srv2Â :
root@srv1:~# grep -r uuid= /var/lib/glusterd/peers/* >fichier.txtUniquement valable si votre dossier ne contient qu'un seul fichier /var/lib/glusterd/peers/. Si ce n'est pas le cas, il faut identifier celui-ci et exÃĐcuter :
grep uuid= /var/lib/glusterd/peers/[nom du fichier contenant hostname=srv1] >fichier.txt
Nous transfÃĐrerons ensuite cet UUID sur le nouvel srv2. Nous insÃĐrons ensuite cet UUID dans /var/lib/glusterd/glustered :
cat fichier.txt >>/var/lib/glusterd/glusterd.infoNous ÃĐditons le fichier afin de fixer l'UUID, puis redÃĐmarrons le service :
/etc/init.d/glusterfs-server restartNous appairons ensuite le serveur :
root@srv2:~# gluster peer probe srv1Nous redÃĐmarrons le service en appelant la commande gluster pool list, vous verrez les deux machines connectÃĐes.
Il faut ensuite synchroniser les volumes.
Depuis srv2, la commande gluster volume status vous retournera :
No volumes presentNous synchronisons les volumes avec la commande ;
root@srv1:~# gluster volume sync srv2 all
sync volume may data inaccessible while the sync is in progress. Do you want to continue ? (y/n)
volume sync success.Ã ce stade, les donnÃĐes ne sont pas encore synchronisÃĐes.
Mises à jour des mÃĐtadonnÃĐes
Il va nous falloir mettre à jour les mÃĐtadonnÃĐes sur le nouveau serveur depuis un serveur actif.
root@srv1:~# getfattr -n trusted.glusterfs.volume-id /data_srv1
getfattr:suppression des ÂŦ / Âŧen tÊte des chemins absolus
# file: data_srv2/
trusted.glusterfs.volume-id=0s8VVsv3xRTa6G41mE+5E1dA==Il va falloir appliquer le volume id sur srv2 avec la commande :
setfattr -n trusted.glusterfs.volume-id -v '0s8VVsv3xRTa6G41mE+5E1dA==' /data_srv2Nous redÃĐmarrons ensuite le service et depuis srv1, nous exÃĐcutons :
gluster volume heal VOL full1-2-6. Sauvegarder/restaurer▲
Il me parait indispensable d'avoir une sauvegarde hors ligne mÊme en cas de systÃĻme rÃĐpliquÃĐ, ceci afin de se protÃĐger de cryptolocker ou dâun effacement involontaire de fichiers. L'idÃĐal sera une sauvegarde en ligne sur la mÊme infrastructure, afin d'avoir une sauvegarde/restauration rÃĐguliÃĻre rapide, doublÃĐ par une sauvegarde hors ligne moins frÃĐquente.
1-2-7. SÃĐcuritÃĐ▲
Les serveurs faisant partie d'un pool gluster, ils se reconnaissent via leur UUID. Pour qu'un serveur fasse partie d'un pool, il doit Être intÃĐgrÃĐ par un serveur du pool (c'est la commande gluster peer probe que nous avons dÃĐjà vue).
Par dÃĐfaut, n'importe quel client peut se connecter à un volume gluster. Il est possible de restreindre l'accÃĻs à certaines IP via la commande :
gluster volume set VOL auth.allow [adresse IP 1],[adresse IP 2]Par dÃĐfaut, le dialogue s'effectue en clair. Il est possible d'ÃĐtablir un dialogue SSL/TLS (documentation ici), celui-ci gÃĐrant l'authentification et le cryptage, mais pas l'autorisation. La sÃĐcurisation peut bien sÃŧr se faire via un tunnel VPN, l'authentification et le cryptage ÃĐtant alors dÃĐlÃĐguÃĐ au tunnel VPN.
Comme il n'y a pas de login/mot de passe, il ne faut pas exposer directement un point de montage gluster aux utilisateurs. Par exemple, ce point de montage peut-Être partagÃĐ en SMB. C'est le serveur SMB (point d'entrÃĐe exposÃĐ) qui sâoccupera alors des autorisations d'accÃĻs.
1-3. DRBD/OCFS2▲
Nous allons ici cumuler l'utilisation de DRBD avec OCFS, DRBD s'occupant de la rÃĐplication, OCFS de l'accÃĻs concurrentiel.
1-3-1. DRBD▲
1-3-1-1. Qu'est-ce que DRBDÂ ?▲
DRBD : Distributed Replicated Block Device permet la rÃĐplication de pÃĐriphÃĐriques bloc entre serveurs via le rÃĐseau. Il peut Être assimilÃĐ Ã du RAID 1 over IP.
|
|
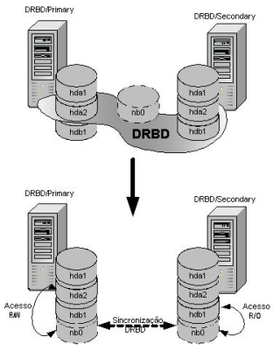
Par dÃĐfaut, DRBD utilise la notion de primaire/secondaire. Un systÃĻme de fichiers ne peut Être montÃĐ que depuis une machine primaire. La machine primaire transmet les modifications à la machine secondaire. Une machine en mode secondaire ne peut pas Être utilisÃĐe de façon à garder la cohÃĐrence du cache.
Nous utiliserons un mode permettant d'avoir deux machines primaires et donc pouvoir faire des lectures/ÃĐcritures depuis les deux nÅuds.
1-3-2. Installation de DRBD▲
La version utilisÃĐe ici sera la version 8.
L'installation se fait simplement par :
apt-get install drbd-utilsIl va falloir effectuer la configuration du nÅud primaire et du nÅud secondaire. Nous devons donc prÃĐparer un fichier de configuration en consÃĐquence.
DRBD va utiliser une partition en tant que pÃĐriphÃĐrique bloc sur chaque nÅud.
Une partition doit Être mise à disposition. Utiliser une partition avec DRBD va ÃĐcraser son contenu.
Le fichier de configuration suivant, nommÃĐ r0.res et placÃĐ dans /,etc/drbd.d permet dâutiliser les nÅuds accessibles en 192.168.8.1 et 192.168.8.2. Sur chacun d'eux, nous utiliserons la partition /dev/sdb1. Ce fichier sera à adapter à votre cas.
resource r0 {
syncer {
rate 100M;
}
on srv1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.1:7789;
meta-disk internal;
}
on srv2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.2:7789;
meta-disk internal;
}
}Un fichier de dÃĐfinition de ressource DRBD doit avoir l'extension .res
Les noms de machines utilisÃĐs avec la directive ÂŦ on Âŧ
doivent correspondre aux noms des machines retournÃĐs par la commande hostname.
Ce fichier devra Être recopiÃĐ sur le second nÅud.
Le fichier est relativement simple à comprendre. Nous crÃĐons un volume DRBD accessible depuis /dev/drbd0 sur chaque nÅud.
Nous crÃĐons ensuite le volume sur le nÅud primaire :
# drbdadm create-md r0
initialising activiy log
NOT initialializing bitrmap
Writing meta data âĶ
New dbrd meta data block successfully created.Nous activons ensuite celui-ci :
# drbdadm up r0Nous pouvons observer le rÃĐsultat avec la commande drbd-overview :
# drbd-overview
0:r0/0 WFConnexion Secondary/Unknown Inconsistent/DUnknownIl faut effectuer ces commandes sur les deux nÅuds. Pour le second nÅud, la commande drbd-overview donne :
0:r0/0 Connected Secondary/Primary Inconsistent/ InconsistentNous voyons que la connexion est effectuÃĐe, mais que le ÂŦÂ RAIDÂ Âŧ DRBD est inconsistant.
Nous lançons ensuite la synchronisation uniquement depuis le poste maitre (192.168.8.1 ou srv1), nous passons ÃĐgalement le nÅud en primaire :
drbdadm -- --overwrite-data-of-peer primary r0Nous pouvons voir l'ÃĐvolution de la synchronisation depuis le fichier /proc/drbd ou depuis la commande drbd-overview :
version: 8.4.3 (api:1/proto:86-101)
srcversion: 6681A7B41C129CD2CE0624F
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:417288 nr:0 dw:0 dr:418200 al:0 bm:25 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:7970004
[>...................] sync'ed: 5.1% (7780/8188)Mfinish: 0:05:05 speed: 26,080 (26,080) K/secUne fois la synchronisation terminÃĐe, nous allons passer le second nÅud en primaire. Pour cela, nous ajoutons les lignes suivantes dans le bloc ressources du fichier de configuration r0Â :
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
}
startup {
become-primary-on both;
}Le fichier devient :
resource r0 {
syncer {
rate 100M;
}
net {
allow-two-primaries yes;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
}
startup {
become-primary-on both;
}
on srv1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.1:7789:
meta-disk internal;
}
on srv2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.2:7789:
meta-disk internal;
}
}En dÃĐtails, voici les nouvelles fonctions utilisÃĐes :
- allow-two-primaries : permet d'utiliser deux nÅuds en mode primaire ;
- after-sb-0pri discard-zero-changes : en cas de split-brain, et que les deux nÅuds sont considÃĐrÃĐs comme primaires, DRBD va prendre les modifications les plus rÃĐcentes et les appliquer à l'autre nÅud ;
- after-sb-1pri discard-secondary : en cas de split-brain avec un nÅud primaire et un secondaire, le primaire ÃĐcrasera les modifications sur le secondaire ;
- after-sb-2pri disconnect (non utilisÃĐ) : en cas de split-brain, DRBD dÃĐconnecte les volumes et le rÃĐglage du problÃĻme (et la dÃĐcision du nÅud oÃđ il faut sacrifier les diffÃĐrences) doit Être fait manuellement.
Pensez à faire une copie du fichier de configuration avant modification pour pouvoir revenir à la situation initiale en cas de problÃĻme.
Nous recopions le fichier sur le second nÅud et redÃĐmarrons le service DRBD sur les deux machines.
Nous pouvons vÃĐrifier l'ÃĐtat sur les deux serveurs avec :
# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
srcversion: 1A9F77B1CA5FF92235C2213
0: cs:Connected ro:Primary/Primary ds:UpToDate/Diskless C r-----
ns:912 nr:0 dw:0 dr:1824 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:8387292Rappel : Il n'est pas possible de monter un systÃĻme de fichiers dans un volume DRBD en mode secondaire.
1-3-2-1. SÃĐcuritÃĐ de DRBD▲
Il est possible de sÃĐcuriser les dialogues DRBD en ajoutant les ÃĐlÃĐments suivant dans le fichier de configuration :
net {
cram-hmac-alg "sha1";
secret "le mot de passe";
}Un transfert via une connexion sÃĐcurisÃĐe entre les nÅuds hors DRBD peut aussi Être utilisÃĐ. (interconnexion via cartes rÃĐseau dÃĐdiÃĐes hors rÃĐseau normal, VPN).
1-3-2-2. Surveillance des volumes DRBD▲
DRBD est fourni avec un systÃĻme de handlers et des scripts pour gÃĐrer les problÃĻmes. Par exemple, la mise en place dâune notification par mail lors dâun split-brain sâeffectue en ajoutant ce qui suit dans la section resources :
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh <adresse>";
...
}Je vous invite à regarder les diffÃĐrents scripts à disposition dans /usr/lib/drbd.
1-3-2-3. Tests▲
Une fois la synchronisation effectuÃĐe, nous crÃĐons ensuite un systÃĻme de fichiers sur /dev/drbd0Â :
mkfs.ext4 /dev/drbd0Quelle que soit la machine, le systÃĻme de fichiers sera prÃĐsent sur l'autre, le volume DRBD ÃĐtant rÃĐpliquÃĐ.
Nous y crÃĐons un fichier de test fichier1.txt aprÃĻs montage du volume DRBD dans un point de montage.
Nous montons ensuite /dev/drbd0 sur la seconde machine (srv2), nous voyons bien le fichier fichier1.txt.
Nous ajoutons un fichier fichier2.txt depuis srv2, celui-ci nâapparaÃŪt pas sur srv1.
Nous dÃĐmontons et remontons le volume sur srv1, AprÃĻs remontage, nous voyons bien le second fichier.
Explications
DRBD travaille au niveau bloc et non au niveau du systÃĻme de fichiers. Nous pouvons l'utiliser tel quel en tant que sauvegarde, mais pas pour un double montage. Le monter simultanÃĐment risque de provoquer une inconsistance au niveau du systÃĻme de fichiers.
Pour pallier ceci, nous allons utiliser OCFS2, un systÃĻme de fichiers permettant les accÃĻs concurrents.
1-3-3. OCFS2▲
1-3-3-1. Qu'est-ce qu'OCFS2Â ?▲
OCFS2 (Oracle Cluster File System) est un systÃĻme de fichiers sous licence GPL qui permet l'accÃĻs concurrent à des fichiers, c'est-à -dire un accÃĻs simultanÃĐ possible en lecture/ÃĐcriture à un fichier sans risque dâinconsistance. Ceci nous permettra de rÃĐsoudre le problÃĻme vu dans le chapitre prÃĐcÃĐdent.
1-3-3-2. Installation et paramÃĐtrage d'OCFS2▲
Pour installer OCFS2, il faut installer le paquet comme ci-dessous :
apt-get install ocfs2-toolsNous crÃĐons le systÃĻme de fichiers ocfs sur le volume DRBDÂ :
mkfs -t ocfs2 -L MYCLOUD /dev/drbd0Avec en options :
- -LÂ : le nom du volume OCFS2.
La configuration s'effectue via les commandes suivantes.
CrÃĐation du cluster que nous nommerons ÂŦÂ MYCLOUDÂ ÂŧÂ :
o2cb add-cluster MYCLOUDAjout des nÅuds :
o2cb add-node MYCLOUD --ip 192.168.8.1 --port 7777 --number 0 srv1
o2cb add-node MYCLOUD --ip 192.168.8.2 --port 7777 --number 1 srv2Ce qui nous donnera La configuration suivante dans le fichier /etc/ocfs2/cluster.conf :
cluster:
heartbeat_mode = local
node_count = 2
name = MYCLOUD
node:
number = 0
cluster = MYCLOUD
ip_port = 7777
ip_address = 192.168.8.1
name = srv1
node:
number = 1
cluster = MYCLOUD
ip_port = 7777
ip_address = 192.168.8.2
name = srv2Afin de modifier la configuration au dÃĐmarrage, nous lançons :
dpkg-reconfigure ocfs2-tools|
|
|
|
AprÃĻs un redÃĐmarrage de la machine, ou plus simplement des services o2cb et ocfs2, il suffit de monter le volume :
mount -t ocfs2 /dev/drbd0 /dataou grÃĒce au fichier fstab :
/dev/drbd0 /data ocfs2 _netdev 0 0Pour avoir accÃĻs aux donnÃĐes sur la seconde machine, il faudra effectuer les mÊmes opÃĐrations aprÃĻs voir copiÃĐ le fichier de configuration /etc/ocfs2/cluster.conf.
Les tests depuis les deux postes sont fonctionnels. Le fichier fichier1.txt crÃĐÃĐ depuis srv1 est visible sur srv2, et le fichier fichier2.txt crÃĐÃĐ depuis srv2 est visible dans le dossier /data de srv1.
Le montage automatique au redÃĐmarrage ne semble pas fonctionnel. Peut-Être un problÃĻme de configuration.
1-3-4. Couplage DRBD/OCFS2Â : Simulation de panne▲
Pour simuler notre panne, nous allons arrÊter srv2. AprÃĻs quelques secondes, lâerreur suivante apparaÃŪt sur la console de srv1 :
drbd r0: PingAck did not arrive in timeDe plus, la commande drbd-overview retournera un message similaire à  :
0:r0/0 WFConnection Primary/Unknown UpToDate/DUnknown /data ocfs2 8.0G 151M 7.9G 2%Le premier accÃĻs à la commande drbd-overview va Être long.
L'arrÊt de srv2 ne perturbe pas le volume /data dans srv1, sauf si celui-ci est redÃĐmarrÃĐ.
Au redÃĐmarrage de srv2, j'ai le message suivant dans la console :
A start job is running for dev-drbd0.device (36s/1mn 30s)Comme nous l'avons dÃĐjà vu, nous ne pouvons pas monter un volume DRBD en mode Secondary. Le volume OCFS2 n'est pas montable. Une tentative de montage avec mount -a donnera le message suivant :
mount.ocfs2: Device name specified was not found while opening device /dev/drbd0Une fois le systÃĻme dÃĐmarrÃĐ, le volume n'est pas disponible. En exÃĐcutant la commande drbd-overview, nous pouvons voir :
0:r0/0 Unconfigured . .La commande :
drbdadm up r0Nous retournera :
Marked additional 12 MB as out-of-sync based on AL.Et le rappel de drbd-overview nous donnera :
0:r0/0 Connected Secondary/Primary UpToDate/UpToDateJe redÃĐmarre DRBD sur les deux postes avec la commande service drbd restart.
Les deux postes repassent en mode Primary.
Il est alors possible de remonter le volume OCFS2 sur srv2 avec la commande mount -a (et sur srv1).
Nous avons donc une mÃĐthode pour redÃĐmarrer en mode dÃĐgradÃĐ.
1-3-5. Couplage DRBD/OCFS2Â : redÃĐmarrage des deux serveurs▲
Le redÃĐmarrage des deux serveurs simultanÃĐment nous donnera une situation de split-brain. La commande drbd-overview nous donnera ÂŦ Unconfigured Âŧ sur les deux postes.
Pour avoir accÃĻs au volume sur un des postes, il faudra lancer les commandes suivantes :
- drbdadm up r0Â ;
- drbdadm primary r0Â ;
-
mount -a.
Sur le second poste :
- drbdadm up r0.
à ce stade, le volume DRBD sera consistant avec le mode Primary sur le premier poste, et le mode Secondary sur le second. Un mount -a sur le second nÅud rÃĐactivera le volume OCFS2.
En cas de perte complÃĻte d'un nÅud (et non plus un simple arrÊt), le volume sera indisponible sur le second nÅud tant que la synchronisation n'a pas ÃĐtÃĐ refaite. Une fois celle-ci refaite, il sera possible de passer le nÅud en Primary et ensuite de monter le volume OCFS2.
1-3-5-1. Ajout dâune troisiÃĻme machine pour la sauvegarde▲
La version 9 de DRBD permet dâavoir jusqu'à 16 machines. Ce chapitre repose sur la version 8.4 et permet d'empiler deux volumes DRBD. Ce systÃĻme est appelÃĐ stacked et correspond à cette architecture :
|
|
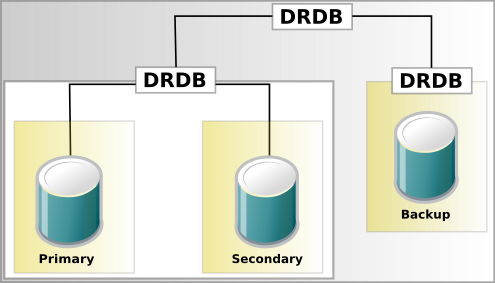
Nous allons donc mettre en place un serveur srv3 comme serveur de sauvegarde.
Nous ajoutons la nouvelle ressource imbriquÃĐe dans /etc/drbd.d/r0.res à la suite de r0 :
resource r1 {
stacked-on-top-of r0 {
device /dev/drbd10;
address 192.168.8.4:7788;
}
on srv3 {
device /dev/drbd10;
disk /dev/sdb1;
address 192.168.1.3:7788;
meta-disk internal;
}
}Vous remarquerez que nous utilisons un port diffÃĐrent, chaque ressource dialoguant sur son propre port.
Nous dÃĐmontons ensuite le volume sur les deux machines. La commande drbd-overview vous permet de voir si le volume est montÃĐÂ :
0:0/r0 Connected Primary/Primary UpToDate/ UpToDate /data ocfs2 63M 13m 51m 20%
10:r1/0 ^^0 Unconfigured .Voici le retour lorsque le volume est dÃĐmontÃĐÂ :
0:0/r0 Connected Primary/Primary UpToDate/ UpToDate 11-dev of: 10 r1/0
10:r1/0 ^^0 Unconfigured .Nous pouvons voir que le volume r1 n'est pas configurÃĐ.
Pour cela il nous faut exÃĐcuter les commandes :
drbdadm --stacked create-md r1
md_offset 66015232
al_offset 65982464
bm_offset 65978368
Found some data
==> This might destroy existing data! <==
Do you want to proceeed?
[need to type 'yes' to confirm]Il faudra confirmer en tapant ÂŦ yes Âŧ, puis vous aurez un message de ce type en retour :
Initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfull created.Nous tapons ensuite la commande :
drbdadm --stacked up r1à ce stade, il n'est pas possible de monter le volume.
Comme prÃĐcisÃĐ par le message lors de la commande, effectuer ceci sur un volume existant peut provoquer une perte de donnÃĐes.
Nous copions ensuite la configuration sur srv3, puis crÃĐons le volume DRBD dessus :
root@srv3:~# drbdadm create-md r1
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.Puis :
drbdadm up r1Nous invalidons ensuite le contenu de la machine par :
drbdadm invalidate r1La synchronisation de srv3 se dÃĐclenche immÃĐdiatement.
Nous activons le mode primaire sur srv1Â :
root@srv3:~# drbdadm âstacked primary r1il faut ensuite monter le volume avec /dev/drbd10 au lieu de /dev/drbd0.
/dev/drbd10 sera le nom de device utilisÃĐ pour un volume stacked.
En cas de perte d'une des machines, il faudra appliquer la mÃĐthode vue au chapitre 1.3.5.1Ajout dâune troisiÃĻme machine pour la sauvegarde.
1-3-5-2. Perte de liaison entre deux machines : split-brain▲
Si les deux machines croient que l'autre ne fonctionne plus, vous vous trouverez dans une situation nommÃĐe split brain. Dans cette situation, les deux machines passeront en mode standalone avec le statut inconnu :
0:r0/0 StandAlone Primary/Unknown /data ocfs2 127M 17M 1111M 14%Pour rÃĐgler ce problÃĻme, vous devrez en considÃĐrer une comme ÂŦ sacrifiable Âŧ et la resynchroniser entiÃĻrement à partir de l'autre. Si la situation a perdurÃĐ un moment, et qu'il y a des diffÃĐrences entre les deux, les diffÃĐrences de la machine sacrifiÃĐe seront perdues.
Nous commençons par effectuer un redÃĐmarrage des deux machines. à ce stade aucune des deux ne devrait Être connectÃĐe au volume OCFS2.
Vous pouvez voir un peu plus haut que la commande drbd-overview indique des informations sur le volume montÃĐ.
Nous pouvons voir que le volume est montÃĐ dans /data. Si aucun volume n'est montÃĐ, vous ne verrez que l'information Primary/Unknown (ou Secundary/Unknown).
Nous allons basculer la machine ÂŦ victime Âŧ en secondaire si nÃĐcessaire.
Avant ce redÃĐmarrage, nous commentons dans le fichier /etc/drbd.d/r0 les lignes concernant la gestion du double primaire.
AprÃĻs redÃĐmarrage. Avec drbd-overview, vous devriez avoir quelque chose comme :
0:r0/0 WFConnection Secondary/Unknown UpToDate/UnknownNous allons ensuite dÃĐclarer une des machines comme obsolÃĻte, commande à effectuer sur la machine concernÃĐe :
drbdadm â --discard-my-data connect r0La resynchronisation se dÃĐclenche. Pendant celle-ci, vous pouvez basculer la machine servant de source en primaire et remonter le volume OCFS.
Une fois la synchronisation terminÃĐe, nous dÃĐcommentons les lignes concernant l'utilisation de deux machines primaires et redÃĐmarrons le service sur les machines une à une.
1-3-6. DRBD 9▲
DRBD 9 permet d'utiliser LVM comme conteneur de volume. Il permet aussi d'avoir jusqu'à 16 nÅuds par ressource sans devoir recourir à l'empilement comme vu avec la version 8.4. La version fournie avec Debian 9 ÃĐtant la 8,4, il va falloir compiler :
- le module noyau ;
- les outils drbd (drbd-utils).
Avant de commencer, nous installerons LVM (apt-get install lvm2).
1-3-6-1. Installation du module noyau :▲
Commençons par tÃĐlÃĐcharger les sources du module :
wget https://www.linbit.com/downloads/drbd/9.0/drbd-9.0.19-1.tar.gzJe n'ai pas pris la derniÃĻre version pour des questions de soucis de compilation sur Debian 9 utilisÃĐ (Debian 9 ÃĐtant une ancienne version maintenant).
Les liens de tÃĐlÃĐchargements peuvent changer avec le temps et devront donc Être adaptÃĐs
DÃĐcompression :
gunzip drbd-9.0.19-1.tar.gzDÃĐsarchivage :
tar -xvf drbd-9.0.19-1.tarLa compilation se fera avec la commande make dans le dossier dÃĐcompressÃĐ. Les prÃĐrequis sont make bien sÃŧr, et les en-tÊtes de votre noyau (installable avec la commande apt-get install linux-headers-$(uname -r)).
Une fois la compilation effectuÃĐe, l'installation se fera par :
make install1-3-6-2. Installation des outils ▲
wget https://www.linbit.com/downloads/drbd/utils/drbd-utils-9.13.1.tar.gz
gunzip drbd-utils-9.13.1.tar.gz
tar -xvf drbd-utils-9.13.1.tarLes prÃĐrequis avant compilation seront gcc, flex, xlstproc (pour la documentation). La compilation se fera ensuite par :
./configure
makeà la fin de la compilation, j'ai eu le message d'erreur suivant :
Makefile:108 : la recette pour la cible ÂŦ doc Âŧ a ÃĐchouÃĐCela nâempÊche pas le make install.
Nous faisons ensuite l'installation :
make install1-3-6-3. PrÃĐparation du volume LVM▲
Nous commençons par prÃĐparer la partition à l'usage de LVM (dans notre cas sdb1) :
pvcreate /dev/sdb1Nous crÃĐons ensuite un volume Group que nous appellerons vg01Â :
vgcreate vg01 /dev/sdb1Et crÃĐons enfin le volume logique lv01 (volume de 1900Â Mo sur un disque de 2Â Go pour l'essai)Â :
lvcreate -L 1900 -n lv01 vg01Nous crÃĐons ensuite un fichier de configuration dans un premier temps avec une machine unique :
resource r0 {
protocol C;
on srv1 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.201:7789;
meta-disk internal;
node-id 0;
}
}Comme nous utilisons une version compilÃĐe de DRBD, les fichiers de configuration devront Être placÃĐs dans /usr/local/,etc/drbd.d au lieu de /,etc/drbd.d.
Remarquez la prÃĐsence de l'option node-id 0;. Cette option, apparue avec DRBD 9 permet de numÃĐroter chaque nÅud participant au cluster.
La procÃĐdure sera ensuite la mÊme que pour la version 8.4.
CrÃĐation des mÃĐtadonnÃĐes sur le volume :
drbdadm create-md r0Activation du volume :
drbdadm up r0à ce stade, nous pouvons voir l'ÃĐtat du volume avec la commande drbdadm status, qui remplace drbd-overview :
~# drbdadm status
r0 role:Secondary
disk:InconsistentNous allons ensuite passer celui-ci en primaire. La syntaxe a ÃĐtÃĐ simplifiÃĐe par rapport aux versions prÃĐcÃĐdentes :
drbdadm primary r0 --forceRÃĐsultat de drbdadm status :
# drbdadm status
r0 role:Primary
disk:UpToDateNous modifions le fichier de configuration pour intÃĐgrer la seconde machine :
resource r0 {
protocol C;
on srv1 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.201:7789;
meta-disk internal;
node-id 0;
}
on srv2 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.202:7789;
meta-disk internal;
node-id 1;
}
}Rappel : la valeur node-id doit Être unique à chaque nÅud.
Une fois le fichier mis à jour, la commande suivante permet de prendre en compte les changements :
drbdadm adjust r0La commande drbdadm status nous montre l'attente de connexion pour srv2 non encore prÃĐparÃĐ.
~# drbdadm status
r0 role:Primary
disk:UpToDate
srv2 connection:ConnectingReste à prÃĐparer srv2. La copie des dossiers source depuis srv1 permettra d'installer le module noyau DRBD avec make install sans devoir recompiler (le module .ko compilÃĐ sur srv1 ÃĐtant dans le dossier des sources copiÃĐ). Pour les outils, il faudra rÃĐexecuter ./configure, puis make et make install. Restera à copier le fichier de configuration.
Une fois le volume LVM crÃĐÃĐ, les mÃĐtadonnÃĐes DRBD crÃĐÃĐes (avec drbdadm create-md r0), le lancement de la commande drbdadm up r0 dÃĐclenchera la synchronisation. Ci-dessous la synchronisation en cours :
~# drbdadm status
r0 role:Primary
disk:UpToDate
srv2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:43.03Une fois les volumes synchronisÃĐs, passer srv2 en primaire ne posera pas de difficultÃĐs.
1-3-6-4. IntÃĐgration troisiÃĻme poste▲
Bien que cela soit possible, je n'ai pas rÃĐussi à intÃĐgrer un troisiÃĻme poste sans erreur. La documentation manque de prÃĐcision.
1-3-6-5. drbdmanage▲
drbdmanage est un utilitaire simplifiant la gestion de DRBD. drbdmanage est dÃĐprÃĐciÃĐ et remplacÃĐ par linstor. Celui-ci ÃĐtant toujours disponible sur github, j'ai dÃĐcidÃĐ d'en faire une prÃĐsentation.
Nous commençons par rÃĐcupÃĐrer les sources :
git clone https://github.com/LINBIT/drbdmanage.gitPrÃĐrequis : python-dbus, python-gobject.
Une fois entre dans le dossier, l'installation se fera par :
./setup.py installLa commande drbdmanage sera alors disponible.
drbdmanage attend par dÃĐfaut la prÃĐsence d'un volume group LVM nommÃĐ drbdpool. Si vous souhaitez dÃĐfinir un nom diffÃĐrent dÃĐcommentez la ligne drbdctrl-vg dans le fichier /etc/drbdmanage.cfg et mettez-y la valeur de notre choix, dans l'exemple suivant le volume group utilisÃĐ sâappellera ÂŦ drbd Âŧ, crÃĐÃĐe dans la partition /dev/sdb1 comme ceci :
~# pvcreate /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
~# vgcreate drbd /dev/sdb1
Volume group "/dev/sdb1" successfully created.Avant de crÃĐer le cluster, comme drbdmanage a ÃĐtÃĐ installÃĐ par les sources, pour ÃĐviter un message d'erreur dbus, il faut crÃĐer le lien symbolique suivant :
ln -s /usr/local/bin/dbus-drbdmanage-service /usr/binCes opÃĐrations prÃĐliminaires seront à effectuer sur les deux machines minimales qui seront mises en place.
Nous crÃĐons une liaison SSH par clÃĐ entre les deux serveurs :
root@srv1 ~# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/cloud/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/cloud/.ssh/id_rsa.
Your public key has been saved in /home/cloud/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:RgvrHWfPnz6PiniTRaTL0AFHFoR6xWp/cRZb6Q1RJc8 cloud@Debian
The key's randomart image is:
+---[RSA 2048]----+
| .**. oo=|
| .o+ . o=.|
| ...+ + .=E|
| .+=.o o +..|
| .oS+oo + |
| . o ++oo |
| . . +o |
| .+. ..o |
| .....o=o.|
+----[SHA256]-----+
root@srv1 ~# ssh-copy-id root@192.168.1.202
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cloud/.ssh/id_rsa.pub"
The authenticity of host 'srv1 (192.168.1.201)' can't be established.
ECDSA key fingerprint is SHA256:LLALxAyQlZLXlVtPSyTrOkUaTKKC+C0UCDAQKrWTuMI.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@srv1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'cloud@srv1.local'"
and check to make sure that only the key(s) you wanted were added.Nous initialisons ensuite le cluster :
drbdmanage init 192.168.1.201Qui nous retournera :
You are going to initialize a new drbdmanage cluster.
CAUTION! Note that:
* Any previous drbdmanage cluster information may be removed
* Any remaining resources managed by a previous drbdmanage installation
that still exist on this system will no longer be managed by drbdmanage
Confirm:
yes/no: yes
Empty drbdmanage control volume initialized on '/dev/drbd0'.
Empty drbdmanage control volume initialized on '/dev/drbd1'.
Waiting for server: .
Operation completed successfullyNous pouvons voir la liste des nÅuds (un seul pour le moment) avec la commande :
drbdmanage list-nodesQui nous retournera :
+------------------------------------------------------------------------------+
| Name | Pool Size | Pool Free | | State |
|------------------------------------------------------------------------------|
| srv1 | 2044 | 2036 | | ok |
+------------------------------------------------------------------------------+Nous ajoutons ensuite le second nÅud :
drbdmanage add-node srv2 192.168.1.202
Operation completed successfully
Operation completed successfully
Executing join command using ssh.
IMPORTANT: The output you see comes from srv2
IMPORTANT: Your input is executed on srv2
You are going to join an existing drbdmanage cluster.
CAUTION! Note that:
* Any previous drbdmanage cluster information may be removed
* Any remaining resources managed by a previous drbdmanage installation
that still exist on this system will no longer be managed by drbdmanage
Confirm:
yes/no: yes
Waiting for server to start up (can take up to 1 min)
Waiting for server: ........
Operation completed successfully
Give leader time to contact the new node
Operation completed successfully
Operation completed successfullyLa commande drbdmanage list-nodes nous retournera ceci :
drbdmanage list-nodes
+------------------------------------------------------------------------------+
| Name | Pool Size | Pool Free | | State |
|------------------------------------------------------------------------------|
| srv1 | 2044 | 2036 | | online/quorum vote ignored |
| srv2 | 2044 | 2036 | | offline/quorum vote ignored |
+------------------------------------------------------------------------------+Nous crÃĐons ensuite une ressource :
:~/drbdmanage# drbdmanage add-resource r0
Operation completed successfullyPuis un volume dans la ressource :
:~/drbdmanage# drbdmanage add-volume r0 1500MB
Operation completed successfullyNous pouvons ensuite voir la liste des volumes avec la commande drbdmanage list-volumes :
~# drbdmanage list-volumes
+------------------------------------------------------------------------------+
| Name | Vol ID | Size | Minor | | State |
|------------------------------------------------------------------------------|
| r0 | 0 | 1,40 GiB | 100 | | ok |
+------------------------------------------------------------------------------+Nous pouvons voir la valeur 100 au niveau du minor, ce qui signifie que le nom du device à utiliser sera /dev/drbd100.
Nous le formatons en OCFS2 comme vu au chapitre prÃĐcÃĐdent :
~# mkfs -t ocfs2 -L MYCLOUD /dev/drbd100
mkfs.ocfs2 1.8.4
Cluster stack: classic o2cb
Label: MYCLOUD
Features: sparse extended-slotmap backup-super unwritten inline-data strict-journal-super xattr indexed-dirs refcount discontig-bg
Block size: 4096 (12 bits)
Cluster size: 4096 (12 bits)
Volume size: 1500000256 (366211 clusters) (366211 blocks)
Cluster groups: 12 (tail covers 11395 clusters, rest cover 32256 clusters)
Extent allocator size: 4194304 (1 groups)
Journal size: 67108864
Node slots: 2
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing backup superblock: 1 block(s)
Formatting Journals: done
Growing extent allocator: done
Formatting slot map: done
Formatting quota files: done
Writing lost+found: done
mkfs.ocfs2 successful1-3-6-6. Linstor▲
Linstor est le successeur de DRBD. Il est utilisÃĐ dans les solutions comme OpenNebula et Proxmox. Celui-ci est libre.
N'ayant pas rÃĐussi à l'installer, je n'ai pu le tester.
1-4. Ceph▲
Ceph est une plateforme libre de stockage distribuÃĐ. Ceph est conçu pour Être automatiquement distribuÃĐ et rÃĐparable et sans point unique de dÃĐfaillance.
Ceph est utilisable en mode bloc ou en mode objet (comme Amazon S3 en mode HTTP REST).
Ceph pourrait à lui tout seul faire l'objet d'un tutoriel, nous allons ici le survoler. Vous pourrez avoir une installation fonctionnelle au moins à minima en suivant ce chapitre.
1-4-1. Modules Ceph▲
Ceph est composÃĐ de plusieurs dÃĐmons, rÃĐpartis sur plusieurs machines. Il est possible d'avoir plusieurs types de dÃĐmons sur la mÊme machine, mais cela n'a pas dâintÃĐrÊt et est mÊme contre-productif sur un important cluster.
- Monitor (Mon) : ce sont les chefs dâorchestre du cluster Ceph. S'il n'y a pas de moniteur disponible, il n'y a pas dâaccÃĻs au cluster Ceph. Pour assurer la pÃĐrennitÃĐ du cluster, les moniteurs doivent Être sur des machines indÃĐpendantes et en nombre impair. Un minimum de trois moniteurs est recommandÃĐ.
- OSD (Object Storage Device ou OSD) : il y a un dÃĐmon OSD par device OSD. Ce dÃĐmon est en charge du stockage, de la rÃĐplication et de la redistribution des donnÃĐes en cas de dÃĐfaillance. Il fournit les informations de monitoring aux monitors. Un device OSD est l'unitÃĐ bas niveau de stockage des donnÃĐes. Un cluster Ceph va Être composÃĐ d'un ensemble d'OSD.
- Meta Data Service (MDS) : nÃĐcessaire à lâutilisation de CephFS, va stocker les mÃĐtadonnÃĐes de tous les fichiers et permettre le support de POSIX.
- CephFSÂ : systÃĻme de fichiers POSIX fourni avec Ceph et sâappuyant sur le stockage Ceph (objet ou bloc). Câest la couche de plus haut niveau.
Les dÃĐmons MDS et CephFS ne sont nÃĐcessaires que si vous utilisez Ceph avec son systÃĻme de fichiers intÃĐgrÃĐ.
ÃlÃĐments un peu plus avancÃĐs
- pool : regroupement logique de stockage dâobjets. Des pools par dÃĐfaut suffisent à la gestion dâun petit cluster Ceph, mais pour des clusters intersites, il est important dâaffiner ce type de rÃĐglage. Exemple : nombre de copies/rÃĐpliquas des objets, rÃĐpartition des donnÃĐes de type RAID5, etc.
- Placement Group (PG) : peut Être vu comme des unitÃĐs dâallocation et/ou index internes, ils servent à la rÃĐpartition dans le cluster. Plus il y a de PG, plus on consomme de ressources (CPU/RAM).
Il est possible dâaugmenter le nombre de PG dâun pool, mais pas de le rÃĐduire.
1-4-2. Fonctionnement de Ceph▲
CRUSH
CRUSH est lâalgorithme de rÃĐpartition des donnÃĐes dans le cluster. La crush map est la cartographie de la rÃĐpartition des donnÃĐes. Les crush rules sont les rÃĻgles de rÃĐpartition des donnÃĐes.
Quand vous crÃĐez un cluster Ceph, il y a une crush map par dÃĐfaut qui peut fonctionner automatiquement. Mais pour un gros cluster, il est important de la gÃĐrer. Cela permet dâaffiner la rÃĐpartition des donnÃĐes (entre deux centres de donnÃĐes par exemple), et de repÃĐrer facilement un OSD tombÃĐ (dans quel centre de donnÃĐes, quelle baie, quelle machine, etc.).
Voici les diffÃĐrents niveaux utilisÃĐs par les crush map :
- OSD (peut Être vu comme le ÂŦ device Âŧ) ;
- host ;
- chassis ;
- rack ;
- row ;
- pdu ;
- pod ;
- room ;
- datacenter ;
- region ;
- root.
SchÃĐma tirÃĐ de la documentation officielle :
 |
Voici le processus de lecture/ÃĐcriture sur un cluster Ceph :
- Le client Ceph contacte un moniteur pour obtenir la cartographie du cluster ;
- Les donnÃĐes sont converties en objets (contenant un identifiant dâobjet et de pool)Â ;
- Lâalgorithme CRUSH dÃĐtermine le groupe oÃđ placer les donnÃĐes et lâOSD primaire ;
- Le client contacte lâOSD primaire pour stocker/rÃĐcupÃĐrer les donnÃĐes ;
-
LâOSD primaire effectue une recherche CRUSH pour dÃĐterminer le groupe de placement et lâOSD secondaire.
- Dans un pool rÃĐpliquÃĐ, lâOSD primaire copie lâobjet vers lâOSD secondaire,
- Dans un pool avec erasure coding, lâOSD primaire dÃĐcoupe lâobjet en segments, gÃĐnÃĻre les segments contenant les calculs de paritÃĐ et distribue lâensemble de ces segments vers les OSD secondaires tout en ÃĐcrivant un segment en local.
1-4-3. Installation de Ceph▲
Nous utiliserons la version Ceph Luminous (v,12).
1-4-3-1. Installation d'une premiÃĻre machine▲
1-4-3-1-1. PrÃĐparations▲
Nous allons commencer par les prÃĐrequis.
Nous fixons le nom de notre hÃīte dans le fichier /,etc/hosts :
192.168.1.200 srv1Nous spÃĐcifions le hostname dans le fichier /,etc/hostname en y mettant le nom ÂŦÂ srv1Â Âŧ.
Nous lançons la commande hostname :
hostname srv1Nous fermons et rouvrons la session pour prendre en compte le nouveau nom.
Nous installons ensuite le serveur de temps, indispensable à la synchronisation correcte entre diffÃĐrentes machines :
apt-get install ntp ntpdateEnsuite, nous configurons SSH afin de permettre une connexion par clÃĐ. Dâabord, nous gÃĐnÃĐrons une clÃĐ avec la commande ssh-keygen :
root@srv1:~# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? ^C
root@srv1:~# rm .ssh/* -rf
root@srv1:~# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
3c:38:bc:0d:54:45:13:2c:dc:bd:61:8c:24:d9:58:06 root@srv1
The key's randomart image is:
+---[RSA 2048]----+
| .E%O= |
| .=o=.= |
| . . . o |
| o o . |
| = S |
| = . |
| . . |
| |
| |
+-----------------+
root@srv1:~#Ensuite, nous copions la clÃĐ avec ssh-copy-id :
ssh-copy-id root@srv1
The authenticity of host 'srv1 (192.168.1.200)' can't be established.
ECDSA key fingerprint is 92:27:9f:61:14:19:63:85:28:d2:1b:88:4e:86:d6:08.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@srv1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@srv1'"
and check to make sure that only the key(s) you wanted were added.Toutes les commandes Ceph passent par SSH et le nom d'hÃīte, il faut donc crÃĐer une clÃĐ SSH mÊme pour une communication locale.
GrÃĒce à cela, la commande ssh root@srv1 devrait ouvrir un Shell, sans nÃĐcessitÃĐ de mot de passe, ce qui nous sera nÃĐcessaire pour les commandes suivantes.
1-4-3-1-2. Installation de ceph-deploy▲
Une fois les prÃĐrequis effectuÃĐs, nous allons installer et utiliser la commande ceph-deploy qui nous permettra de prÃĐparer et dÃĐployer notre cluster.
Nous commençons par tÃĐlÃĐcharger le fichier de signature de dÃĐpÃīt :
wget download.ceph.com/keys/release.ascNous installons celui-ci :
apt-key add release.ascNous ajoutons le dÃĐpÃīt dans /etc/apt/sources.list :
deb https://download.ceph.com/debian-luminous/ stretch mainPuis effectuons l'installation :
apt-get update
apt-get install ceph-deploy1-4-3-1-3. Configuration▲
Nous crÃĐons un dossier qui contiendra les fichiers de configuration du cluster :
mkdir cephdeploy
cd cephdeployNous crÃĐons notre cluster :
ceph-deploy new srv1La console nous retournera les informations suivantes :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy new srv1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f2db686dc68>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] mon : ['srv1']
[ceph_deploy.cli][INFO ] func : <function new at 0x7f2db6843cf8>
[ceph_deploy.cli][INFO ] public_network : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster_network : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] fsid : None
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /bin/ip link show
[srv1][INFO ] Running command: /bin/ip addr show
[srv1][DEBUG ] IP addresses found: [u'192.168.1.200']
[ceph_deploy.new][DEBUG ] Resolving host srv1
[ceph_deploy.new][DEBUG ] Monitor srv1 at 192.168.1.200
[ceph_deploy.new][DEBUG ] Monitor initial members are ['srv1']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['192.168.1.200']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
root@srv1:~/cephdeploy#Ceci va crÃĐer les fichiers :
- ceph.conf ;
- ceph-deploy-ceph.log ;
- ceph.mon.keyring.
le fichier ceph.conf contient :
[global]
fsid = 85967fe2-3f08-4e0b-9f3c-ca6647776383
mon_initial_members = srv1
mon_host = 192.168.1.200
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephxDans lequel on ajoute :
osd pool default size = 2
osd pool default min size = 1
public_network = 192.168.1.0/24
cluster_network = 192.168.1.0/24C'est ce fichier qui contiendra la configuration complÃĻte du cluster. à ce stade, il n'y a qu'une machine avec les rÃĐglages minimums nÃĐcessaires au dÃĐmarrage. Ce fichier sera complÃĐtÃĐ au fur et à mesure de l'avancÃĐe dans le chapitre et de l'ajout des modules/machines.
Ceci va nous permettre de crÃĐer un pool OSD Ã deux disques et permettre l'utilisation avec un seul nÅud (en mode dÃĐgradÃĐ).
Les lignes public_network/cluster_network permettent de gÃĐrer les rÃĐseaux autorisÃĐs pour le dialogue entre les entitÃĐs Ceph. Dans notre cas, il n'y a aucune sÃĐparation ce qui n'est pas recommandÃĐ en production.
Nous installons ceph-deploy sur notre premier nÅud :
ceph-deploy install srv1Lire les logs peut permettre de comprendre les opÃĐrations dÃĐclenchÃĐes. Cela pourra vous Être utile si vous comptez utiliser le service. Si vous ne lisez ce chapitre qu'à titre de dÃĐcouverte ou de veille technologique, vous pouvez passer directement à la suite.
Voici un exemple des logs affichÃĐs :
Debian GNU/Linux 8
srv1 login: root
Password:
Last login: Fri Nov 16 18:45:59 CET 2018 from srv1 on pts/1
Linux srv1 3.16.0-4-amd64 #1 SMP Debian 3.16.51-3 (2017-12-13) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
root@srv1:~# apt-get install ca-certificates apt-transport-https
Lecture des listes de paquets... Fait
Construction de l'arbre des dÃĐpendances
Lecture des informations d'ÃĐtat... Fait
apt-transport-https est dÃĐjà la plus rÃĐcente version disponible.
ca-certificates est dÃĐjà la plus rÃĐcente version disponible.
0 mis à jour, 0 nouvellement installÃĐs, 0 à enlever et 24 non mis à jour.
root@srv1:~# ceph-deploy install srv1
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy install srv1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] testing : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fd903c207a0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] dev_commit : None
[ceph_deploy.cli][INFO ] install_mds : False
[ceph_deploy.cli][INFO ] stable : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] adjust_repos : True
[ceph_deploy.cli][INFO ] func : <function install at 0x7fd904063410>
[ceph_deploy.cli][INFO ] install_mgr : False
[ceph_deploy.cli][INFO ] install_all : False
[ceph_deploy.cli][INFO ] repo : False
[ceph_deploy.cli][INFO ] host : ['srv1']
[ceph_deploy.cli][INFO ] install_rgw : False
[ceph_deploy.cli][INFO ] install_tests : False
[ceph_deploy.cli][INFO ] repo_url : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] install_osd : False
[ceph_deploy.cli][INFO ] version_kind : stable
[ceph_deploy.cli][INFO ] install_common : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] dev : master
[ceph_deploy.cli][INFO ] nogpgcheck : False
[ceph_deploy.cli][INFO ] local_mirror : None
[ceph_deploy.cli][INFO ] release : None
[ceph_deploy.cli][INFO ] install_mon : False
[ceph_deploy.cli][INFO ] gpg_url : None
[ceph_deploy.install][DEBUG ] Installing stable version jewel on cluster ceph hosts srv1
[ceph_deploy.install][DEBUG ] Detecting platform for host srv1 ...
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[ceph_deploy.install][INFO ] Distro info: debian 8.10 jessie
[srv1][INFO ] installing Ceph on srv1
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q --no-install-recommends install ca-certificates apt-transport-https
[srv1][DEBUG ] Lecture des listes de paquetsâĶ
[srv1][DEBUG ] Construction de l'arbre des dÃĐpendancesâĶ
[srv1][DEBUG ] Lecture des informations d'ÃĐtatâĶ
[srv1][DEBUG ] apt-transport-https est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] ca-certificates est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] 0 mis à jour, 0 nouvellement installÃĐs, 0 à enlever et 24 non mis à jour.
[srv1][INFO ] Running command: wget -O release.asc https://download.ceph.com/keys/release.asc
[srv1][WARNIN] --2018-11-16 19:30:22-- https://download.ceph.com/keys/release.asc
[srv1][WARNIN] RÃĐsolution de download.ceph.com (download.ceph.com)âĶ 158.69.68.124, 2607:5300:201:2000::3:58a1
[srv1][WARNIN] Connexion à download.ceph.com (download.ceph.com)|158.69.68.124|:443âĶ connectÃĐ.
[srv1][WARNIN] requÊte HTTP transmise, en attente de la rÃĐponseâĶ 200 OK
[srv1][WARNIN] Taille : 1645 (1,6K) [application/octet-stream]
[srv1][WARNIN] Sauvegarde en : ÂŦ release.asc Âŧ
[srv1][WARNIN]
[srv1][WARNIN] 0K . 100% 27,7M=0s
[srv1][WARNIN]
[srv1][WARNIN] 2018-11-16 19:30:23 (27,7 MB/s) â ÂŦ release.asc Âŧ sauvegardÃĐ [1645/1645]
[srv1][WARNIN]
[srv1][INFO ] Running command: apt-key add release.asc
[srv1][DEBUG ] OK
[srv1][DEBUG ] add deb repo to /etc/apt/sources.list.d/
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q update
[srv1][DEBUG ] Ign http://ftp.fr.debian.org jessie InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie-updates InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie Release.gpg
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie Release
[srv1][DEBUG ] RÃĐception de : 1 http://ftp.fr.debian.org jessie-updates/main amd64 Packages/DiffIndex [11,8 kB]
[srv1][DEBUG ] RÃĐception de : 2 http://ftp.fr.debian.org jessie-updates/main Translation-en/DiffIndex [3 688 B]
[srv1][DEBUG ] Atteint https://download.ceph.com jessie InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates/main amd64 Packages
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates/main Translation-en
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main amd64 Packages
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main Translation-fr
[srv1][DEBUG ] RÃĐception de : 3 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main Translation-en
[srv1][DEBUG ] RÃĐception de : 4 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] RÃĐception de : 5 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Atteint https://download.ceph.com jessie/main amd64 Packages
[srv1][DEBUG ] RÃĐception de : 6 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] RÃĐception de : 7 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] RÃĐception de : 8 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] RÃĐception de : 9 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] RÃĐception de : 10 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] RÃĐception de : 11 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] RÃĐception de : 12 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] RÃĐception de : 13 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] RÃĐception de : 14 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] RÃĐception de : 15 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-fr_FR
[srv1][DEBUG ] RÃĐception de : 16 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-fr
[srv1][DEBUG ] RÃĐception de : 17 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-en
[srv1][DEBUG ] 15,5 ko rÃĐceptionnÃĐs en 5s (3 032 o/s)
[srv1][DEBUG ] Lecture des listes de paquetsâĶ
[srv1][WARNIN] W: Duplicate sources.list entry https://download.ceph.com/debian-jewel/ jessie/main amd64 Packages (/var/lib/apt/lists/download.ceph.com_debian-jewel_dists_jessie_main_binary-amd64_Packages)
[srv1][WARNIN] W: Vous pouvez lancer ÂŦ apt-get update Âŧ pour corriger ces problÃĻmes.
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q --no-install-recommends install -o Dpkg::Options::=--force-confnew ceph ceph-osd ceph-mds ceph-mon radosgw
[srv1][DEBUG ] Lecture des listes de paquetsâĶ
[srv1][DEBUG ] Construction de l'arbre des dÃĐpendancesâĶ
[srv1][DEBUG ] Lecture des informations d'ÃĐtatâĶ
[srv1][DEBUG ] ceph est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] ceph-mds est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] ceph-mon est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] ceph-osd est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] radosgw est dÃĐjà la plus rÃĐcente version disponible.
[srv1][DEBUG ] 0 mis à jour, 0 nouvellement installÃĐs, 0 à enlever et 24 non mis à jour.
[srv1][INFO ] Running command: ceph --version
[srv1][DEBUG ] ceph version 10.2.11 (e4b061b47f07f583c92a050d9e84b1813a35671e)
root@srv1:~#Dans les logs, nous pouvons voir ce qu'il se passe :
- connexion SSH sur srv1Â ;
- tÃĐlÃĐchargement de la clÃĐ de dÃĐpÃīt Ceph (nous l'avons dÃĐjà fait pour l'installation de ceph-deploy, inutile ici, mais nÃĐcessaire pour le dÃĐploiement de Ceph sur une autre machine) ;
- ajout de la clÃĐ avec apt-key (dÃĐjà fait) ;
- ajout du dÃĐpÃīt dans /etc/apt/sources.list.d (en doublon avec ce qui a dÃĐjà ÃĐtÃĐ fait pour installer ceph-deploy, nous voyons un avertissement à ce sujet) ;
- installation des paquets nÃĐcessaires.
La commande se termine par l'appel de ceph âversion.
La commande est prÃĐvue pour installer tout ce qu'il faut sur n'importe quelle machine via SSH.
1-4-3-1-4. CrÃĐation d'un moniteur▲
Pour gÃĐrer notre cluster, nous avons besoin dâun moniteur. La crÃĐation sâeffectue avec la commande :
ceph-deploy mon create-initialQui retourne :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy mon create-initial
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create-initial
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7faf0fb69fc8>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mon at 0x7faf0ffd4500>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] keyrings : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mon][DEBUG ] Deploying mon, cluster ceph hosts srv1
[ceph_deploy.mon][DEBUG ] detecting platform for host srv1 ...
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[ceph_deploy.mon][INFO ] distro info: debian 8.10 jessie
[srv1][DEBUG ] determining if provided host has same hostname in remote
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] deploying mon to srv1
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] remote hostname: srv1
[srv1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[srv1][DEBUG ] create the mon path if it does not exist
[srv1][DEBUG ] checking for done path: /var/lib/ceph/mon/ceph-srv1/done
[srv1][DEBUG ] done path does not exist: /var/lib/ceph/mon/ceph-srv1/done
[srv1][INFO ] creating keyring file: /var/lib/ceph/tmp/ceph-srv1.mon.keyring
[srv1][DEBUG ] create the monitor keyring file
[srv1][INFO ] Running command: ceph-mon --cluster ceph --mkfs -i srv1 --keyring /var/lib/ceph/tmp/ceph-srv1.mon.keyring --setuser 64045 --setgroup 64045
[srv1][DEBUG ] ceph-mon: renaming mon.noname-a 192.168.1.200:6789/0 to mon.srv1
[srv1][DEBUG ] ceph-mon: set fsid to 85967fe2-3f08-4e0b-9f3c-ca6647776383
[srv1][DEBUG ] ceph-mon: created monfs at /var/lib/ceph/mon/ceph-srv1 for mon.srv1
[srv1][INFO ] unlinking keyring file /var/lib/ceph/tmp/ceph-srv1.mon.keyring
[srv1][DEBUG ] create a done file to avoid re-doing the mon deployment
[srv1][DEBUG ] create the init path if it does not exist
[srv1][INFO ] Running command: systemctl enable ceph.target
[srv1][INFO ] Running command: systemctl enable ceph-mon@srv1
[srv1][WARNIN] Created symlink from /etc/systemd/system/ceph-mon.target.wants/ceph-mon@srv1.service to /lib/systemd/system/ceph-mon@.service.
[srv1][INFO ] Running command: systemctl start ceph-mon@srv1
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[srv1][DEBUG ] ********************************************************************************
[srv1][DEBUG ] status for monitor: mon.srv1
[srv1][DEBUG ] {
[srv1][DEBUG ] "election_epoch": 3,
[srv1][DEBUG ] "extra_probe_peers": [],
[srv1][DEBUG ] "monmap": {
[srv1][DEBUG ] "created": "2018-11-16 19:53:16.240703",
[srv1][DEBUG ] "epoch": 1,
[srv1][DEBUG ] "fsid": "85967fe2-3f08-4e0b-9f3c-ca6647776383",
[srv1][DEBUG ] "modified": "2018-11-16 19:53:16.240703",
[srv1][DEBUG ] "mons": [
[srv1][DEBUG ] {
[srv1][DEBUG ] "addr": "192.168.1.200:6789/0",
[srv1][DEBUG ] "name": "srv1",
[srv1][DEBUG ] "rank": 0
[srv1][DEBUG ] }
[srv1][DEBUG ] ]
[srv1][DEBUG ] },
[srv1][DEBUG ] "name": "srv1",
[srv1][DEBUG ] "outside_quorum": [],
[srv1][DEBUG ] "quorum": [
[srv1][DEBUG ] 0
[srv1][DEBUG ] ],
[srv1][DEBUG ] "rank": 0,
[srv1][DEBUG ] "state": "leader",
[srv1][DEBUG ] "sync_provider": []
[srv1][DEBUG ] }
[srv1][DEBUG ] ********************************************************************************
[srv1][INFO ] monitor: mon.srv1 is running
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[ceph_deploy.mon][INFO ] processing monitor mon.srv1
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[ceph_deploy.mon][INFO ] mon.srv1 monitor has reached quorum!
[ceph_deploy.mon][INFO ] all initial monitors are running and have formed quorum
[ceph_deploy.mon][INFO ] Running gatherkeys...
[ceph_deploy.gatherkeys][INFO ] Storing keys in temp directory /tmp/tmpyWJn4J
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] fetch remote file
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --admin-daemon=/var/run/ceph/ceph-mon.srv1.asok mon_status
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.admin
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-mds
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get-or-create client.bootstrap-mds mon allow profile bootstrap-mds
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-mgr
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get-or-create client.bootstrap-mgr mon allow profile bootstrap-mgr
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-osd
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-rgw
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpyWJn4J
root@srv1:~/cephdeploy#1-4-3-1-5. Ajout d'OSD▲
Nous pouvons commencer par lister les disques d'un hÃīte Ceph avec la commande suivante :
ceph-deploy disk list srv1Qui affichera dans mon exemple :
âĶ
[srv1][INFO ] Running command: /usr/sbin/ceph-disk list
[srv1][DEBUG ] /dev/sda :
[srv1][DEBUG ] /dev/sda2 swap, swap
[srv1][DEBUG ] /dev/sda1 other, ext4, mounted on /
[srv1][DEBUG ] /dev/sdb other, unknown
[srv1][DEBUG ] /dev/sr0 other, unknown
root@srv1:~/cephdeploy#Nous allons procÃĐder à la prÃĐparation de l'OSD sur le disque /dev/sdb.
Ceci effacera l'ÃĐventuel contenu sur le disque.
Voici la commande :
ceph-deploy osd prepare srv1:/dev/sdbQui retournera :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy osd prepare srv1:/dev/sdb
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] disk : [('srv1', '/dev/sdb', None)]
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : prepare
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /,etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fc9a8963ef0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x7fc9a8dc6488>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.osd][DEBUG ] Preparing cluster ceph disks srv1:/dev/sdb:
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: debian 8.10 jessie
[ceph_deploy.osd][DEBUG ] Deploying osd to srv1
[srv1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.osd][DEBUG ] Preparing host srv1 disk /dev/sdb journal None activate False
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /usr/sbin/ceph-disk -v prepare --cluster ceph --fs-type xfs -- /dev/sdb
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=fsid
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-allows-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-wants-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-needs-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] set_type: Will colocate journal with data on /dev/sdb
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=osd_journal_size
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_mkfs_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_fs_mkfs_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_mount_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_fs_mount_options_xfs
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] ptype_tobe_for_name: name = journal
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] create_partition: Creating journal partition num 2 size 5120 on /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --new=2:0:+5120M --change-name=2:ceph journal --partition-guid=2:74a9b3f0-08b8-48db-a3ec-e6e36451d0d9 --typecode=2:45b0969e-9b03-4f30-b4c6-b4b80ceff106 --mbrtogpt -- /dev/sdb
[srv1][DEBUG ] Creating new GPT entries.
[srv1][DEBUG ] Setting name!
[srv1][DEBUG ] partNum is 1
[srv1][DEBUG ] REALLY setting name!
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on created device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb2 uuid path is /sys/dev/block/8:18/dm/uuid
[srv1][WARNIN] prepare_device: Journal is GPT partition /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] prepare_device: Journal is GPT partition /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] set_data_partition: Creating osd partition on /dev/sdb
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] ptype_tobe_for_name: name = data
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] create_partition: Creating data partition num 1 size 0 on /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --largest-new=1 --change-name=1:ceph data --partition-guid=1:720e149a-ebb7-4d44-9b89-d1c017481c18 --typecode=1:89c57f98-2fe5-4dc0-89c1-f3ad0ceff2be --mbrtogpt -- /dev/sdb
[srv1][DEBUG ] Setting name!
[srv1][DEBUG ] partNum is 0
[srv1][DEBUG ] REALLY setting name!
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on created device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb1 uuid path is /sys/dev/block/8:17/dm/uuid
[srv1][WARNIN] populate_data_path_device: Creating xfs fs on /dev/sdb1
[srv1][WARNIN] command_check_call: Running command: /sbin/mkfs -t xfs -f -i size=2048 -- /dev/sdb1
[srv1][DEBUG ] meta-data=/dev/sdb1 isize=2048 agcount=4, agsize=196543 blks
[srv1][DEBUG ] = sectsz=512 attr=2, projid32bit=1
[srv1][DEBUG ] = crc=0 finobt=0
[srv1][DEBUG ] data = bsize=4096 blocks=786171, imaxpct=25
[srv1][DEBUG ] = sunit=0 swidth=0 blks
[srv1][DEBUG ] naming =version 2 bsize=4096 ascii-ci=0 ftype=0
[srv1][DEBUG ] log =internal log bsize=4096 blocks=2560, version=2
[srv1][DEBUG ] = sectsz=512 sunit=0 blks, lazy-count=1
[srv1][DEBUG ] realtime =none extsz=4096 blocks=0, rtextents=0
[srv1][WARNIN] mount: Mounting /dev/sdb1 on /var/lib/ceph/tmp/mnt.zWKFv6 with options noatime,inode64
[srv1][WARNIN] command_check_call: Running command: /bin/mount -t xfs -o noatime,inode64 -- /dev/sdb1 /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] populate_data_path: Preparing osd data dir /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/ceph_fsid.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/fsid.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/magic.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/journal_uuid.4952.tmp
[srv1][WARNIN] adjust_symlink: Creating symlink /var/lib/ceph/tmp/mnt.zWKFv6/journal -> /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] unmount: Unmounting /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] command_check_call: Running command: /bin/umount -- /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --typecode=1:4fbd7e29-9d25-41b8-afd0-062c0ceff05d -- /dev/sdb
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on prepared device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm trigger --action=add --sysname-match sdb1
[srv1][INFO ] checking OSD status...
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /usr/bin/ceph --cluster=ceph osd stat --format=json
[srv1][WARNIN] there is 1 OSD down
[srv1][WARNIN] there is 1 OSD out
[ceph_deploy.osd][DEBUG ] Host srv1 is now ready for osd use.
root@srv1:~/cephdeploy#Nous pouvons voir la crÃĐation d'une table de partitions GPT et la crÃĐation de partitions XFS.
Rappelons la commande ceph-deploy disk list srv1Â :
âĶ
[srv1][INFO ] Running command: /usr/sbin/ceph-disk list
[srv1][DEBUG ] /dev/sda :
[srv1][DEBUG ] /dev/sda2 swap, swap
[srv1][DEBUG ] /dev/sda1 other, ext4, mounted on /
[srv1][DEBUG ] /dev/sdb :
[srv1][DEBUG ] /dev/sdb2 ceph journal, for /dev/sdb1
[srv1][DEBUG ] /dev/sdb1 ceph data, active, cluster ceph, osd.0, journal /dev/sdb2
[srv1][DEBUG ] /dev/sr0 other, unknown
root@srv1:~/cephdeploy#Nous pouvons voir qu'il y a en fait deux partitions : une partition pour les donnÃĐes de Ceph (ceph data) en /dev/sdb1 et une partition pour les journaux Ceph (ceph journal) en /dev/sdb2.
Pour des questions de performance, il est conseillÃĐ de mettre les journaux sur disques SSD).
Nous activons ensuite l'OSDÂ :
ceph-deploy osd activate srv1:/dev/sdb1Pour lister les OSD d'un cluster Ceph, vous pouvez utiliser la commande suivante :
ceph osd treeQui retournera dans mon exemple :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
root@srv1:~#Nous pouvons voir que notre cluster ne contient qu'un seul OSDÂ : osd.0 sur l'hÃīte srv1.
1-4-3-1-6. PrÃĐparation des pools▲
Nous prÃĐparation ensuite le pool pour le systÃĻme de fichiers CephFSÂ :
ceph osd pool create cephfs_metadata 128
ceph osd pool create cephfs_data 128La valeur de paramÃĻtre 128 correspond à la valeur de ÂŦ placement group Âŧ appelÃĐ aussi PG.
Voici ce qui est prÃĐconisÃĐ par Ceph :
- moins de 5 OSDÂ : 128Â ;
- entre 5 et 10 OSDÂ : 512Â ;
- entre 10 et 50 OSDÂ : 1024.
Au-delà de 50 OSD, il est recommandÃĐ dâutiliser la formule conseillÃĐe par les dÃĐveloppeurs. Vous pouvez la retrouver avec lâoutil en ligne pgcal.
Les ÂŦ placement group Âŧ permettent d'agrÃĐger les objets en pools, permettant le suivi de ceux-ci de façon plus efficace, surtout dans des infrastructures importantes.
Listage des pool
Pour lister les pool d'un cluster Ceph, on utilisera la commande :
ceph osd lspoolsQui nous retournera :
0 rbd,1 cephfs_metadata,2 cephfs_data,
root@srv1:~#Le pool rbd est un pool de base, qui ne nous servira pas, nous pouvons le supprimer avec la commande :
ceph osd pool delete rbdVous aurez un message vous expliquant qu'il faut saisir deux fois le nom du rbd suivi de âyes-i-really-really-mean-it.
1-4-3-1-7. CrÃĐation d'un dÃĐmon MDS▲
La crÃĐation dâun dÃĐmon MDS sâeffectue avec la commande suivante :
ceph-deploy mds create srv1Celui-ci sera nÃĐcessaire pour gÃĐrer les mÃĐtadonnÃĐes du systÃĻme de fichier CephFS.
1-4-3-1-8. CrÃĐation du systÃĻme de fichiers CephFS▲
La crÃĐation de notre systÃĻme de fichiers se fait via la commande :
root@srv1:~/cephdeploy# ceph fs new mon_fs cephfs_metadata cephfs_data
new fs with metadata pool 1 and data pool 2
root@srv1:~/cephdeploy#mon_fs ÃĐtant le nom donnÃĐ au systÃĻme de fichiers.
Ãtat du cluster
Nous pouvons voir l'ÃĐtat du cluster Ceph avec la commande :
ceph -sRÃĐsultat :
cluster fba9a869-5b18-4feb-bd9c-5374808af689
health HEALTH_WARN
192 pgs degraded
64 pgs stuck unclean
192 pgs undersized
recovery 20/40 objects degraded (50.000%)
monmap e1: 1 mons at {srv1=192.168.1.200:6789/0}
election epoch 3, quorum 0 srv1
fsmap e5: 1/1/1 up {0=srv1=up:active}
osdmap e10: 1 osds: 1 up, 1 in
flags sortbitwise,require_jewel_osds
pgmap v22: 192 pgs, 3 pools, 2068 bytes data, 20 objects
108 MB used, 2952 MB / 3060 MB avail
20/40 objects degraded (50.000%)
192 active+undersized+degraded
root@srv1:~#1-4-3-1-9. Montage du volume CephFS▲
Nous commençons par dÃĐployer les fichiers de configuration avec la commande :
ceph-deploy admin srv1Ceci va copier les fichiers suivants dans /,etc/ceph :
- ceph.client.admin.keyring ;
- ceph.conf ;
- rbdmap.
Il nous faut crÃĐer un fichier ceph.client.admin.keyring contenant la clÃĐ codÃĐe en Base64.
Le fichier a le format suivant :
[client.test]
key = AQDR1O9bDuaFMBAAwlLxUpWYzVTtNaAAawYygA==Nous dupliquons le fichier client.ceph.admin.keyring dans le dossier /,etc/ceph. Nous nommons la copie client.admin.
Le fichier ne devra contenir que la clÃĐ Base64Â :
AQDR1O9bDuaFMBAAwlLxUpWYzVTtNaAAawYygA==Exemple de commande de gÃĐnÃĐration d'une clÃĐ pour un utilisateur prÃĐcis :
root@srv1:~/cephdeploy# ceph auth get-or-create client.test mds 'allow' osd 'allow *' mon 'allow *' > fichier_de_keyringNous aurons besoin du paquet ceph-fs-common que ceph-deploy n'a pas installÃĐÂ :
apt-get install ceph-fs-commonNous pourrons ensuite monter le volume avec la commande mount à laquelle nous lui aurons donnÃĐ en option le nom d'utilisateur ainsi que le fichier de clÃĐ :
mount.ceph srv1:/ /mnt -o name=admin,secretfile=/etc/ceph/client.adminVoici la ligne à ajouter dans /,etc/fstab pour un montage automatique lors du dÃĐmarrage de la machine :
srv1:/ /mnt ceph name=admin,secretfile=/etc/ceph/admin.clientIl faudra garder les fichiers du dossier de configuration ceph-deploy et s'assurer d'en avoir une sauvegarde.
1-4-3-2. Ajout d'une seconde machine▲
Il faudra quâOpenSSH, un serveur de temps et Python soit installÃĐ sur lâhÃīte.
Il faudra procÃĐder à la configuration de SSH de façon à ce que srv1 puisse le contacter sans authentification. Tout cela comme pour la prÃĐparation du premier serveurPrÃĐparations.
Nous installons ensuite Ceph sur le nouveau serveur srv2 depuis srv1Â :
ceph-deploy install srv2Nous crÃĐons ensuite un OSD sur la machine srv2 de la mÊme façon que pour srv1 :
ceph-deploy osd prepare srv2:/dev/sdb
ceph-deploy osd activate srv2:/dev/sdb1Nous pourrons voir les deux OSD sur les deux hÃītes avec la commande ceph osd tree :
root@srv1:~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 up 1.00000 1.00000Nous pouvons voir l'ÃĐtat du cluster avec la commande ceph -s. Vous pourrez voir son ÃĐtat de reconstruction. Une fois la mise à jour des blocs sur le nouvel OSD, nous pourrons voir le cluster en mode HEALTH_OK :
root@srv1:~# ceph -s
cluster fba9a869-5b18-4feb-bd9c-5374808af689
health HEALTH_OK
monmap e1: 1 mons at {srv1=192.168.1.200:6789/0}
election epoch 4, quorum 0 srv1
fsmap e11: 1/1/1 up {0=srv1=up:active}
osdmap e21: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v140: 192 pgs, 3 pools, 6186 kB data, 34 objects
231 MB used, 5890 MB / 6121 MB avail
192 active+clean
root@srv1:~#Nous pouvons ensuite ajouter srv2 en tant que moniteur :
ceph-deploy mon add srv2RÃĐsultat :
âĶ
[srv2][INFO ] monitor: mon.srv2 is currently at the state of probingPour rappel, le nombre de moniteurs doit Être impair, et il est recommandÃĐ de mettre un moniteur sur une machine autonome hors OSD.
Sur le mÊme principe, nous pouvons ajouter un serveur de mÃĐtadonnÃĐes sur srv2 :
ceph-deploy mds create srv2Nous modifions le fichier ceph.conf en y ajoutant l'adresse IP du second moniteur dans la ligne mon_host, puis nous mettons ensuite à jour les configurations :
ceph-deploy --overwrite-conf admin srv1 srv2L'option -âoverwite-conf ÃĐtant nÃĐcessaire pour ÃĐcraser une ancienne configuration (celle de srv1 dans notre cas, la commande ayant dÃĐjà ÃĐtÃĐ lancÃĐe dessus).
1-4-3-3. Test de panne : arrÊt de srv1▲
La perte de srv1 (ou de srv2) ne provoque pas lâindisponibilitÃĐ du cluster en cas de prÃĐsence d'un troisiÃĻme serveur hÃĐbergeant un moniteur. Dans le cas contraire, le point de montage est indisponible aprÃĻs quelques secondes et la commande ceph -s bloque la console.
Le redÃĐmarrage de la machine arrÊtÃĐe permettra de rÃĐcupÃĐrer le cluster aprÃĻs rÃĐparation automatique.
1-4-3-4. ProcÃĐdure de rÃĐparation d'un nÅud▲
Nous commençons par voir l'ÃĐtat de Ceph :
~# ceph -sQui nous affichera :
cluster 6e3c0267-1480-4671-9382-9686be7e2663
health HEALTH_WARN
200 pgs degraded
200 pgs stuck degraded
200 pgs stuck unclean
200 pgs stuck undersized
200 pgs undersized
recovery 21/63 objects degraded (33.333%)
1 mons down, quorum 0,2 srv1,srv3
monmap e3: 3 mons at {srv1=192.168.1.200:6789/0,srv2=192.168.1.201:6789/0,srv3=192.168.1.202:6789/0}
election epoch 16, quorum 0,2 srv1,srv3
fsmap e9: 1/1/1 up {0=srv1=up:active}
osdmap e45: 3 osds: 2 up, 2 in; 200 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v189: 200 pgs, 2 pools, 23070 bytes data, 21 objects
218 MB used, 5903 MB / 6121 MB avail
21/63 objects degraded (33.333%)
200 active+undersized+degradedPour voir ce quâil en est des OSDÂ :
~# ceph osd treeQui nous retournera :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00870 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 down 0 1.00000
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Nous voyons que lâOSD.1 sur l'hÃīte srv2 est ÂŦ down Âŧ. Nous le supprimons :
~# ceph osd rm osd.1
removed osd.1Nous rappelons la commande ceph osd tree :
~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00870 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 DNE 0
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Nous voyons lâOSD 1 toujours prÃĐsent en mode DNE (pour Do Not Exist).
Nous supprimons celui-ci dÃĐfinitivement avec la commande suivante :
~# ceph osd crush rm osd.1
removed item id 1 name 'osd.1' from crush mapNous supprimons ensuite les autorisations :
~# ceph auth del osd.1
updatedSi nous rappelons la commande ceph osd tree, l'OSD n'est plus prÃĐsent, mais nous voyons toujours le nÅud (sans OSD)Â :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0 host srv2
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Pour supprimer celui-ci, nous allons l'enlever de la crush map.
Nous commençons par exporter celle-ci avec la commande getcrushmap.
~# ceph osd getcrushmap -o crush_map
got crush map from osdmap epoch 79Il va falloir convertir ce fichier en mode texte :
~# crushtool -d crush_map -o crush_map.txtVoici un exemple du contenu de ce fichier texte :
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable straw_calc_version 1
# devices
device 0 osd.0
device 1 device1
device 2 osd.2
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host srv1 {
id -2 # do not change unnecessarily
# weight 0.003
alg straw
hash 0 # rjenkins1
item osd.0 weight 0.003
}
host srv3 {
id -4 # do not change unnecessarily
# weight 0.003
alg straw
hash 0 # rjenkins1
item osd.2 weight 0.003
}
host srv2 {
id -3 # do not change unnecessarily
# weight 0.000
alg straw
hash 0 # rjenkins1
}
root default {
id -1 # do not change unnecessarily
# weight 0.006
alg straw
hash 0 # rjenkins1
item srv1 weight 0.003
item srv3 weight 0.003
item srv2 weight 0.000
}
# rules
rule replicated_ruleset {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush mapModifier la crush map va permettre d'optimiser la gestion du cluster Ceph notamment dans le cas de nÅuds importants (gestion de rÃĐgions, rack, pds, etc.)
Je retire les rÃĐfÃĐrences à srv2 (le bloc srv2 entre crochets, et la ligne item srv2...)
Pour appliquer les modifications, je recompile le fichier texte :
~# crushtool -c crush_map.txt -o crush_mapPuis applique celui-ci :
~# ceph osd setcrushmap -i crush_map
set crush mapToute trace de srv2 dans les OSD est alors supprimÃĐe.
Nous prÃĐparons ensuite un serveur de base avec les prÃĐrequis (adresse IP de srv2, nom de machine srv2, fichier hosts renseignÃĐ avec les autres serveurs, paquets ntp, openssh-server, et python installÃĐ).
Nous recopions ensuite la clÃĐ SSH de srv1 vers srv2Â :
~# ssh-copy-id root@srv2Nous allons avoir un message d'erreur :
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
ERROR: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
ERROR: It is also possible that a host key has just been changed.
ERROR: The fingerprint for the ECDSA key sent by the remote host is
ERROR: SHA256:GXC4wVDCLG3a+KXA3Tb95ULTZGm2REM0pmOBBCZ371A.
ERROR: Please contact your system administrator.
ERROR: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
ERROR: Offending ECDSA key in /root/.ssh/known_hosts:5
ERROR: remove with:
ERROR: ssh-keygen -f "/root/.ssh/known_hosts" -R srv2
ERROR: ECDSA host key for srv2 has changed and you have requested strict checking.
ERROR: Host key verification failed.Nous utilisons la commande ssh-keygen :
~# ssh-keygen -f "/root/.ssh/known_hosts" -R srv2
# Host srv2 found: line 5
/root/.ssh/known_hosts updated.
Original contents retained as /root/.ssh/known_hosts.oldNous refaisons une tentative de connexion :
ssh root@srv2
The authenticity of host 'srv2 (192.168.1.201)' can't be established.
ECDSA key fingerprint is SHA256:GXC4wVDCLG3a+KXA3Tb95ULTZGm2REM0pmOBBCZ371A.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'srv2' (ECDSA) to the list of known hosts.
Warning: the ECDSA host key for 'srv2' differs from the key for the IP address '192.168.1.201'
Offending key for IP in /root/.ssh/known_hosts:5
Are you sure you want to continue connecting (yes/no)? yes
root@srv2's password:Nous entrons le mot de passe. La prochaine connexion donnera :
Offending key for IP in /root/.ssh/known_hosts:5
Matching host key in /root/.ssh/known_hosts:6
Are you sure you want to continue connecting (yes/no)? yesNous supprimons la ligne concernÃĐe :
~# sed -i '5d' ~/.ssh/known_hostsLa commande ssd-copy-id pourra ensuite sâexÃĐcuter sans erreur, et une connexion via ssh root@srv2 sans demande de mot de passe sera possible.
Nous rÃĐinstallons ensuite Ceph :
~# ceph-deploy install srv2Nous recrÃĐons ensuite les OSD comme vu prÃĐcÃĐdemmentAjout d'OSD.
Nous rÃĐinstallons le moniteur sur srv2Â :
ceph mon add srv2Nous lançons la commande ceph health. Une fois la rÃĐparation terminÃĐe, la commande ceph -s nous donnera un statut de HEALTH_OK.
1-5. min.io▲
min.io est un systÃĻme de stockage cloud open source, crÃĐe par un ancien de lâÃĐquipe Gluster. Il peut Être utilisÃĐ avec une configuration de 2 à 32 serveurs et stocker des objets jusquâà 5 To. Il ne possÃĻde pas de limite sur le nombre de buckets (notion que nous verrons plus tard) ou dâobjets par bucket.
Il peut se comporter comme le service S3 dâAmazon ou faire passerelle avec le service S3 Amazon. Il peut ÃĐgalement faire passerelle NFS .
Il est prÃĐvu dâorigine pour fonctionner dans Docker.
1-5-1. Les diffÃĐrents modes de fonctionnement▲
Default mode : c'est le mode par dÃĐfaut de fonctionnement de min.io quand utilisÃĐ avec une seule machine et un seul disque.
Erasure coded mode : mode permettant la reconstruction des donnÃĐes en cas de perte de ressource. Cet algorithme est basÃĐ sur l'algorithme Reed-Solomon. Ce mode nÃĐcessite un minimum de quatre disques.
Distributed mode : le serveur min.io en mode distribuÃĐ vous permet de mettre en pool plusieurs lecteurs (mÊme sur diffÃĐrentes machines) sur un serveur de stockage d'objet unique. Les disques ÃĐtant rÃĐpartis sur plusieurs nÅuds, min.io distribuÃĐ peut supporter plusieurs dÃĐfaillances tout en assurant une protection complÃĻte des donnÃĐes.
1-5-2. Installation de min.io▲
min.io est un simple exÃĐcutable. Il est rÃĐcupÃĐrable sur le site officiel à l'adresse https://min.io/download ou comme ceci :
wget https://dl.min.io/server/minio/release/linux-amd64/minioil faudra ensuite mettre les droits dâexÃĐcution :
chmod +x minioNous dÃĐplacerons ensuite le fichier dans /usr/local/bin.
Il est ÃĐgalement possible dâinstaller min.io au travers de brew pour Mac OS X.
Il suffira ensuite de taper la commande minio pour obtenir de lâaide.
1-5-3. Test en mode simple instance▲
Nous allons lancer min.io en fournissant le dossier /data1/minio1 en paramÃĻtre :
minio server /data1/minio1Ce qui donne :
Endpoint: http://192.168.1.200:9000 http://127.0.0.1:9000
AccessKey: minioadmin
SecretKey: minioadmin
Browser Access:
http://192.168.1.200:9000 http://127.0.0.1:9000
Command-line Access: https://docs.min.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.200:9000 minioadmin minioadmin
Object API (Amazon S3 compatible):
Go: https://docs.min.io/docs/golang-client-quickstart-guide
Java: https://docs.min.io/docs/java-client-quickstart-guide
Python: https://docs.min.io/docs/python-client-quickstart-guide
JavaScript: https://docs.min.io/docs/javascript-client-quickstart-guide
.NET: https://docs.min.io/docs/dotnet-client-quickstart-guide
Detected default credentials 'minioadmin:minioadmin', please change the credentals immediately using 'MINIO_ACCESS_KEY' and 'MINIO_SECRET_KEY'Le retour de la commande nous donne toutes les mÃĐthodes d'accÃĻs possibles.
Nous pouvons notamment voir que lâaccÃĻs peut se faire depuis le web via le port 9000. Il est possible de changer le port par dÃĐfaut en le prÃĐcisant dans la ligne d'appel sous la forme http://192.168.1.200:9000.
Il est ÃĐgalement prÃĐcisÃĐ que lâidentifiant et mot de passe par dÃĐfaut est ÂŦ minioadmin Âŧ. Il faudra bien sÃŧr le changer.
Pour cela il suffit d'exporter les variables MINIO_ACCESS_KEY et MINIO_SECRET_KEY.
MINIO_SECRET_KEY doit faire minium huit caractÃĻres.
~# export MINIO_ACCESS_KEY=admin
~# export MINIO_SECRET_KEY=rootroot
~# ./minio server /data1
Attempting encryption of all config, IAM users and policies on MinIO backend
Endpoint: http://192.168.1.200:9000 http://127.0.0.1:9000
AccessKey: admin
SecretKey: rootroot
Browser Access:
http://192.168.1.200:9000 http://127.0.0.1:9000
Command-line Access: https://docs.min.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.200:9000 admin rootroot
Object API (Amazon S3 compatible):
Go: https://docs.min.io/docs/golang-client-quickstart-guide
Java: https://docs.min.io/docs/java-client-quickstart-guide
Python: https://docs.min.io/docs/python-client-quickstart-guide
JavaScript: https://docs.min.io/docs/javascript-client-quickstart-guide
.NET: https://docs.min.io/docs/dotnet-client-quickstart-guide1-5-3-1. AccÃĻs via le web▲
 |
Le login et le mot de passe correspondent à lâaccessKey et la SecretKey retournÃĐ par lâappel de min.io .
1-5-3-2. Gestion de fichiers depuis l'interface web▲
Une fois loguÃĐ, vous obtiendrez lâÃĐcran suivant :
 |
Il va nous falloir crÃĐer au moins un Bucket, entitÃĐ de stockage de min.io, qui peut Être considÃĐrÃĐ comme un dossier, ceci en cliquant sur le ![]() , puis ÂŦ create Bucket Âŧ :
, puis ÂŦ create Bucket Âŧ :
 |
AprÃĻs crÃĐation, les Buckets apparaÃŪtront sur la gauche (dans notre cas bucket1, puis bucket2)Â :
 |
Lors de la crÃĐation des Buckets, ceux-ci ne sont affichÃĐs dans lâordre alphabÃĐtique quâaprÃĻs rafraÃŪchissement par clic sur lâadresse en bas à gauche.
La crÃĐation d'un Bucket va crÃĐer un dossier du mÊme nom dans le systÃĻme de fichiers (dans le dossier /data1 dans notre cas). La crÃĐation d'un dossier hors de l'interface va Être vue comme un Bucket dans l'interface web.
Un sous-dossier crÃĐÃĐ en ligne de commande sera exploitable depuis l'interface web :
|
|
Il sera possible d'entrer dans le dossier, d'y uploader des fichiers. Par contre, il nây a pas d'option dans l'interface web pour crÃĐer un sous-dossier.
La suppression d'un Bucket (un dossier) se fera en se mettant sur celui-ci et en cliquant sur les traits :
|
|
La suppression d'un Bucket va supprimer son contenu.
1-5-3-2-1. Upload de fichier▲
Pour uploader un fichier, il faut cliquer sur le ![]() , puis sur lâicÃīne upload file
, puis sur lâicÃīne upload file ![]()
Les fichiers apparaÃŪtront sur le disque tels quels. Si vous ajoutez un fichier manuellement dans le dossier/Bucket, celui-ci sera disponible dans l'interface.
1-5-3-2-2. AccÃĻs aux fichiers▲
 |
LâicÃīne en 1 permet de crÃĐer un lien de partage dont la validitÃĐ peut sâÃĐtendre jusquâà sept jours. Il nây a pas de possibilitÃĐ de crÃĐer un lien permanent. LâicÃīne 2 permet la suppression du document. Il nây a pas de systÃĻme de versionnage. MÊme si on peut utiliser un accÃĻs web, il sâagit dâun espace de stockage, pas dâun service de synchronisation de fichiers comme ceux dÃĐjà vus.
Il ne semble pas possible de renommer un fichier.
Il est possible de tÃĐlÃĐcharger le fichier en cliquant sur le rond à gauche du nom. Une barre apparaÃŪtra en haut de lâÃĐcran permettant le tÃĐlÃĐchargement (ainsi que la suppression comme avec lâicÃīne vue sur lâÃĐcran prÃĐcÃĐdent) :
 |
1-5-3-2-3. Utilisation de https▲
La clÃĐ privÃĐe (qui doit se nommer private.key) et la clÃĐ publique (qui doit se nommer public.crt) doivent Être placÃĐes dans le dossier de configuration par dÃĐfaut : .minio/certs (crÃĐÃĐ dans le dossier à partir duquel vous avez lancÃĐ min.io). Il est possible de prÃĐciser le chemin d'emplacement des clÃĐs avec l'option --cert.
La sÃĐcurisation de la connexion au serveur web de min.io est dÃĐtaillÃĐe dans cette page de documentation : https://docs.min.io/docs/how-to-secure-access-to-minio-server-with-tls.html.
1-5-4. Test en mode distribuÃĐ▲
Le mode distribuÃĐ nÃĐcessite la dÃĐclaration dâau minimum quatre sources dont au moins deux accessibles. Il est possible de dÃĐclarer plusieurs sources sur le mÊme nÅud. Cela n'aura un sens qu'en cas de sources sur diffÃĐrents disques (un peu comme du RAID).
Lâerasure code est un mÃĐcanisme permettant la redondance des donnÃĐes. Celui-ci utilise lâalgorithme de Reed Salomon et permet de gÃĐrer lâespace utilisÃĐ pour la redondance. Par exemple : avec douze disques, vous pourrez utiliser six disques de donnÃĐes et six de paritÃĐ ; ou bien dix disques de donnÃĐes et deux de paritÃĐ. Plus vous avez de disques de paritÃĐ, plus vous pourrez supporter de pertes de disques simultanÃĐs.
Pour crÃĐer un cluster distribuÃĐ, nous prÃĐparons deux volumes data1 et data2 (sur deux disques diffÃĐrents) sur un mÊme nÅud.
Minio refusera de dÃĐmarrer si les volumes dÃĐclarÃĐs sont sur le disque de dÃĐmarrage.
Nous stockons lâAccessKey et la SecretKey dans les variables dâenvironnement (reprise des clÃĐs prÃĐcÃĐdemment utilisÃĐes)Â :
export MINIO_ACCESS_KEY=XLI1NFFBHMAR5LFTTXD8
export MINIO_SECRET_KEY=+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzPuis appelons la commande :
./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4Qui retourne :
root@ubuntu:~# ./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4
Waiting for a minimum of 2 disks to come online (elapsed 3s)
Waiting for a minimum of 2 disks to come online (elapsed 6s)
Waiting for a minimum of 2 disks to come online (elapsed 9s)Il n'est pas possible de passer un volume prÃĐcÃĐdemment dÃĐmarrÃĐ en mode unique sans effacer les mÃĐtadonnÃĐes contenues dans le dossier .minio.sys prÃĐsent dans le volume prÃĐcÃĐdemment crÃĐÃĐ.
En mode distribuÃĐ, l'utilisation de clÃĐs d'accÃĻs est obligatoire.
Nous voyons que le cluster attend la disponibilitÃĐ dâau minimum deux disques pour dÃĐmarrer.
Installons un second hÃīte.
Le second serveur devra Être accessible en SSH sans demande de mot de passe.
Une fois lâexÃĐcutable minio copiÃĐ, les volumes data1 et data2 prÃĐparÃĐs, puis les variables MINIO_ACCESS_KEY et MINIO_SECRET_KEY positionnÃĐes, au 1er lancement sur le second hÃīte, nous verrons :
root@ubuntu:~# ./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Status: 4 Online, 0 Offline.
Endpoint: http://192.168.1.201:9000 http://127.0.0.1:9000
AccessKey: XLI1NFFBHMAR5LFTTXD8
SecretKey: +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Browser Access:
http://192.168.1.201:9000 http://127.0.0.1:9000
Command-line Access: https://docs.minio.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.201:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Object API (Amazon S3 compatible):
Go: https://docs.minio.io/docs/golang-client-quickstart-guide
Java: https://docs.minio.io/docs/java-client-quickstart-guide
Python: https://docs.minio.io/docs/python-client-quickstart-guide
JavaScript: https://docs.minio.io/docs/javascript-client-quickstart-guide
.NET: https://docs.minio.io/docs/dotnet-client-quickstart-guideLa commande minio doit donc Être lancÃĐe sur les deux machines.
1-5-4-1. Tests▲
Depuis lâinterface web, nous crÃĐons ensuite deux buckets et uploadons quelques fichiers dans chaque bucket.
Nous pouvons ensuite observer la prÃĐsence dâun dossier par bucket dans /data1 et dans /data2, sur les deux hÃītes. La rÃĐplication sâeffectue entre les deux disques locaux et sur les deux hÃītes. Nous avons donc quatre exemplaires visibles, rÃĐpartis sur deux hÃītes.
Nous pouvons ÃĐgalement observer que chaque fichier uploadÃĐ se prÃĐsente sous forme d'un dossier portant le nom du fichier et contenant un fichier part.1 (ou, selon la taille, plusieurs fichiers part.x) dans un dossier avec un nom reprÃĐsentant un UUID, et un fichier xl.meta. Le fichier part.1 nâest pas exploitable. LâaccÃĻs aux fichiers nâest donc pas possible sans passer par lâinterface web.
1-5-4-2. Passage en mode dÃĐmon▲
Nous allons installer minio en mode dÃĐmon. Nous commençons par fixer les variables dans le fichier /,etc/default/minio :
MINIO_VOLUMES=https://192.168.1.200/data1 https://192.168.1.201/data1 https://192.168.1.202/data1 https://192.168.1.203/data1
MINIO_ACCESS_KEY=XLI1NFFBHMAR5LFTTXD8
MINIO_SECRET_KEY=+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzNous allons ensuite utiliser le script de laudukang :
[Unit]
Description=Minio
Documentation=https://docs.minio.io
Wants=network-online.target
After=network-online.target
AssertFileIsExecutable=/usr/local/bin/minio
[Service]
WorkingDirectory=/usr/local
User=root
Group=root
PermissionsStartOnly=true
EnvironmentFile=-/etc/default/minio
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_VOLUMES}\" ]; then echo \"Variable MINIO_VOLUMES not set in /etc/default/minio\"; exit 1; fi"
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_ACCESS_KEY}\" ]; then echo \"Variable MINIO_ACCESS_KEY not set in /etc/default/minio\"; exit 1; fi"
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_SECRET_KEY}\" ]; then echo \"Variable MINIO_SECRET_KEY not set in /etc/default/minio\"; exit 1; fi"
ExecStart=/usr/local/bin/minio server $MINIO_OPTS $MINIO_VOLUMES
# Let systemd restart this service only if it has ended with the clean exit code or signal.
Restart=on-success
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop Minio
KillSignal=SIGTERM
SendSIGKILL=no
SuccessExitStatus=0
[Install]
WantedBy=multi-user.target
# Built for ${project.name}-${project.version} (${project.name})Nous pouvons voir que le dÃĐmon attend la commande minio dans /usr/local/bin et en utilisateur root, ce que vous pouvez changer si vous le souhaitez. Nous pouvons ÃĐgalement voir que le script rÃĐcupÃĻre les variables dans /,etc/default/minio.
Nous plaçons donc le script dans le fichier /etc/systemd/system/minio.service avec les droits 755.
Nous enregistrons ensuite le service :
systemctl daemon-reload
systemctl enable minioCe qui renvoie :
Created symlink from /etc/systemd/system/multi-user.target.wants/minio.service to /etc/systemd/system/minio.service.
root@ubuntu:~#Nous arrÊtons ensuite min.io sur les deux machines et lançons le service sur les deux hÃītes, aprÃĻs avoir effectuÃĐ la copie des fichiers de configuration d'une machine à l'autre.
Pour utiliser le mode https, il faudra ajouter la ligne suivante :
MINIO_OPTS=Â "-C /,etc/minio"puis copier les clÃĐs .key et .crt dans le dossier /,etc/minio/certs.
1-5-5. Client min.io▲
Pour accÃĐder aux buckets min.io depuis la ligne de commande, nous pouvons utiliser le client min.io nommÃĐ mc (ne pas confondre avec Midnight Commander) tÃĐlÃĐchargeable à lâadresse :
https://dl.min.io/client/mc/release/linux-amd64/mc
Un simple appel sans paramÃĻtres donnera la liste des options :
~# ./mc
mc: Configuration written to `/root/.mc/config.json`. Please update your access credentials.
mc: Successfully created `/root/.mc/share`.
mc: Initialized share uploads `/root/.mc/share/uploads.json` file.
mc: Initialized share downloads `/root/.mc/share/downloads.json` file.
NAME:
mc - Minio Client for cloud storage and filesystems.
USAGE:
mc [FLAGS] COMMAND [COMMAND FLAGS | -h] [ARGUMENTS...]
COMMANDS:
ls list buckets and objects
mb make a bucket
cat display object contents
pipe stream STDIN to an object
share generate URL for temporary access to an object
cp copy objects
mirror synchronize object(s) to a remote site
find search for objects
sql run sql queries on objects
stat show object metadata
diff list differences in object name, size, and date between two buckets
rm remove objects
event configure object notifications
watch listen for object notification events
policy manage anonymous access to buckets and objects
admin manage minio servers
session resume interrupted operations
config configure minio client
update update mc to latest release
version show version info
GLOBAL FLAGS:
--config-dir value, -C value path to configuration folder (default: "/root/.mc")
--quiet, -q disable progress bar display
--no-color disable color theme
--json enable JSON formatted output
--debug enable debug output
--insecure disable SSL certificate verification
--help, -h show help
--version, -v print the version
VERSION:
RELEASE.2018-12-27T00-37-49ZNous reconnaissons les commandes classiques du shell.
Nous commençons par crÃĐer un alias pour faciliter lâaccÃĻs, et comme indiquÃĐ lors de lâappel à la commande minio server :
mc config host add minioalias http://192.168.1.200:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzCe qui retourne :
mc: Configuration written to `/root/.mc/config.json`. Please update your access credentials.
mc: Successfully created `/root/.mc/share`.
mc: Initialized share uploads `/root/.mc/share/uploads.json` file.
mc: Initialized share downloads `/root/.mc/share/downloads.json` file.
Added `minioalias` successfully.Nous pouvons consulter le contenu de lâhÃīte via la commande mc ls suivi du nom de lâalias :
~# ./mc ls minioalias
[2018-12-27 13:49:34 CET] 0B dossier1/
[2018-12-27 13:49:51 CET] 0B dossier2/
~#La commande cp permettra de copier des fichiers dans le cluster ou dâen rÃĐcupÃĐrer depuis celui-ci.
Il nây a pas de notion de sous-dossier avec min.io. Par contre, si vous copiez le fichier fichier.txt avec la commande suivante :
./mc cp fichier.txt minioalias/dossier1/textes/fichier.txtvous pourrez voir lâarborescence texte.
Si vous copiez plusieurs fichiers dans le chemin minioalias/dossier1/textes, vous pourrez les voir avec la commande ./mc ls minioalias/dossier1/textes.
1-5-6. Fonctionnement en mode S3▲
Pour cet usage, jâai testÃĐ s3fs qui permet de monter un volume S3 avec FUSE.
Il va nous falloir crÃĐer un fichier /etc/passwd-s3fs pour la connexion de la forme identifiant:clÃĐ
Dans notre cas, ce sera :
XLI1NFFBHMAR5LFTTXD8:+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzEnsuite, le volume peut Être montÃĐ avec s3fs :
s3fs <nom du bucket> /mnt -o use_path_request_style,url=http://192.168.1.200:9000Ã partir de ce point de montage, le Bucket est accessible comme nâimporte quel autre point de montage.
1-5-7. Sauvegarde▲
Pour les sauvegardes, le plus simple est de sauvegarder depuis un point de montage s3fs.
1-5-8. Test dâarrÊt dâun des serveurs▲
Lors de lâarrÊt dâun des serveurs, les donnÃĐes restent accessibles, mais en lecture seule. AprÃĻs redÃĐmarrage du serveur, la situation se dÃĐbloque.
1-5-8-1. Perte dÃĐfinitive dâun serveur▲
La situation ne revient pas à la normale mÊme si vous prÃĐparez un nouveau serveur en copiant les fichiers /usr/local/bin/minio, /,etc/default/minio, recrÃĐant les points de montages data1 et data2.
Je commence par crÃĐer un alias pour la commande mc pointant sur le serveur fonctionnel :
~# ./mc config host add minioalias http://192.168.1.200:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Added `minioalias` successfully.Je lance la rÃĐparation avec la commande ./mc admin heal minioalias :
~# ./mc admin heal minioalias
â dossier2
0/0 objects; 0 B in 3s
ââââââââââŽââââŽââââââââââââââââââââââ
â Green â 4 â 100.0% ââââââââââââ â
â Yellow â 0 â 0.0% â
â Red â 0 â 0.0% â
â Grey â 0 â 0.0% â
ââââââââââīââââīââââââââââââââââââââââCeci va recrÃĐer lâarborescence, mais ne suffira pas pour les fichiers
Il faudra ajouter la commande ./mc admin heal minioalias --recursive.
Vous verrez dÃĐfiler le nom des fichiers, la console restant sur le dernier fichier synchronisÃĐ.
~# ./mc admin heal minioalias --recursive
â dossier2/pydio.pdf
7/7 objects; 2 MiB in 6s
ââââââââââŽâââââŽââââââââââââââââââââââ
â Green â 11 â 100.0% ââââââââââââ â
â Yellow â 0 â 0.0% â
â Red â 0 â 0.0% â
â Grey â 0 â 0.0% â
ââââââââââīâââââīââââââââââââââââââââââ1-5-9. Ajout de serveur▲
Pour ajouter un serveur supplÃĐmentaire, il faudra modifier le fichier /,etc/default/minio sur les deux serveurs existants (ajout dans la ligne MINIO_VOLUMES= du fichier /,etc/default/minio).
1-6. Bilan▲
GlusterFS est une solution souple et relativement simple. Je n'utiliserais pas la mÃĐthode DRBD/OCFS, car la dÃĐsynchronisation est trop facile, et la nouvelle version, paraissant plus souple, m'a posÃĐ des difficultÃĐs (mais il s'agit ici d'un point de vue personnel).
La solution Ceph est complexe, mais offre lâavantage de s'autorÃĐparer en cas de problÃĻme. Ceph est adaptÃĐ aux solutions à grande ÃĐchelle et est utilisÃĐ par OpenStack, OpenNebula. Elle reste complexe à mettre en place, mais fait rÃĐfÃĐrence.
1-7. Quid de Windows ?▲
Il est possible de gÃĐrer un systÃĻme de fichiers distribuÃĐs avec Windows via un Active Directory en utilisant DFSR (Distributed FileSystem Replication).
DFS permet de faire de la rÃĐpartition de donnÃĐes (une partie sur chaque serveur, vue à partir dâun seul point d'accÃĻs) ou de la redondance en rÃĐpliquant les donnÃĐes d'un serveur à un autre.
Il faudra sur un Windows Server avec Active Directory fonctionnel installer le rÃīle ÂŦÂ RÃĐplication DFSÂ Âŧ, puis depuis le menu outil du gestionnaire de serveurs aller dans ÂŦÂ Gestion du systÃĻme de fichiers distribuÃĐs DFSÂ Âŧ.
Dans le gestionnaire DFS qui va s'ouvrir, il va falloir faire un clic droit sur Espace de nomsâ Nouvel espace de noms.
Une fois l'espace de nom crÃĐÃĐ, il faudra ajouter les dossiers cibles de chaque serveur.
Vous pourrez sÃĐlectionner une rÃĐplication en temps rÃĐel ou planifier la frÃĐquence.
1-8. Quid de Mac OS XÂ ?▲
Mac OS X ou mac OS Server ne proposent aucun systÃĻme de fichiers distribuÃĐs. Il pourra se connecter à un DFS Active Directory.
Pour se rÃĐfÃĐrer à ce qui a ÃĐtÃĐ vu dans ce tutoriel, GlusterFS n'est actuellement pas compatible Mac OS.
Il est possible de compiler Ceph via Homebrew, mais cela me parait trop expÃĐrimental pour une utilisation en production.
2. Conclusion▲
J'espÃĻre que ce tutoriel vous a ÃĐclairÃĐ sur les systÃĻmes de fichier distribuÃĐs.
3. Remerciements▲
Je remercie Mickael Baron, khayyam90, LittleWhite, et Louis-Guillaume Morland pour leur relecture technique.
Je remercie Claude Leloup pour sa relecture orthographique.