

1. Introduction : Qu'est-ce que le cloud ?▲
Le cloud computing ou informatique dans les nuages peut être vu comme la dématérialisation totale ou partielle des systèmes informatiques.
C'est un terme qui regroupe beaucoup de choses, rendant ses aspects flous comme les nuages formant du brouillard. Le but de ce tutoriel est de sortir de ce brouillard concernant le cloud.
Le cloud computing est donc un ensemble de services vous fournissant pour l'aspect grand public :
- un hébergement web (Apache/PHP/MSQL) ;
- l'hébergement de vos mails/contacts/agendas ;
- un espace de stockage/synchronisation partagé ou non ;
- une application métier.
Pour l'aspect professionnel :
- des serveurs virtuels avec redondance, répartition de charge et possibilité d'augmentation de puissance (temporaire ou non) pour supporter une montée en charge ;
- des espaces de stockage en mode bloc ou en mode objet ;
- des espaces de stockage et de bases de données distribués pour le big data notamment.
Dans les deux cas, toutes les ressources seront virtualisées, sauf dans le cas où vous louez un emplacement de baie dans un datacenter pour y placer vos propres machines.
Vos services fonctionneront en général sur une ferme de serveurs dont les capacités allouées peuvent changer avec le temps (en termes de puissance, d'espace de stockage, de bande passante). Ces serveurs peuvent être répartis ou répliqués dans plusieurs centres de données (data-center), c'est même indispensable pour les services de haute disponibilité.
Ceci vous permet de louer des services externalisés et/ou du matériel et ainsi de ne pas avoir à les gérer.
Avec le cloud, on ne vous fournit pas du matériel (bien que ce soit possible), mais plutôt de la ressource d'accès à celui-ci.
Ce tutoriel est composé de quatre parties :
- une présentation des services cloud grand public les plus connus ;
- une présentation des services cloud professionnels ;
- une présentation de solutions d’autohébergement pouvant être utilisées (ou non) en mode cloud ;
- une présentation des différentes briques constituant le cloud vous permettant une meilleure compréhension et éventuellement une mise en place de solutions adaptées à votre besoin.
1-1. Pourquoi ai-je besoin du cloud ?▲
Vous aurez besoin de services cloud si vous souhaitez avoir un accès permanent à vos services depuis n'importe où, ou si vous souhaitez avoir une sauvegarde sur Internet permanente.
Pour accéder par exemple à un serveur de fichiers dans une entreprise, il n'est pas forcément nécessaire d'utiliser une solution cloud, un VPN permettant d'entrer sur le réseau interne de l'entreprise pouvant suffire. Une solution cloud sera justifiée si vous souhaitez dématérialiser vos serveurs internes.
1-2. Nomenclature▲
Vous trouverez ci-dessus une définition des termes qui reviendront régulièrement dans ce tutoriel.
- Datacenter : un datacenter ou centre de données est un lieu où vont être regroupés des serveurs installés dans des baies informatiques. À cela viendra s'ajouter une infrastructure réseau, un système de climatisation adapté, des systèmes anti-incendies, anti-intrusions, une alimentation électrique redondante et sécurisée par groupe électrogène. Vous y louerez soit des serveurs soit un emplacement (un quart, un tiers de baie) pour y placer vos équipements et vous permettant de bénéficier de l'infrastructure (réseau, électrique, climatisation).
- Virtualisation : en informatique, la virtualisation consiste en une abstraction des ressources. Une machine virtuelle contient un système d'exploitation exécuté sur un hôte nommé hyperviseur. Avec la virtualisation, il est par exemple possible d’exécuter un Windows virtualisé depuis un serveur Linux exécutant un hyperviseur. L'inverse est également possible, Hyper-V, hyperviseur de Microsoft peut exécuter des machines virtuelles Linux dans Windows.
-
Hyperviseur : ordinateur ayant des capacités de virtualisation (support de la virtualisation par le CPU) et exécutant un logiciel de virtualisation nommé hyperviseur. (comme VMWare, KVM, VirtualBox). Il existe deux types d'hyperviseurs :
- hyperviseur de type 1 ou bare metal : celui-ci ne va servir qu'à exécuter et gérer des machines virtuelles (VMWare ESX, KVM, Xen) ;
- Hyperviseur de type 2 : un logiciel hyperviseur va s’exécuter sur un système d'exploitation. Le gestionnaire de machines virtuelles et les machines virtuelles peuvent être considérés comme des applications exécutées sur l'OS hôte (VirtualBox, VMWare Workstation).
- Conteneur : un conteneur consiste en la virtualisation d'une application ou d'un service. Plus léger qu'une machine virtuelle, un conteneur va utiliser le noyau du système d'exploitation qui l'accueille en cloisonnant les ressources. Docker est un système de gestion de conteneurs faisant référence.
- Network Attached Server (NAS) : il s'agit d'un serveur dédié au stockage, en général un boîtier contenant des disques accessibles sur le réseau via les protocoles classiques de partage de fichiers. Ceux-ci auront alors des fonctions plus ou moins avancées allant du simple partage de fichiers à des fonctions rivalisant avec un serveur d'entreprise.
- Storage Area Network (SAN) : il s'agit d'un réseau de stockage de données bas niveau. Les SAN fournissent des accès en mode blocs. Exemple, une baie de disque qui sera accessible à une ou plusieurs machines.
- Distributed File System (DFS) : il s'agit d'un système de fichiers réparti sur plusieurs machines. Le client (utilisateur ou matériel y accédant) n'a pas notion de cette répartition. Ce type de système est souvent associé à un mécanisme de redondance.
- Redondance : la redondance consiste à dupliquer les composants (matériels et/ou logiciels) de façon à garantir le fonctionnement d'un système en cas de défaillance d'un composant, ceci de façon transparente.
1-3. Les différents modules cloud▲
Les services cloud se présentent en plusieurs couches dont voici les principales.
- Infrastructure as a Service (infrastructure en tant que service, IaaS) : ce service est celui de plus bas niveau. Par exemple, il consiste en la mise à disposition de machines virtuelles, de conteneurs, de systèmes de fichiers distribués, de NAS/SAN. La partie « matérielle » (les différentes machines, l'infrastructure réseau et de répartition de charge) est sous la responsabilité du fournisseur de services.
- Platform as a Service (plateforme en tant que service, PaaS) : ce type de service fournit le système d'exploitation, le ou les moteurs de base de données et peut donner ou non la liberté d'installer des logiciels. Les logiciels peuvent aussi être préinstallés.
- Software as a service (logiciel en tant que service, SaaS) : à ce niveau, ce sont les applications qui sont proposées. On peut citer Microsoft Office 365 (pour la partie modification en ligne de documents, ou le logiciel installé sur votre poste), Google Docs, ou tout simplement un hébergement web.
D'autres couches peuvent être fournies telles que le Desktop as a Service (bureau virtuel en tant que service), le Storage as a Service (stockage en tant que service), la première étant haut niveau (SaaS), la seconde bas niveau (IaaS).
Les différentes briques IaaS, PaaS, SaaS peuvent être vues comme des briques mises en commun pour fournir la solution qui vous sera proposée ou que vous mettrez en place. Les différentes couches s’imbriquent comme des poupées russes et peuvent être comparées au modèle de couches OSI.
|
|
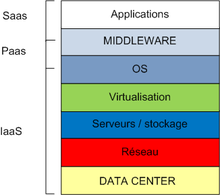
La fourniture et la maintenance des couches IaaS et PaaS sont à la charge du fournisseur de service.
Avantages :
- gestion externalisée du matériel et de sa maintenance, facilité de montée en charge ;
- accessibilité depuis n'importe où ;
- synchronisation en temps réel ou différé en cas de rupture de liaison, par exemple des services tels que Dropbox ou Google Drive.
Inconvénients :
- captivité possible par rapport au produit utilisé et à Internet. En cas de coupure de liaison, aucune activité n’est possible ;
- la migration vers un autre fournisseur de services peut être compliquée. Cette contrainte a tendance à disparaître ;
- coûts d’utilisation pouvant être cachés ou difficiles à maîtriser, notamment si la facturation repose sur la bande passante ou l’espace utilisé, etc. ;
- exposition plus importante aux risques de piratage si tous les services d’une entreprise sont accessibles depuis Internet ;
- solution cadrée : vous n'aurez pas forcément accès à des réglages bien précis (c'est aussi un avantage pour la simplification de l'administration).
Cette liste est non exhaustive.
1-4. Cloud public/privé/hybride▲
Le cloud privé consiste en un cloud dont les ressources vous sont dédiées. Il peut s'agir de votre propre matériel dans vos locaux, d’un matériel hébergé dans un centre de données dont vous louez une baie ou un équipement spécifique, ou d’un droit d’accès à l'infrastructure de votre hébergeur.
Dans le cloud public, vous utilisez des services mutualisés dans des fermes de serveurs. Évidemment, seules vos données vous sont accessibles et ne le sont qu'à vous, mais les ressources matérielles/système peuvent être partagées entre plusieurs clients. Vous formez votre infrastructure selon le cadre qui vous est fourni. Il s'agit d'un cloud managé.
Un cloud privé virtuel peut être déployé dans un cloud public.
Le cloud hybride, quant à lui, correspond à l'utilisation mixte d’un cloud public et d’un cloud privé. Par exemple, il peut s'agir de répartition de services entre plusieurs cloud, de redondance entre vos locaux et un centre de données, d'une partie de services externalisés communiquant avec des services internes par le biais de standards facilitant la communication.
2. Les services cloud grand public les plus connus▲
- Dropbox : service de synchronisation et partage de fichiers, gratuit jusqu’à 2 Go. Une interface d’administration est fournie pour les usages multicomptes professionnels. Dropbox propose une synchronisation sélective permettant de ne stocker sur un poste que certains dossiers. Dans ce cas, les dossiers non sélectionnés ne seront accessibles qu'en ligne ou que sur les postes ne les ayant pas décochés ; l'intégralité des données restant accessibles depuis l'interface web. À l’installation, il vous sera proposé de stocker les données sur votre poste ou de ne les stocker qu'en ligne. Dans les deux cas, vous verrez vos fichiers dans l'explorateur de fichiers.
- Google G-Suite : il s'agit des services de la suite Google (Gmail, Google Drive, Google Agenda, YouTube, Maps, Forms…). Il y a également une interface d'administration pour les usages professionnels. L'espace de stockage est de 30 Go par utilisateur dans un espace professionnel G-Suite. En offre grand public, vous avez 15 Go d'espace de stockage. En version professionnelle, vous aurez accès à Google File Stream. Ce service permet de stocker des données uniquement en ligne (avec possibilité de cache local), comme avec DropBox. Il est possible dans les deux cas d'étendre l'espace de stockage. Celui-ci vous sera facturé. L'usage personnel propose un outil nommé « Google sauvegarde et synchronisation » effectuant comme son nom l'indique la synchronisation de vos données entre votre poste et le compte Google.
- Apple iCloud : service de synchronisation Apple, permettant de synchroniser les contacts, agendas, mots de passe entre les iPad, iPhone et les ordinateurs mac. Les dernières versions (depuis Mac OS X 10.12) permettent également la synchronisation du dossier Documents et du bureau. Le service est gratuit jusqu'à 5 Go. Il existe une version sur Windows permettant la synchronisation avec Outlook, l’espace iCloud pour les documents et les photos.
- Microsoft OneDrive/365 : synchronise les comptes utilisateurs entre les postes fonctionnant sur Windows 10 et les documents pour les systèmes antérieurs. Sous Windows 10, il est en théorie possible d'ouvrir une session sur un ordinateur tiers et de retrouver son environnement de travail. La partie emails et calendriers est gérée par Office 365 (en fait des comptes Exchange sur les serveurs de Microsoft), service à part. Un compte Office 365 peut ou non intégrer une licence Office 365 (il s'agit de la dernière version d'Office en mode location avec un espace de stockage OneDrive). Microsoft s'oriente vers la suite Microsoft 365, incluant les services Office 365, OneDrive, avec une licence Windows 10 incluse, et des services équivalents à ceux fournis par un Windows Server pour la version business : déploiement, stratégie de sécurité (restriction de copie de documents, réinitialisation appareils à distance).
- WeTransfer : service de partage de fichiers dont la validité est temporaire. WeTransfer fournit un lien permettant le téléchargement du fichier téléversé. Ce lien reste valide quelques jours seulement. La version payante WeTransfer Pro permet de garder en ligne jusqu'à 100 Go et de les retransférer. Ce service est essentiellement utilisé pour transférer des fichiers trop volumineux pour être envoyé par mail, son but premier n'est pas d'effectuer du stockage à long terme, même s'il s'agit d'un service cloud. Il est fort probable que vous ayez déjà utilisé ce service pour envoyer ou recevoir des fichiers trop volumineux pour le mail.
Ce type de service peut être vu comme du SaaS (Software as a Service), le plus haut niveau dans les services Cloud. Ces services ne nécessitent pas ou peu de compétences techniques.
3. Les services cloud pour les professionnels : Le cloud à grande échelle▲
Les clouds à grande échelle présentés ci-dessous concernent principalement les entreprises. Ces services seront utilisés par des informaticiens et nécessitent des compétences techniques.
Les services suivants vous proposeront dans une console d'administration globalement la même nomenclature de briques pour réaliser votre cloud :
compute : gestion de ressources, avec notamment la gestion des machines virtuelles ;
storage : gestion de l'espace de stockage ;
network : la gestion réseau, avec en général un réseau interne pour l'interconnexion entre ressources, et un réseau public pour la communication extérieure.
Chacun des services présentés ci-dessous pourrait faire l'objet d'un article à part. Je n'ai malheureusement pas les ressources pour les présenter de façon étendue.
3-1. OpenStack▲
OpenStack est un projet conjoint de la société Rackspace (acteur majeur des services cloud depuis des années) et de la NASA. L’intérêt principal d'OpenStack est de pouvoir fonctionner sur du matériel standard et hétérogène.
OpenStack est adapté aux infrastructures d'envergure, et est utilisé par OVH, le premier hébergeur européen pour son cloud public.
OpenStack est un ensemble de briques mises en commun pour utiliser une infrastructure cloud. Voici les briques principales :
Nova : gère les ressources de calcul (compute). C'est Nova qui va contrôler les hyperviseurs sur les machines physiques (et maintenant les gestionnaires de conteneurs comme Docker ou LXC) ;
Swift : c'est le système de stockage objet d'OpenStack (storage). Les données sont stockées sous forme d'objets (un fichier va être éclaté en plusieurs objets du point de vue bas niveau). Swift va gérer la redondance des données (réplication, répartition, autoréparation, ajout d'espace de stockage) ;
Cinder : Cinder est l'équivalent de Swift, mais en mode bloc (storage). Il va gérer l'attachement/détachement des périphériques virtuels, la gestion de snapshots ;
Neutron : c'est la brique qui va gérer le réseau : attribution d'IP, création de vswitch, etc. ;
Keystone : c'est le service qui va gérer les identités et autorisations ;
Glance : c'est le service de gestion d'images disque. Ce service va distribuer des images disque aux instances : modèles de disque, fichiers OVF.
Il s'agit là des briques les plus importantes.
OpenStack comporte des API pour communiquer avec les services EC2 et S3 d'Amazon.
Vous pouvez consulter ce tutoriel sur OpenStack. Ou vous rendre sur le site
3-2. VMWare▲
VMWare est un acteur historique dans le monde de la virtualisation.
Oubliez les anciennes dénominations telles que ESX/ESXi au profit de VMWare vSphere.
La version vSphere gratuite se nomme VMWare vSphere Hypervisor, il s'agit en fait d'une version bridée de vSphere ne permettant l'utilisation que de la partie hyperviseur, suffisant dans le cadre de la gestion de trois ou quatre machines virtuelles, pour une petite structure.
Dans le cadre d'une utilisation payante, VMWare vSphere vCenter Server sera une machine virtuelle, installée sur un de vos hyperviseurs, qui gérera votre centre de données de façon globale. Vos hyperviseurs viendront s'intégrer dans une gestion centralisée. Certaines opérations ne seront alors faisables que depuis l'interface centralisée, d'autres pourront être effectuées depuis l'interface web de l'hyperviseur ou depuis l’interface web vCenter (les réglages seront alors visibles depuis l'une ou l'autre des interfaces). Vous pourrez facilement migrer à chaud une machine virtuelle d'un hyperviseur à un autre, et même d'un hyperviseur Intel vers un hyperviseur AMD (sous certaines conditions avec Enhanced vMotion Compatibility).
Dans VMWare vCenter Server, vous aurez une vision globale :
- des hyperviseurs ;
- des datastores ;
- des réseaux.
|
|
VMWare est utilisé en usage privé hors nuage, mais peut aussi servir de socle dans un ou des centres de données.
Dans le cadre d'une solution de cloud, le produit utilisé sera VMWare vCloud Suite, qui regroupe vSphere avec vRealize Suite, outil destiné à la modélisation et au provisionnement de projet.
3-3. Amazon Web Service (AWS)▲
Amazon propose une multitude de services de cloud computing, le plus connu étant S3 (Amazon Simple Storage Service). Dropbox utilisait auparavant S3. Amazon propose aussi une offre grand public, reposant sur S3, nommée Amazon Drive. Dans certains pays (mais pas la France), Amazon propose une offre gratuite et met à disposition 5 Go. Il existe aussi le service Amazon Prime Photo : un service Amazon Drive dédié aux photos.
Amazon fournit des briques de virtualisation, dont les plus connues sont :
- EC2 : Elastic Compute Cloud ;
- S3 : Simple Storage Service.
Vous pourrez gérer votre infrastructure depuis une interface web.
EC2 vous fournira des serveurs virtuels utilisant Xen, avec répartition de charge (load balancing).
S3 fournit un accès aux données en mode SOAP, REST, BitTorrent, mais peut aussi être utilisé par des API pour simuler un système de fichiers. Une machine virtuelle utilisera plutôt un stockage en mode bloc (EBS pour Amazon Elastic Bloc Store).
Pour ce type d'offre, il faudra porter particulièrement attention à la tarification. Celle-ci dépendra de la puissance, de la taille de l'espace de stockage, du nombre d'accès (nombre lectures/écritures et/ou accès réseau).
Ceci a l’avantage de vous permettre d'augmenter votre puissance temporairement ou définitivement, de la réduire, et donc de vous adapter rapidement aux besoins.
L'inconvénient étant la nécessité de maîtrise des coûts.
Vous pourrez migrer vos machines virtuelles vers Amazon à l'aide de AWS Server Migration Service.
3-4. Microsoft Azure▲
Les services Microsoft Azure sont comparables aux services fournis par Amazon avec lesquels ils sont en concurrence. Vous pourrez intégrer bien évidemment facilement tous les produits Microsoft.
Azure Migrate vous permettra de facilement migrer vos machines virtuelles locales vers Azure.
Bien qu'Azure soit une technologie Microsoft, il est tout à fait possible d'y utiliser des machines virtuelles Linux. Scott Guthrie, vice-président exécutif cloud et IA chez Microsoft, déclarait en 2018 : « Près de la moitié des machines Azure sont sous Linux ».
Le service propose en plus de l'interface web « Azure (remote) PowerShell » qui permet d'effectuer les opérations en ligne de commande et de façon scriptée. Azure Migrate Server Assesment permet de migrer des machines virtuelles Hyper-V vers Azure.
Un tutoriel sur Microsoft Azure.
La même règle de précaution que pour AWS est à appliquer en termes de tarification.
3-5. Oracle Cloud Infrastructure▲
Oracle est à l'origine une entreprise spécialisée dans la base de données. Oracle a racheté Sun qui proposait VirtualBox, hyperviseur de type 2, gratuit.
Oracle est arrivé sur le tard dans le monde du cloud par rapport à AWS ou Azure. Leur interface va proposer globalement le même type de services que ses concurrents.
Tout comme Microsoft facilite l'intégration de ses différents produits dans son cloud, Oracle va faciliter l’intégration des siens dans son cloud, notamment ses produits de bases de données.
Il est possible depuis les versions 6 de VirtualBox d'uploader une machine virtuelle vers le cloud Oracle. Il faudra auparavant préparer celle-ci (voir la documentation), et l'upload devra se faire lorsque la machine virtuelle est arrêtée. Vous pourrez aussi importer une machine virtuelle du cloud, ou directement en créer une dans le cloud Oracle depuis VirtualBox. Il est également possible de télécharger une machine virtuelle du cloud Oracle dans VirtualBox.
Le même principe de précaution au niveau de la tarification des ressources est à appliquer.
3-6. Google Cloud Platform▲
Les services fournis par Google sur leur infrastructure Google Cloud Platform s'appuient sur la même infrastructure utilisée par G-Suite. Ils vous fourniront le même type de services que ses concurrents.
La grosse différence de Google étant la fourniture de l'infrastructure G-Suite sur leurs services.
La même de précaution au niveau de la tarification des ressources est à appliquer.
3-7. Hadoop▲
Hadoop est un framework open source fourni par l’Apache Fundation. Ce framework est destiné au traitement de données de très gros volumes en facilitant la création d'applications distribuées. Il est utilisé dans les traitements big data.
Il se décompose en deux parties principales :
- HDFS : Hadoop Distributed File System : il s'agit du système de fichiers distribués stockant les données ;
- MapReduce : il s'agit du module de traitement de données proprement dit (composé de la fonction Map qui va effectuer la répartition du traitement et de Reduce qui réduira le résultat en une seule synthèse).
À cela peut être ajouté un module nommé Hbase, SGBD distribué non relationnel orienté colonnes.
Les principaux acteurs du cloud (Google, Amazon, OVH, etc.) sont en mesure d'offrir des instances Hadoop à leurs clients.
Hadoop n'est pas adapté à n'être utilisé qu'en système de fichiers.
4. Les solutions d’autohébergement (utilisable en cloud)▲
Seront abordés ici des solutions d’autohébergement toutes faites que vous pourrez utiliser en interne avec ouverture ou non sur l’extérieur. On ne pourra alors pas parler de cloud dans ce cas, mais uniquement d’autohébergement. Ces solutions sont également utilisables sur une infrastructure hébergée dans un datacenter, bien que ce ne soit pas le but premier.
Ces solutions pourront être adaptées à de l'utilisation répartie sur plusieurs machines après avoir lu les chapitres suivants à partir du chapitre sur les briques minimales.
4-1. Les NAS▲
Comme déjà évoqué NAS signifie Network Attached Storage que l'on peut traduire par stockage attaché au réseau. Ce stockage va en général contenir des disques montés en RAID afin de sécuriser les données au niveau matériel.
Au fur et à mesure de l'évolution, certains de ces NAS ont évolué vers des solutions offrant plus de fonctionnalités. Nous allons voir ci-dessous certains NAS ayant des fonctions avancées. Ils ne représentent qu'une partie des solutions NAS existant sur le marché.
Un NAS a pour première fonction de servir d'espace de stockage de type fichiers, pas d'être exposé sur Internet, même si cela est tout à fait possible.
4-1-1. Solutions NAS Synology▲
|
|
|


L'usage premier des équipements Synology était des NAS. Au fur et à mesure de l'évolution de leurs produits, ceux-ci apportent maintenant l'équivalent d'une solution comme Yunohost via leur interface DSM (Disk Station Manager) facile à utiliser. Vous pourrez facilement étendre l'espace disque en changeant ceux-ci ou en ajoutant. Une partie de l'espace disque est réservée à la redondance des données (RAID). Vous pourrez également ajouter des baies d'extension permettant l'ajout de disques supplémentaires. Tout le paramétrage se fait via une interface web.
L'accès depuis l’extérieur est facilité, de par un accès possible aux données en HTTPS avec un explorateur de fichiers accessible dans l'interface web fournie par Synology. Un serveur VPN est intégré. Synology fournit aussi une application nommée QuickConnect qui vous permettra, après création d'un compte, d'accéder à votre NAS via leur infrastructure (votre NAS se connectant à l'infrastructure Synology, qui fera le relais).
Vous pourrez sur les modèles le permettant créer des machines virtuelles.
Vous aurez ici une vision des applications proposées.
Vous pouvez tester DSM en ligne depuis le site de Synology.
Cette solution restera quand même plus fermée par exemple que Yunohost, car le système d'exploitation DSM n'est pas libre et reste quand même cloisonné, et nécessite l'utilisation d'un NAS Synology.
Certains hébergeurs proposent des solutions clé en main sur Synology. Il existe des modèles rackables pour les professionnels dont la configuration rivalise avec des serveurs accueillant habituellement des solutions Windows ou Linux, tout comme des modèles grand public à prix abordables.
Vous pouvez retrouver sur Developpez.com un dossier montrant l'utilisation d’un NAS de Synology.
4-1-2. Les NAS Qnap▲
|
|
|


Qnap est un peu moins connu que Synology par les particuliers et propose des fonctionnalités similaires. Le système embarqué dans les NAS QNAP se nomme QTS.
Vous pouvez retrouver sur Developpez.com un dossier montrant l'utilisation de QNAP.
4-1-3. FreeNAS/TrueNAS▲
|
|

FreeNAS est une distribution FreeBSD basée sur M0n0wall, distribution FreeBSD destinée à servir de pare-feu dans un système embarqué.
FreeNAS fournit également des NAS physiques incluant leur système.
FreeNAS est une solution conçue pour fonctionner sur une carte flash ou une clé USB. L'usage premier étant d'être utilisé dans un système embarqué, mais rien n'empêche de l'utiliser sur une machine standard. Il est fourni sous forme d'ISO.
Le projet est en train de changer de nom et va devenir TrueNAS (TrueNAS core pour être précis). TrueNAS est la version payante de l'éditeur de FreeNAS, les deux versions partagent 95 % de code commun. Les prochaines versions devraient être basées sur Debian plutôt que FreeBSD.
Il existe une édition TrueNAS Entreprise qui est une version dual-node, la version TrueNAS SCALE permettra la gestion multinode. Cette dernière est encore en phase de développement et non recommandée par TrueNAS en production à ce jour.
La version testée est la version FreeNAS 11.
Bien que FreeNAS/TrueNAS puisse être installé dans une machine virtuelle, ce n'est pas son but premier.
4-1-3-1. Installation▲
Rappel : FreeNAS recommande l'installation sur une mémoire Flash.
Lors du démarrage de l'ISO FreeNAS, vous aurez les écrans suivants :
|
|
|
|
Vous devrez ensuite sélectionner le disque où installer FreeNAS :
|
|
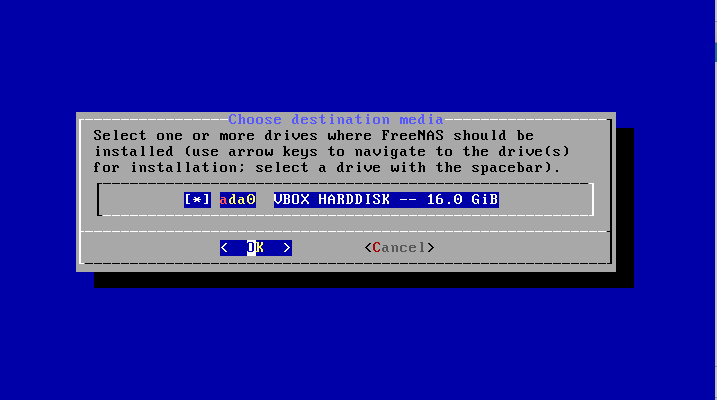
Ceci effacera l'éventuel contenu du disque, ce qui vous sera indiqué.
Il ne sera pas possible de mettre des données sur le volume contenant l'installation FreeNAS.
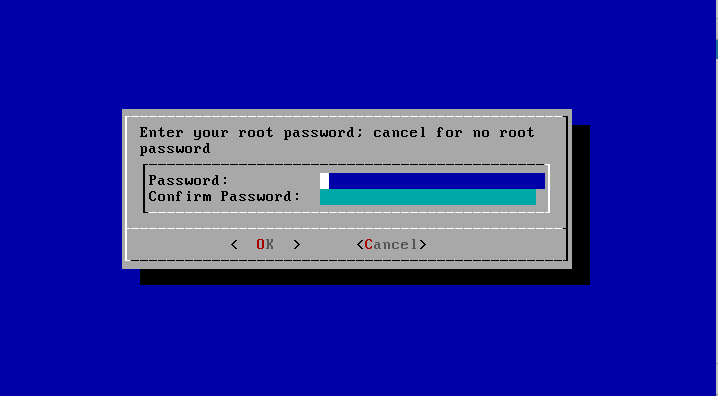
Vous sera ensuite demandé le mot de passe root :
|
|
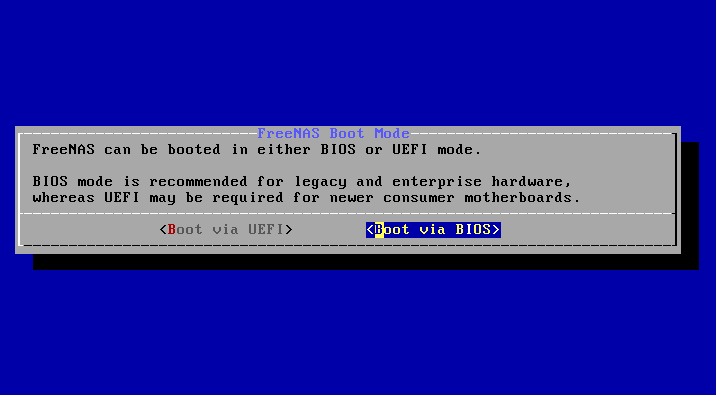
Il faudra ensuite sélectionner le boot via BIOS (legacy) ou via UEFI :
|
|
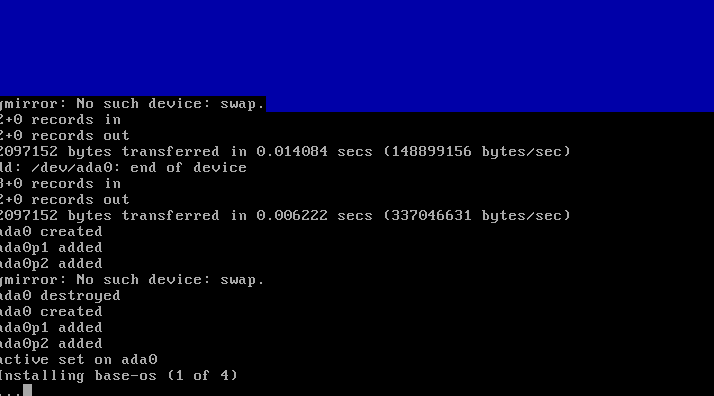
L'installation va ensuite se déclencher :
|
|
Il vous sera ensuite demandé de rebooter :
|
|
Au premier démarrage, vous aurez l'écran suivant :
|
|
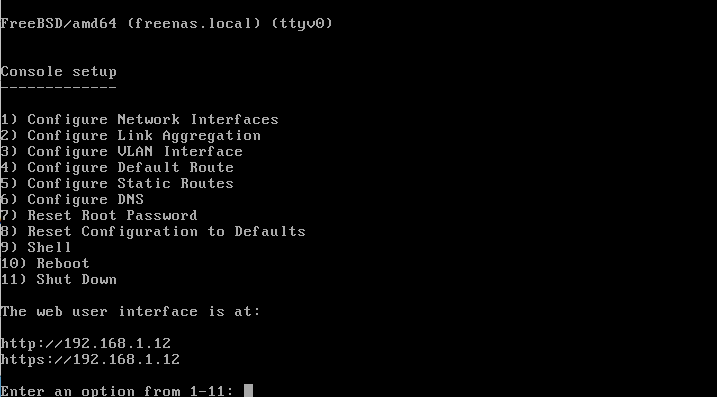
Vous pouvez changer les réglages réseau. Vous pourrez le faire a posteriori depuis l'interface web.
À ce stade, vous pourrez passer via l'interface web, il faudra vous connecter avec le mot de passe root précédemment communiqué :
|
|
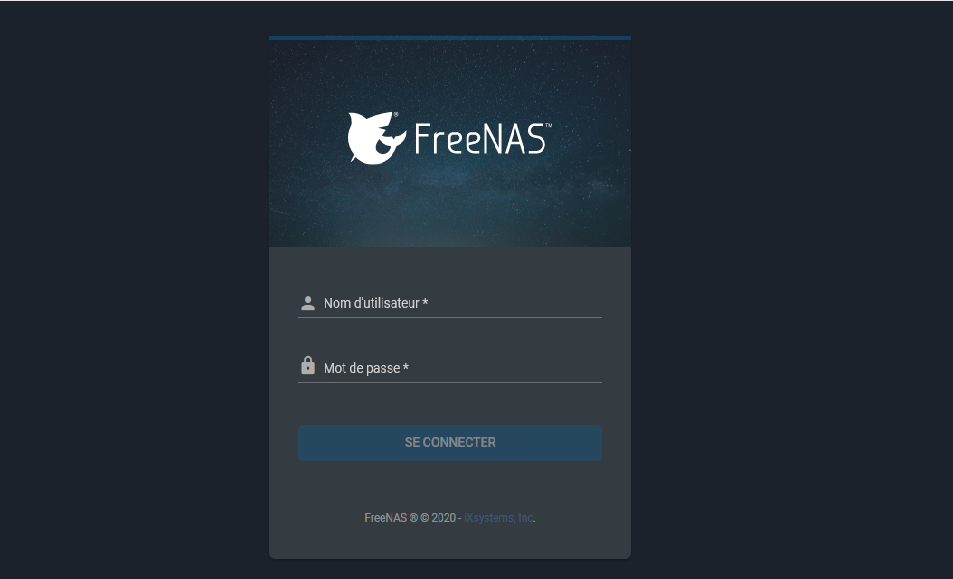
Écran de l'interface web :
|
|
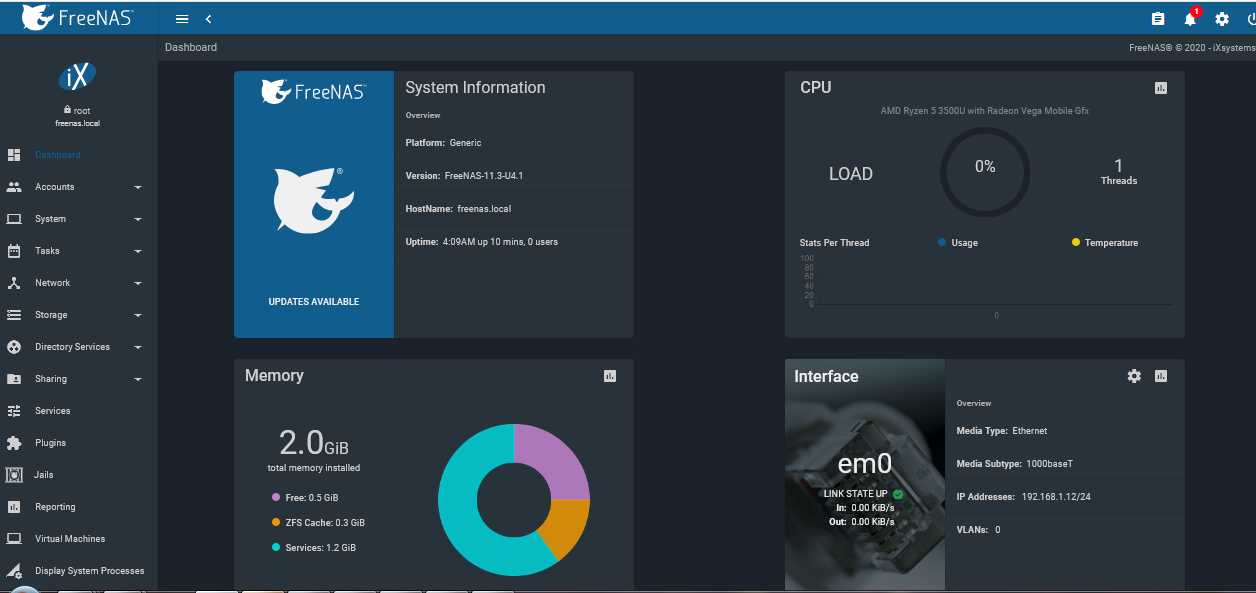
Nous commencerons par vérifier si des mises à jour sont disponibles en cliquant sur « check for updates » :
|
|
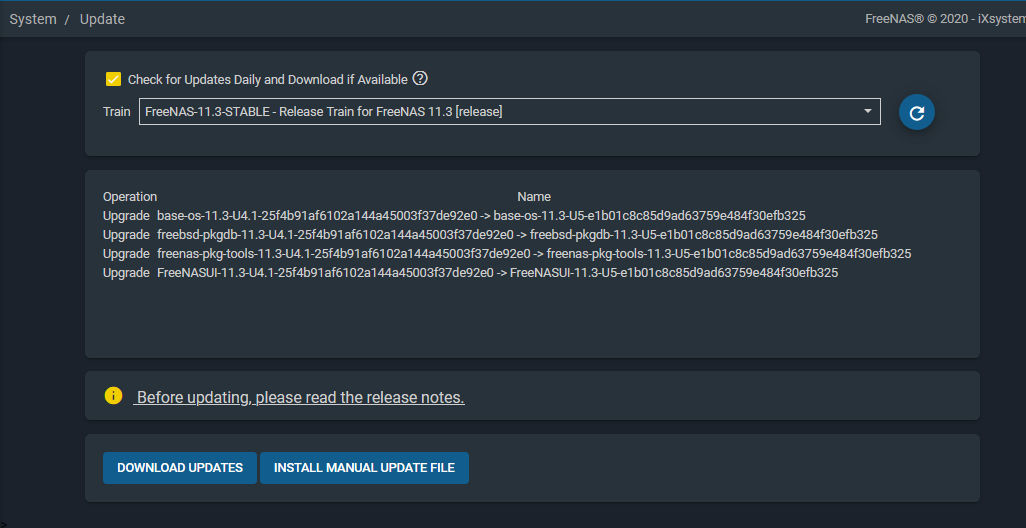
Nous continuons ensuite par passer le système en français, changer la langue du clavier, mettre à jour le fuseau horaire :
|
|
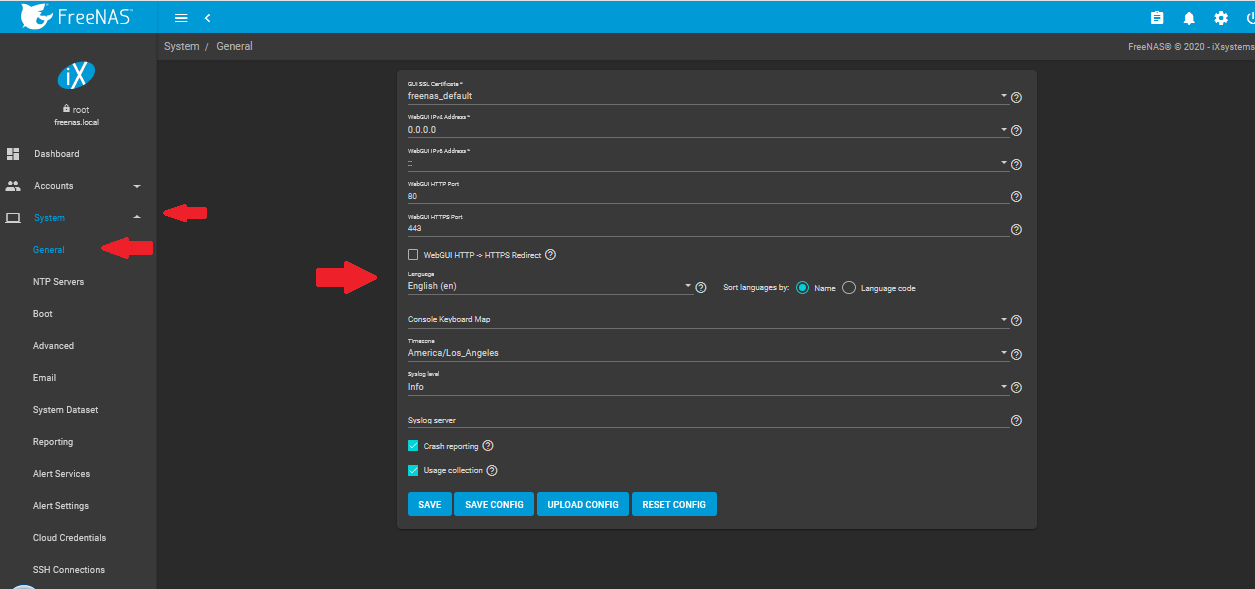
L'écran passe immédiatement en français.
Vous pourrez également changer les ports d'écoute de l'interface web (bonnes pratiques habituelles).
La prochaine étape sera l'activation du mot de passe pour accéder à la console. Pour cela, il va falloir décocher « Afficher la console sans mot de passe » dans le menu système->avancé :
|
|
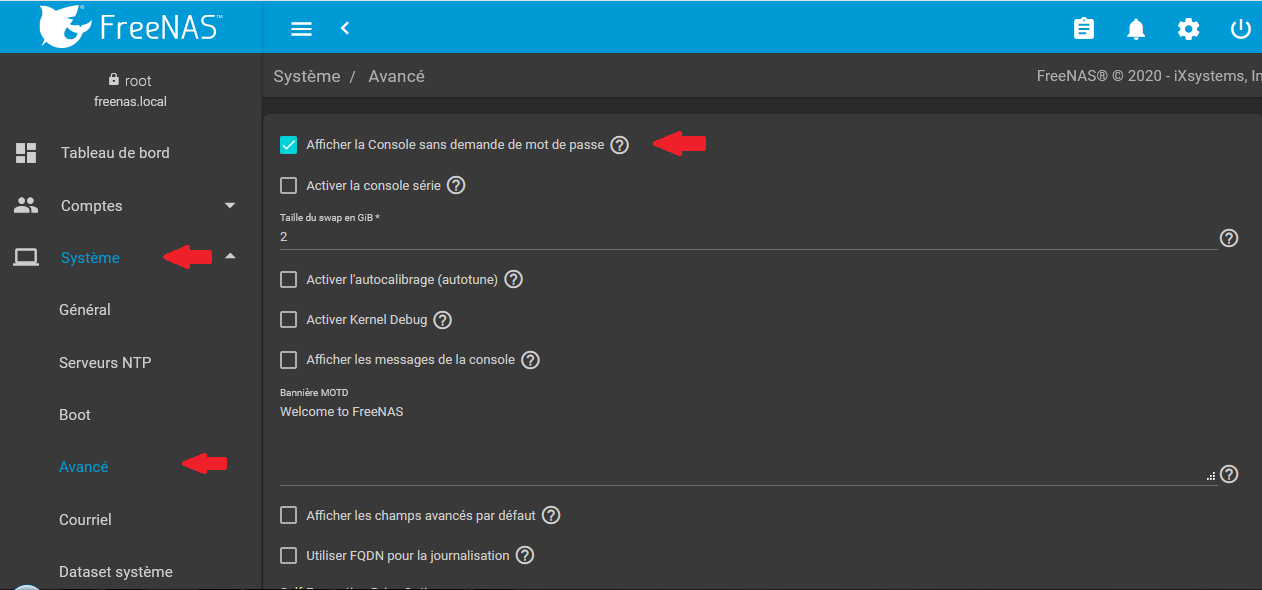
Dès le clic enregistré, la console va se verrouiller et nécessitera la saisie du mot de passe root.
À ce stade, freeNAS n'est pas encore utilisable, il va nous falloir créer un volume.
4-1-3-2. Création d'un volume▲
Pour créer un volume, il va nous falloir aller dans le menu stockage → volumes :
|
|
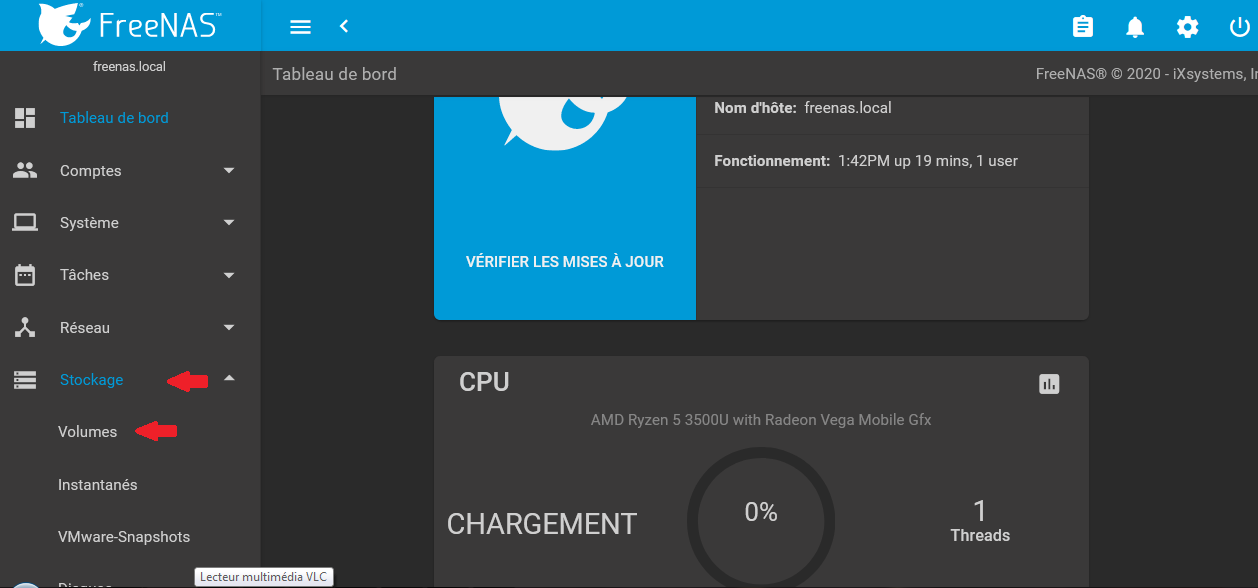
Cliquer sur « Ajouter » nous donnera accès à la création de volume :
|
|
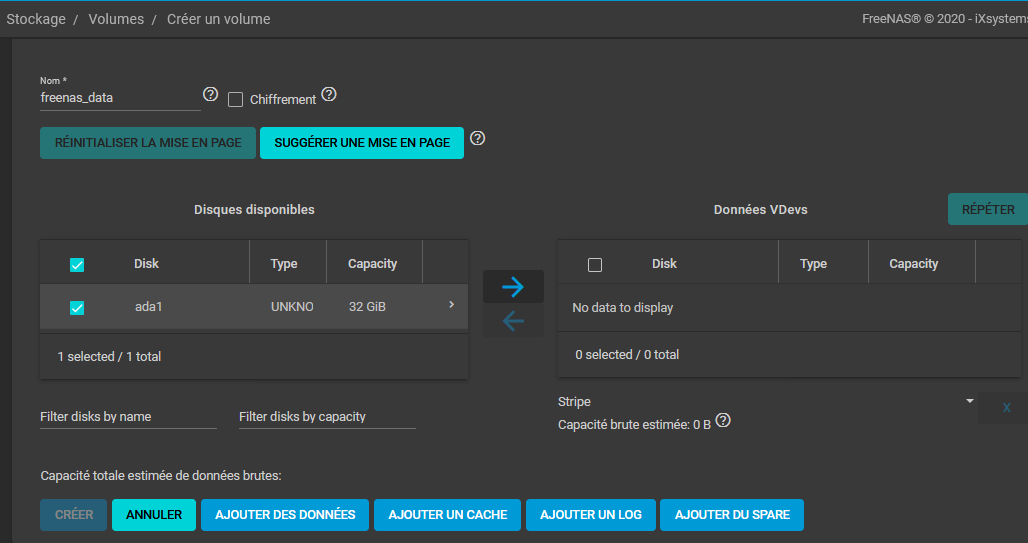
Vous seront alors affichés les volumes disponibles, il faudra cocher le volume souhaité et lui donner un nom :
|
|
À côté du nom, vous aurez une case à cocher permettant de chiffrer le volume.
Si vous chiffrez le disque, TrueNAS vous fera télécharger la clé sous forme de fichier. La perte de cette clé vous empêchera l’accès aux données du volume ZFS.
L'écran se présente en deux parties, à gauche la partie volume physique, à droite la partie volume logique. Il vous sera possible de créer un volume logique depuis plusieurs volumes physiques. Il faudra cliquer sur la flèche pour déplacer le ou les volumes dans la partie droite. Une fois ceci fait, vous pourrez créer le volume.
|
|
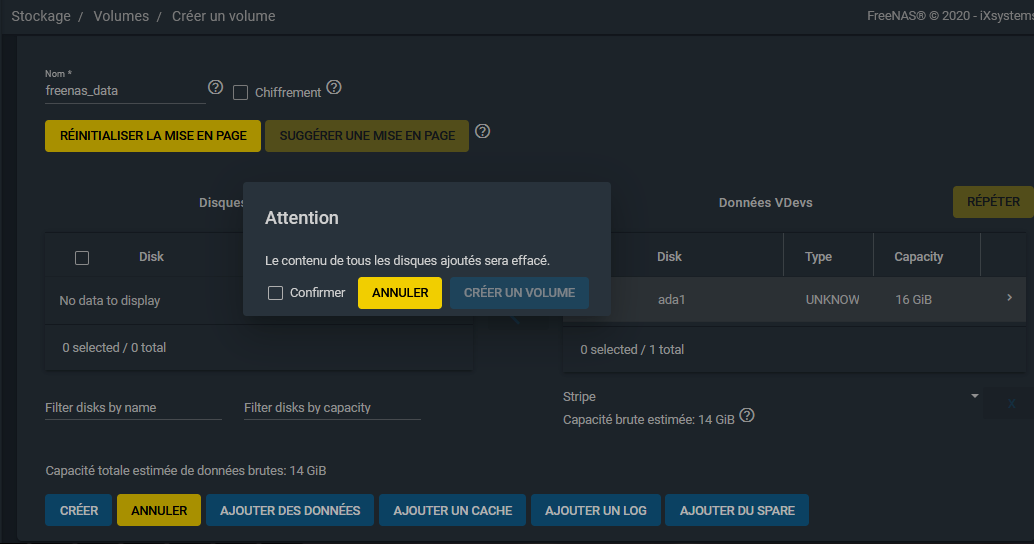
Vous aurez une demande de confirmation, il faudra cocher la case pour pouvoir confirmer :
|
|
FreeNAS revient sur le premier écran permettant de créer un volume, nous voyons la liste des volumes :
|
|
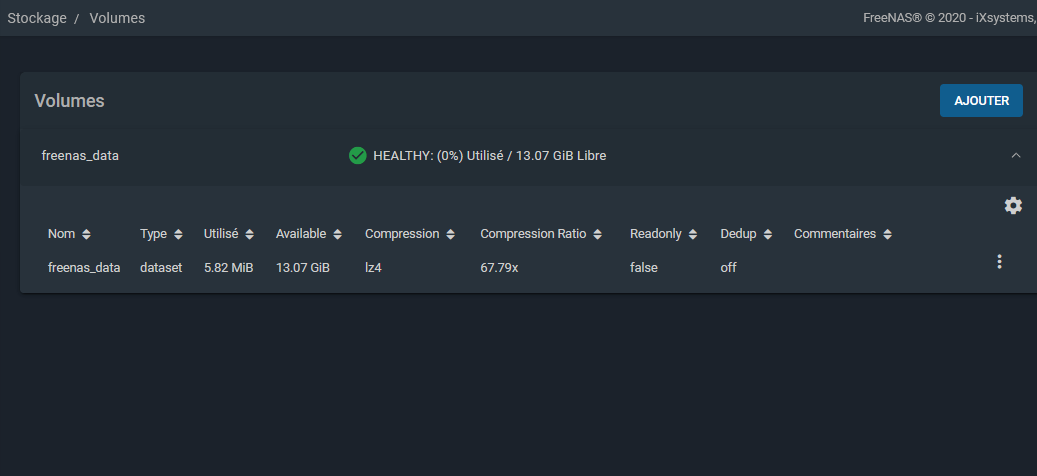
Depuis la console, nous trouverons le volume FreeNAS_data monté dans /mnt/freenas_data. Il s'agit d'un volume ZFS. ZFS est un système de fichiers ayant des capacités théoriques quasi infinies. Il a également l’avantage d'intégrer la possibilité de faire des clichés, de pouvoir faire des partages natifs en SMB et NFS. Tout partage créé depuis FreeNAS sera contenu à ce niveau.
4-1-3-3. Partage de fichiers▲
Pour pouvoir utiliser FreeNAS, l'étape suivante sera de créer un partage de fichiers.
Les partages disponibles sont :
- AFP : partage pour Macintosh ;
- iSCSI : partage au niveau bloc pouvant être assimilé à du SCSI Over IP ;
- NFS : partage natif Unix, classique sur ce type de solutions ;
- WebDAV : (Web-based Distributed Authoring and Versioning) extension du protocole HTTP dédié à la gestion de fichiers via le web. Windows et Mac OS permettent de monter un volume WebDAV comme un volume réseau standard. Sous Linux, DavFS permet de monter un volume WebDAV via FUSE. Pour un usage interne, je privilégierais SMB, mais pour un usage externe cela peut être utilisé pour faciliter le passage de firewalls, mais je privilégierais plutôt une connexion SSH ;
- SMB : partage utilisé par Windows et utilisable depuis quasiment tout système, ce sera le plus utilisé sur ce type de solutions.
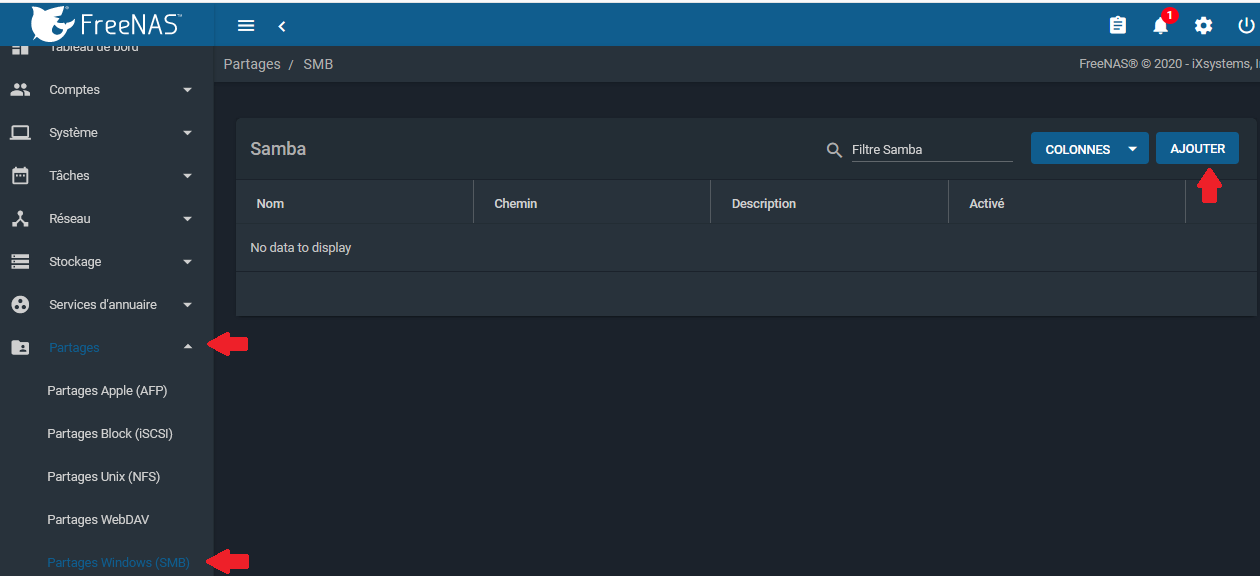
L'accès à la gestion des partages se fera depuis l'onglet « Partages » sur la gauche.
4-1-3-3-1. Partage Windows▲
Nous accédons au menu de gestion des partages Windows :
|
|
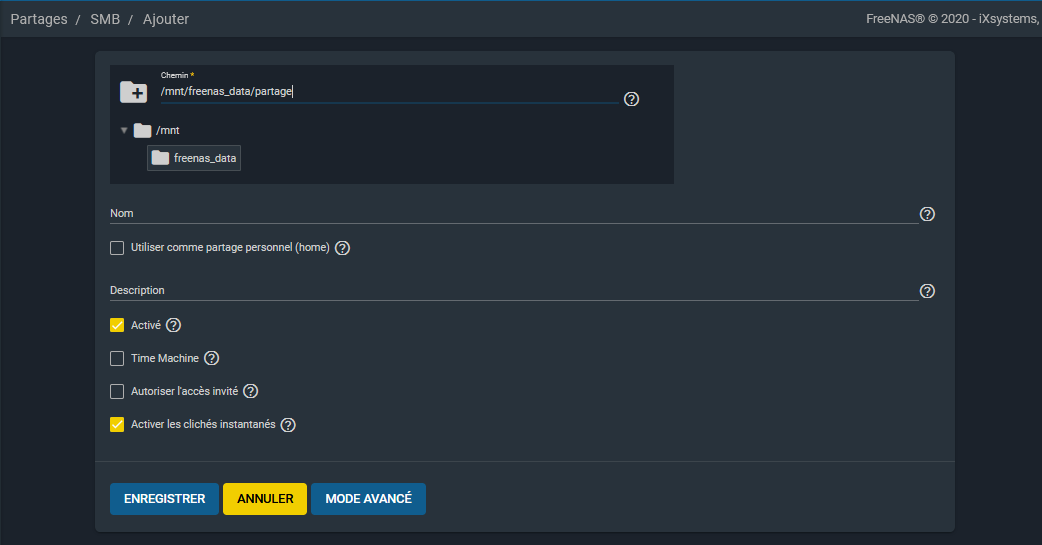
Une fois « Ajouter » cliqué, il va falloir entrer le chemin d'accès, le nom de partage. Une fois FreeNAS_data sélectionné à la souris, je rajoute le nom partage pour créer un dossier :
|
|
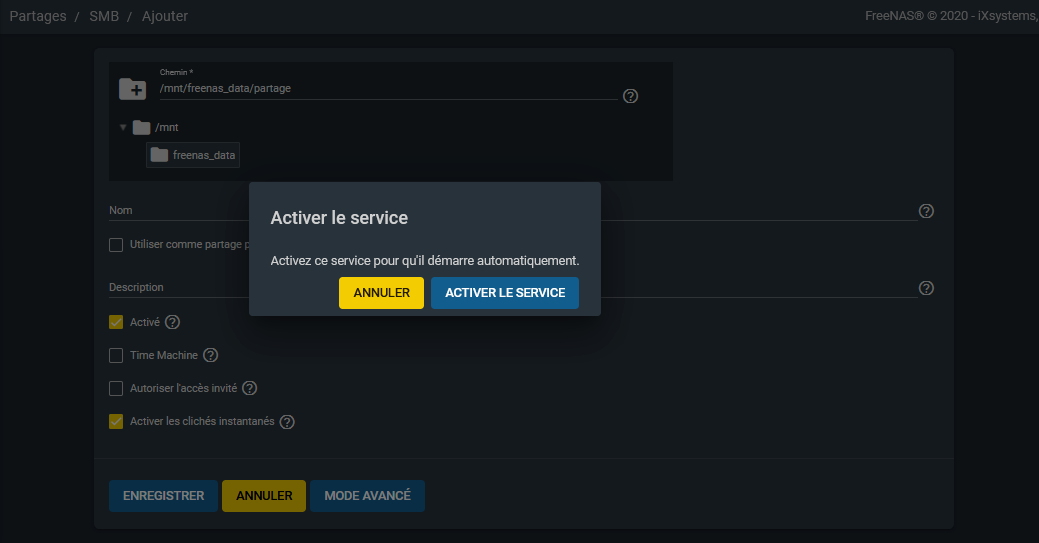
Après avoir cliqué sur « Enregistrer », il vous sera demandé d'activer le service (en fait le service SMB :
|
|
|
|
Il vous sera alors demandé d'activer les ACL :
|
|
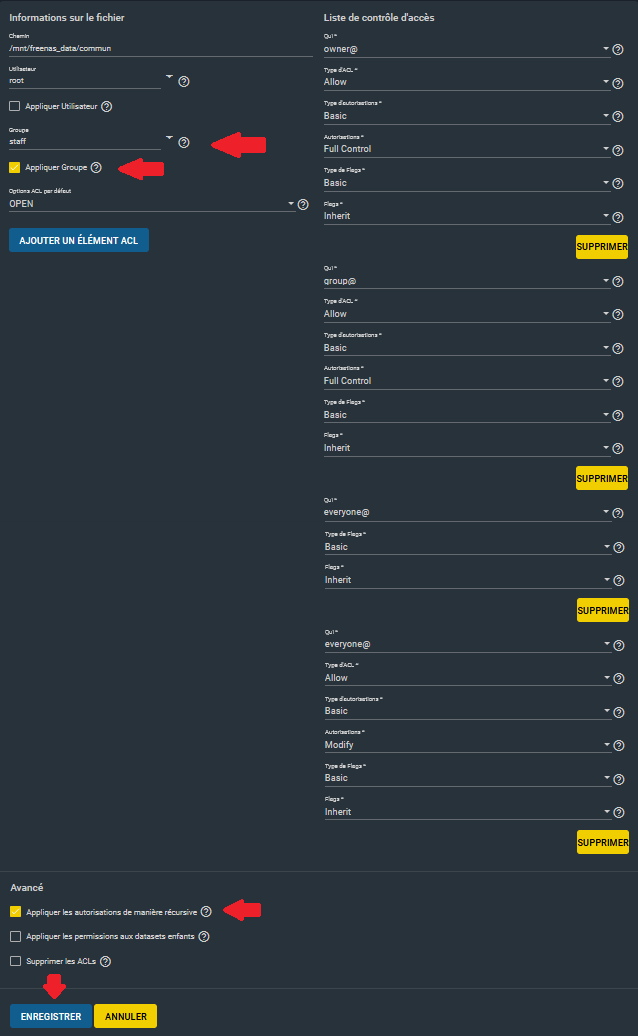
La gestion des ACL peut être complexe. Pour un dossier donné, voici un exemple autorisant l'accès d'un dossier aux membres du groupe Staff :
|
|
|
|
4-1-3-3-2. Partage NFS▲
Le principe du partage NFS est le même. Vous n'aurez pas de gestion d'ACL, le protocole ne le gérant pas.
Vous pouvez partager un dossier sur plusieurs protocoles, exemple SMB et NFS.
4-1-3-3-3. Partage Apple (AFP)▲
L’aspect pertinent du partage AFP fourni par FreeNAS est de pouvoir l'utiliser avec Time Machine. Il faudra cocher pour cela la case « Time Machine ».
4-1-3-3-4. Partage WebDAV▲
Comme il vous sera indiqué, activer un partage WebDAV sur un dossier existant va transférer la propriété de celui-ci à l'utilisateur WebDAV, ce qui pourra entraîner des problèmes de droits.
Le port d'écoute par défaut est 8080. Vous pourrez le changer depuis le menu services → WebDAV.
4-1-3-4. Plugins▲
Il est possible d'ajouter des fonctionnalités à FreeNAS par le biais de plugins. Voici quelques exemples de plugins disponibles :
dépôt de l'éditeur :
- ClamAV ;
- Nexcloud (que nous verrons au chapitre suivant) ;
- Syncthing (que nous verrons également).
dépôt de la communauté :
- Drupal 8 ;
- Duplicati ;
- Gitlab ;
- Grafana ;
- OpenVPN Server.
Pour installer ces plugins, il vous faudra cliquer sur plugin sur le menu de gauche. Vous sera alors demandé le volume où stocker les plugins, je sélectionne mon volume freenas_data :
|
|
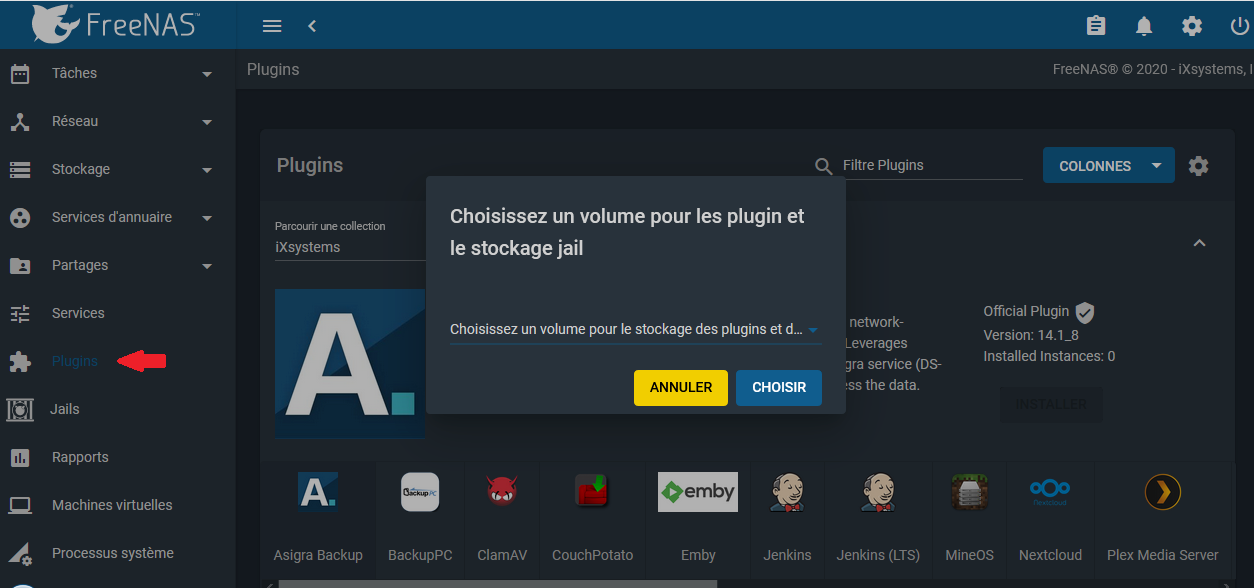
.
|
|
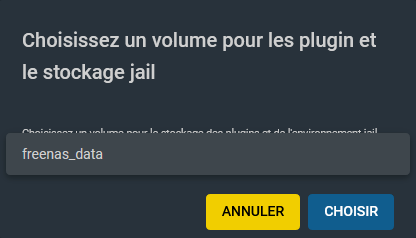
Ceci va créer un dossier iocages dans le volume freenas_data.
Je choisis pour l'exemple d'installer le plugin « Nextcloud » :
|
|
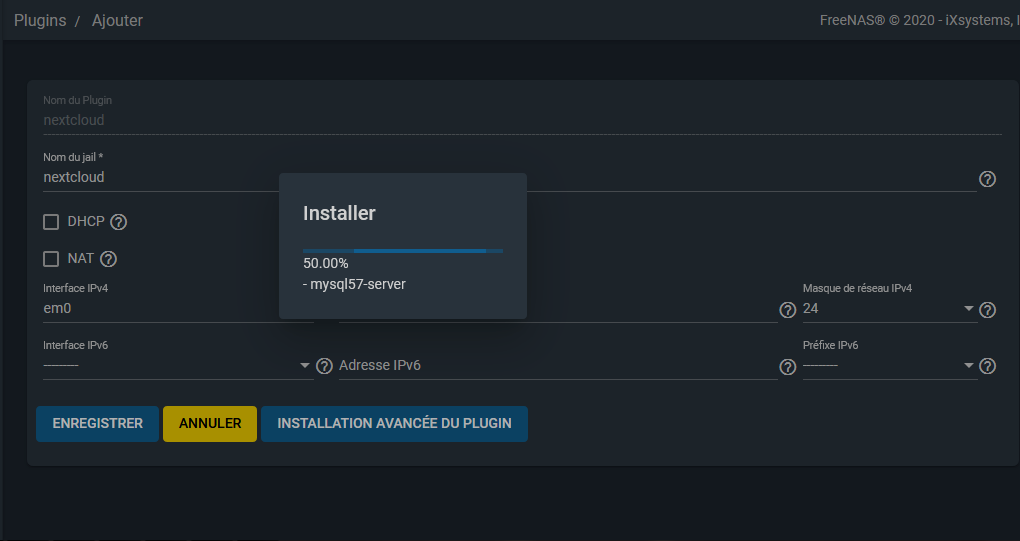
Une fois l'installation terminée, vous pourrez voir le plugin en dessous des icônes de plugins installables :
|
|
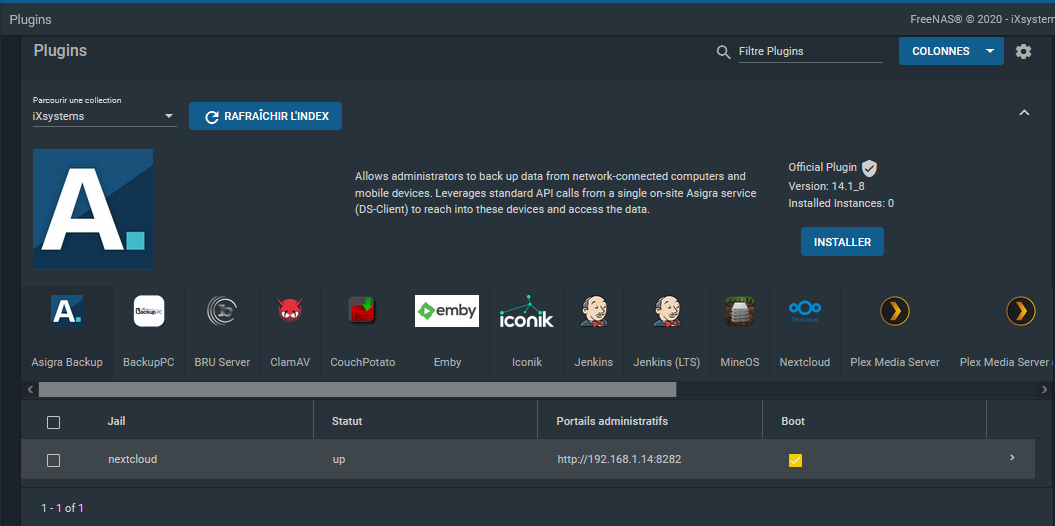
Nous pouvons voir l'interface d'accès à l'administration de Netxcloud (http://192.168.1.14:8282 dans l'exemple). Cette interface vous présentera la page de configuration de Nextcloud telle que nous la verrons dans le prochain chapitre. Les informations de connexion sont disponibles dans les notes de postinstallation :
|
|
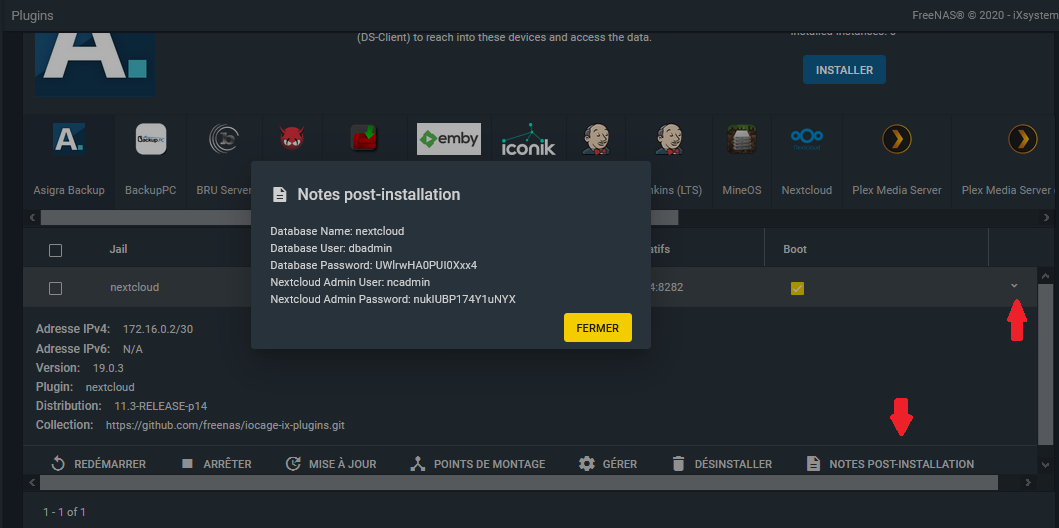
Les plugins sont installés dans des BSD Jails, système de conteneurs spécifique à BSD et précurseur de systèmes de type Docker.
Il est possible d'entrer dans la console du BSD Jail depuis le menu à gauche, Jails :
|
|
|
|
4-1-3-5. Machines virtuelles dans FreeNAS▲
Si la machine où vous avez installé FreeNAS supporte la virtualisation, vous pourrez créer des machines virtuelles Windows, Linux, ou freeBSD.
Une fois le bouton « Ajouter » depuis le menu Machines virtuelles, il faudra renseigner le type d'OS (Windows, Linux, FreeBSD), le nom de celle-ci, la méthode de démarrage (UEFI, UEFI-CSM, Grub) :
|
|
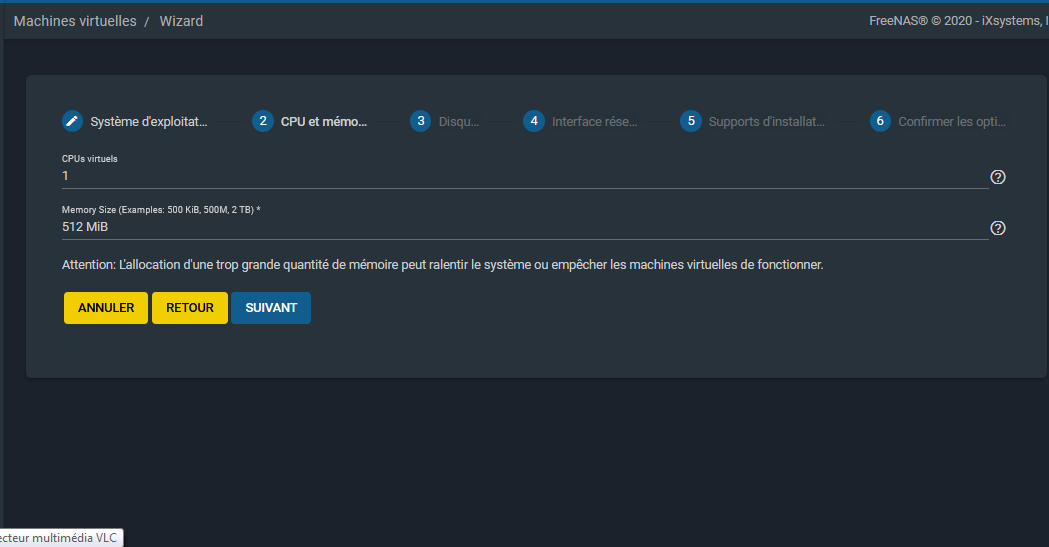
Vous sera ensuite demandé le nombre de CPU et de RAM à attribuer à la VM :
|
|
Ensuite, il vous faudra créer un disque virtuel ou en sélectionner un existant :
|
|

Il vous faudra sélectionner le chemin où stocker celui-ci, vous pourrez ensuite sélectionner la taille du disque.
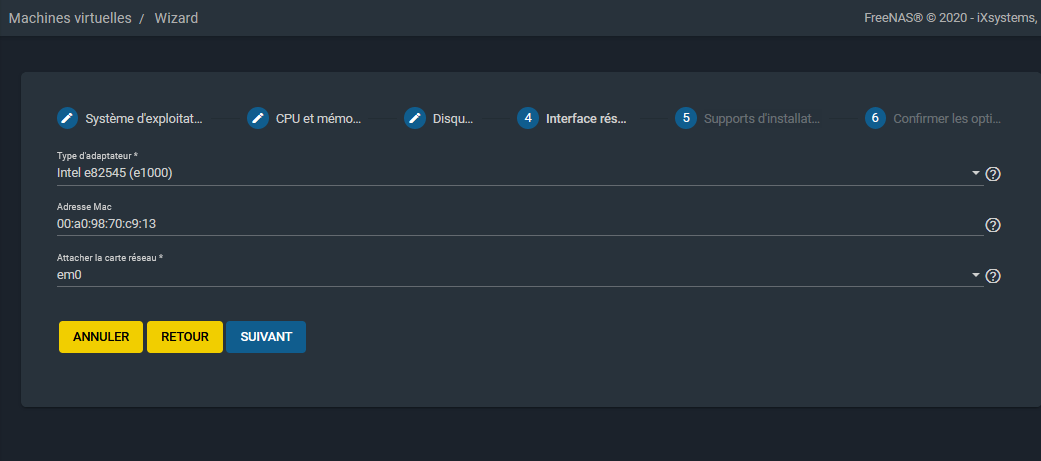
Vous sera ensuite proposé l'écran de la carte réseau, vous pourrez changer l'adresse MAC et sélectionner la carte réelle, si vous en avez plusieurs, sur laquelle affecter l'interface virtuelle :
|
|
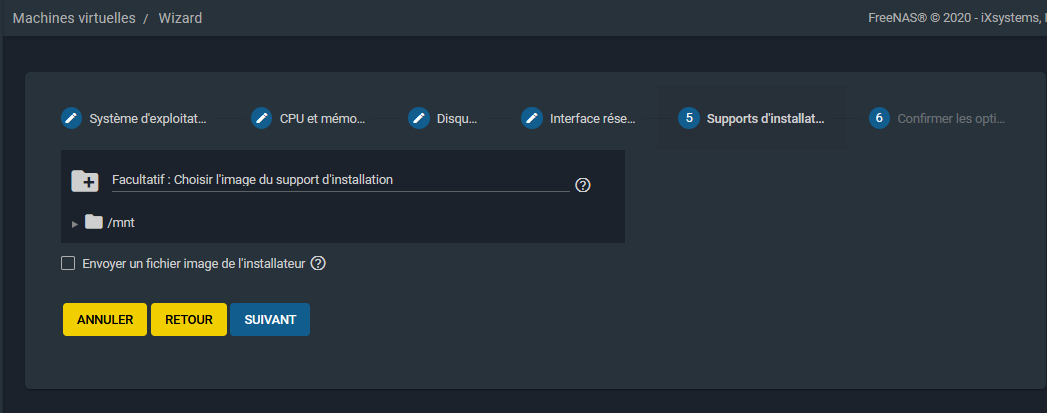
Vous pourrez ensuite choisir le support d'installation :
|
|
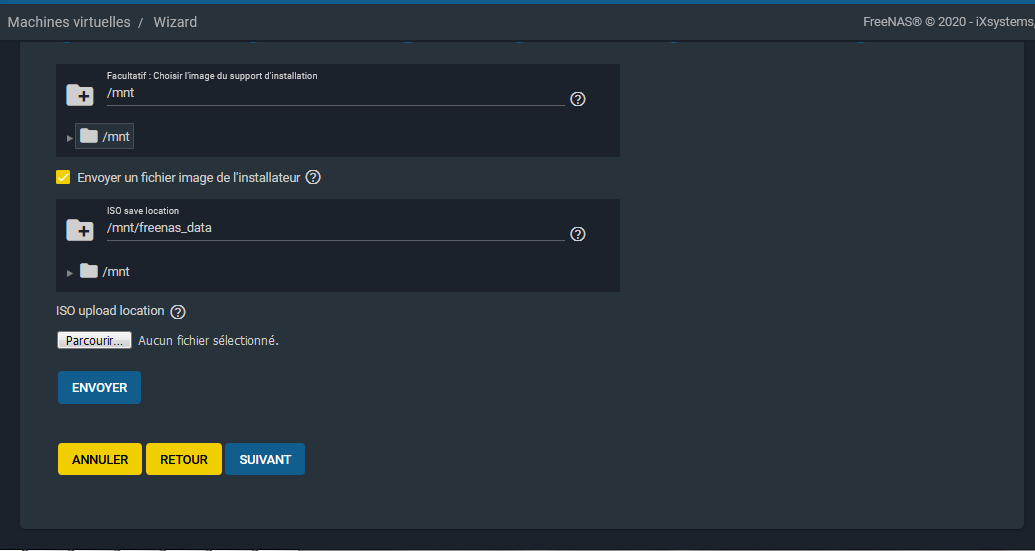
Pour en uploader un, il faudra cocher « Envoyer un fichier image de l'installation », puis cliquer « Parcourir », et enfin « Envoyer » une fois le fichier sélectionné :
|
|
Vous aurez ensuite un écran de confirmation :
|
|
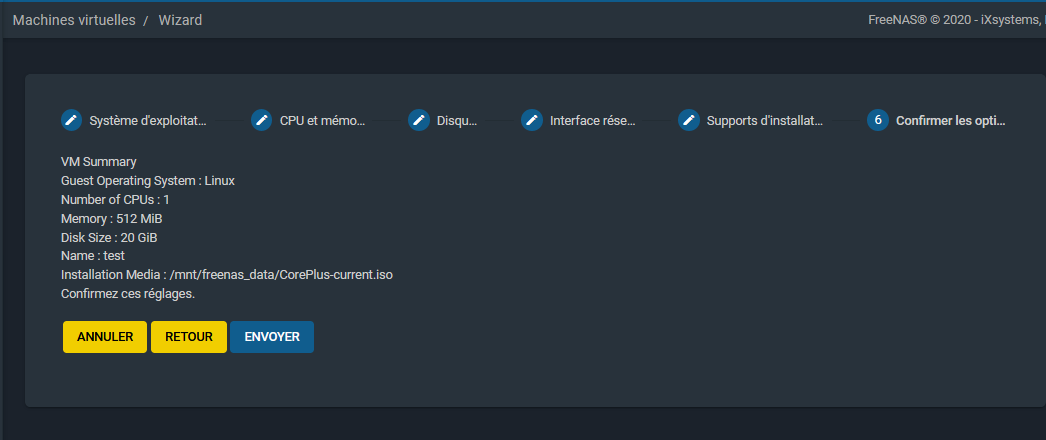
La machine virtuelle sera alors créée et visible dans la liste :
|
|
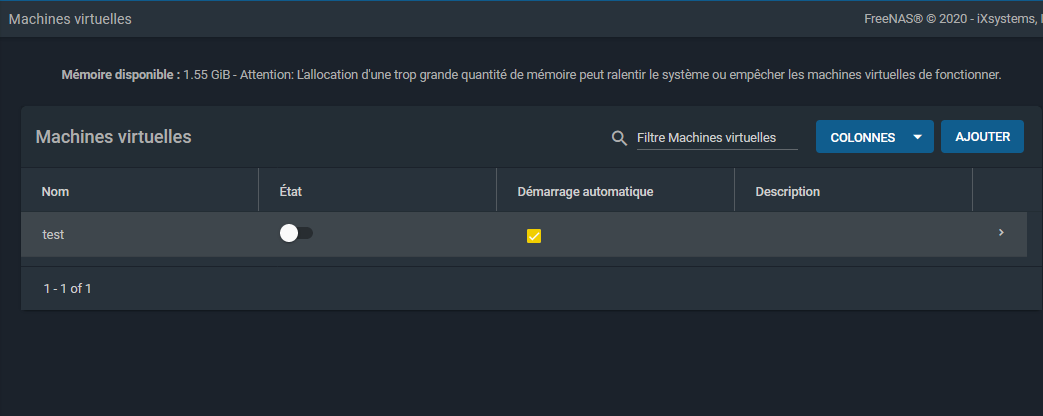
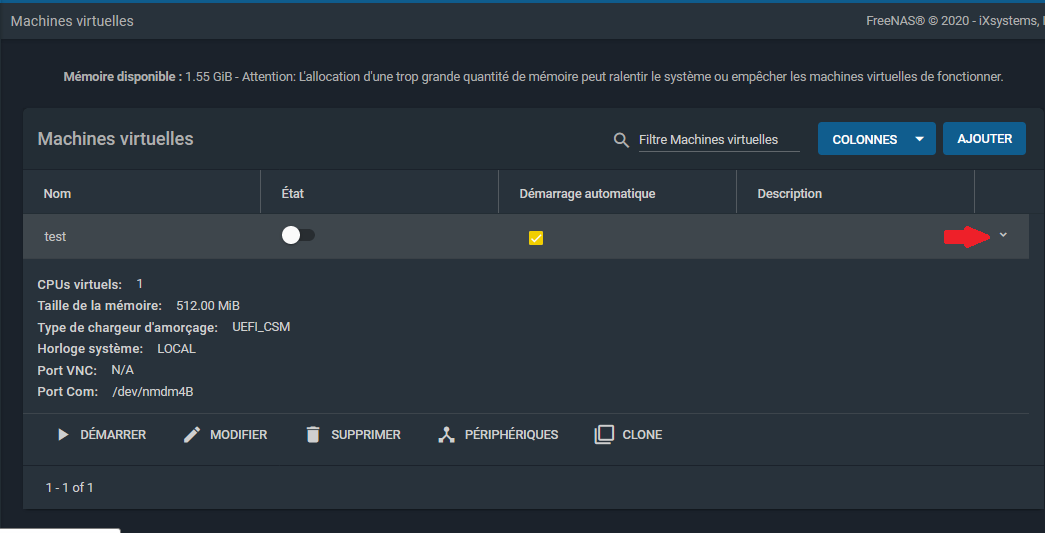
Cliquer sur le bouton de la colonne « état » démarrera la machine virtuelle. Cliquer sur la petite flèche à droite vous permettra d'accéder à la configuration de celle-ci :
|
|
Si vous allez dans le menu stockage → volumes, vous pourrez voir un zvol (sorte de volume dans un volume dans ZFS) correspondant à l'image disque de la machine virtuelle. Ce zvol portera le nom de la machine virtuelle suivi de plusieurs lettres aléatoires :
|
|
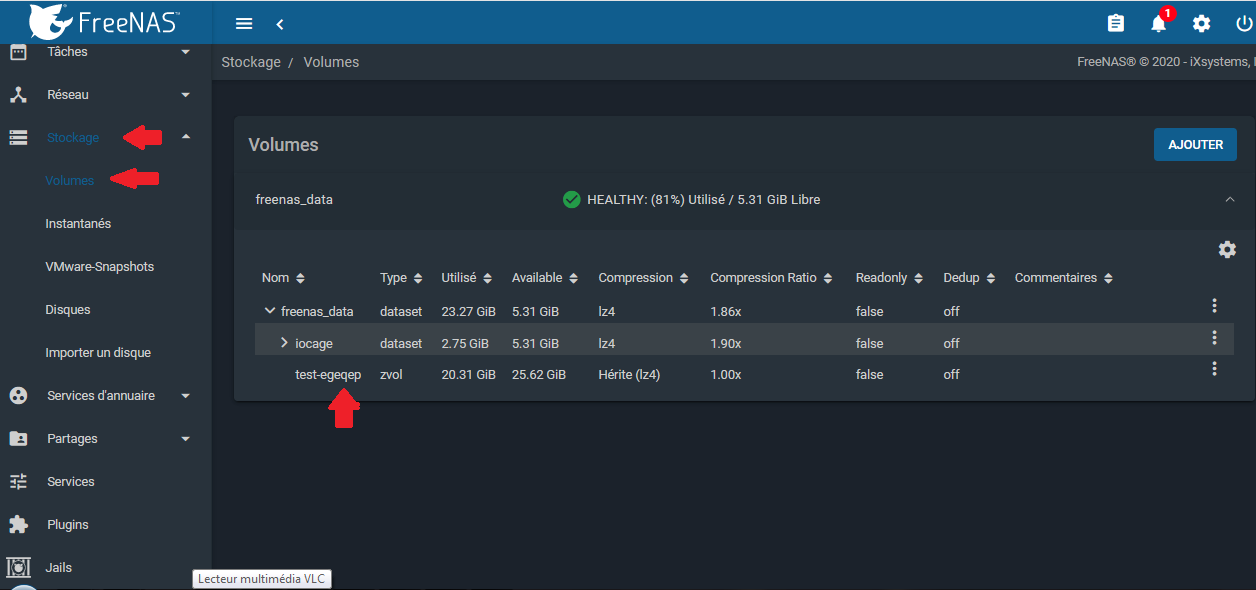
accessible dans /dev/zvol/freenas_data. freenas_data étant le pool créé au chapitre création d'un volume.Installation sur système existant
4-1-3-6. Options avancées▲
Sont présentées ici les fonctionnalités les plus importantes, de façon non exhaustive.
4-1-3-6-1. Tache rsync▲
Cette option est accessible depuis le menu tâches → rsync. Ceci vous permettra de lancer une tâche rsync vers un autre hôte.
Vous seront demandés :
- l'utilisateur à utiliser ;
- le nom d'hôte distant ;
- la direction (PUSH/PULL PUSH : envoi vers l'hôte distant, PULL reçoit de l'hôte distant) ;
- les options principales de rsync présentes sous forme de cases à cocher.
|
|
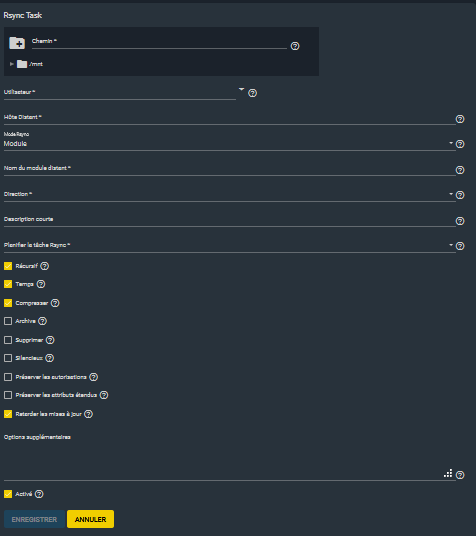
4-1-3-6-2. Réplication▲
Il est possible de répliquer vos dossiers vers une destination locale ou distante (copie via SSH, il est aussi possible d'utiliser une source distante). Ceci se fera depuis le menu tâches → réplication :
|
|
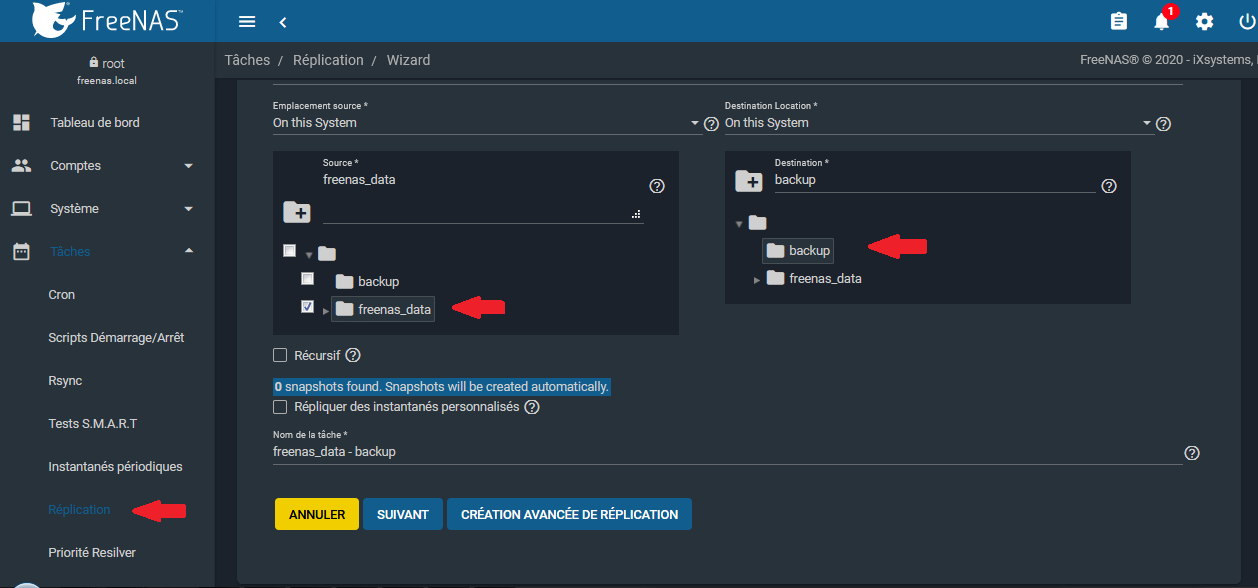
En cas de volume de destination local, celui-ci devra être créé avant.
Le prochain écran concernera la planification.
|
|
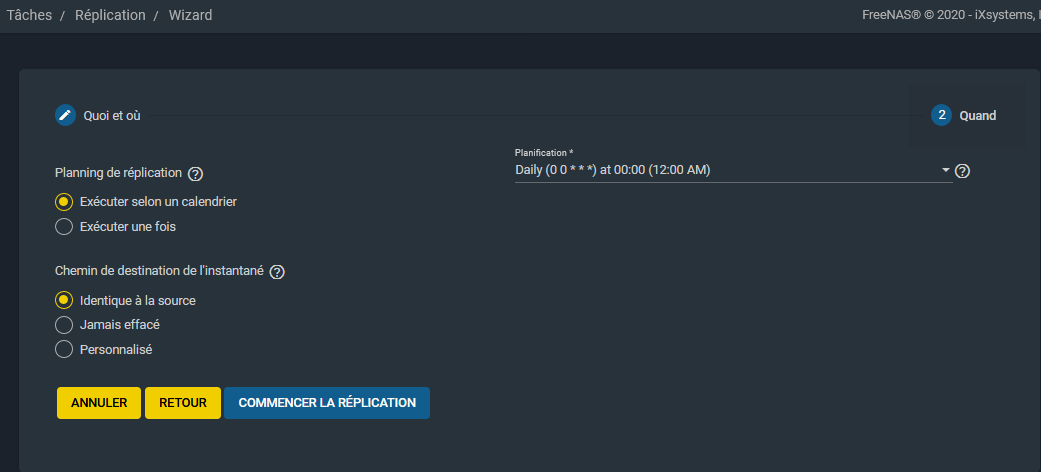
Une fois la réplication effectuée, la destination backup de notre exemple sera identique à la source freenas_data.
4-1-3-6-3. Synchronisation cloud▲
Ceci vous permettra de synchroniser vos données vers le cloud. Les connecteurs cloud disponibles sont :
- Amazon S3 ;
- Blockbase B2 ;
- Box ;
- DropBox ;
- Google Cloud Storage/Google Drive ;
- Microsoft OneDrive/Microsoft Azure blob storage ;
À cela s'ajoutent les connecteurs standards suivants :
- FTP ;
- SFTP ;
- WebDAV ;
La première étape va consister à créer le connecteur dans le menu système → identifiants cloud. Il faudra y renseigner les éléments afférents à celui-ci :
- nom d'hôte ;
- jeton d'accès ;
- identifiants.
Vous pourrez ensuite créer la tâche de synchronisation :
|
|
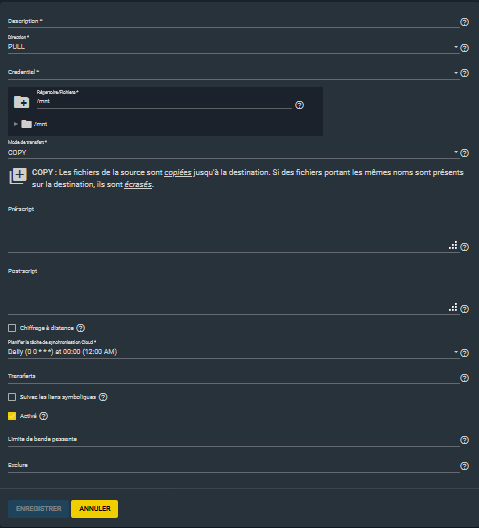
4-1-3-6-4. Gestion avancée de l'alimentation des disques▲
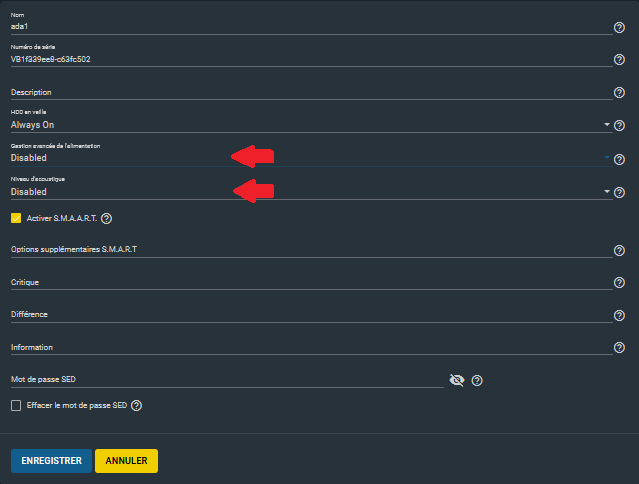
Il est possible de gérer l'alimentation des disques en allant dans le menu Stockage → disques :
|
|
|
|

4-1-3-6-5. Services d'annuaire▲
FreeNAS permet de se connecter sur Active Directory ou sur un serveur LDAP (qu'il vous faudra installer) ainsi que sur un serveur NIS, et Kerberos.
Pour cela, il faudra entrer les informations de connexion dans le menu Service d'annuaire, sous-menu concernant l'annuaire.
4-2. OwnCloud – Application de cloud privé▲
|
|
OwnCloud est écrit en PHP et donc installable sur n’importe quel serveur supportant PHP. Les tests ont été effectués depuis une machine Linux.
Owncloud fournit :
- un service de stockage de fichiers accessible depuis un navigateur ;
- une application de synchronisation de données pour Windows, Mac OS, Linux, et pour les smartphones iOS et Android ;
- un partage de documents par envoi de lien (avec ou sans mot de passe) ;
- une gestion de calendrier depuis l'interface web et compatible avec le protocole CalDAV pour le partage avec les logiciels de messagerie ou de gestion de calendriers ;
- une gestion de contacts compatible CardDAV.
Owncloud.online est une solution vous permettant d'être directement hébergé par leurs services avec un abonnement mensuel ou annuel incluant un stockage de 500 Go. La solution « for teams » vous fournira 1 To par utilisateur avec un minimum de cinq utilisateurs. Le tarif à l'utilisateur est quasi identique entre l'offre personnelle et l'offre d'équipe.
Deux versions d'Owncloud existent, la version entreprise, et la version Community. Les différences sont détaillées ici. Notamment, plus de modules sont disponibles dans la version entreprise.
Pour migrer de la version Community à la version Entreprise, il vous faudra créer un compte sur le Marketplace. Vous aurez alors accès à une clé d'API qu'il faudra entrer dans le Market d'Owncloud, ceci après avoir cliqué « Commencer l'évaluation d'entreprise ». Vous aurez alors 30 jours d'essai gratuits avant de devoir acheter le service.
4-2-1. NextCloud – le fork de OwnCloud▲
|
|
Nextcloud est un fork de Owncloud. Il est relativement facile de migrer d'Owncloud vers Nextcloud, mais ceci n'a pas été testé dans ce tutoriel. Le processus d'installation est le même. Nextcloud a également un client pour les postes informatiques et smartphones. L'installation se fait de la même façon.
La version disponible de Nextcloud et testée au moment de l'écriture de ce tutoriel est la version 19.
Nextcloud requiert la version 7.2 de PHP au minimum.
4-2-2. Les différences constatées entre Owncloud et Nextcloud▲
Les applets fournies sont différentes, mais les applets principales telles que la gestion de calendriers et contacts sont présentes dans les deux produits.
La première différence est l’installation par défaut des applets les plus utilisées (photos, contacts, agendas) dans Nextcloud, sauf si vous décochez la case « installer les applications recommandées » sur l'écran de configuration.
Ci-dessous écran d'installation suivant celui des paramétrages de base (compte administrateur, informations sur la base de données) :
|
|
Les options de configuration diffèrent sur la forme, mais pas sur le fond. Une fois installées, l'accès aux applications agenda et carnet d'adresses se fait directement depuis des icônes dans la barre du haut.
|
|
Les paragraphes concernant la synchronisation de l'agenda et des contacts restent valables pour les deux produits.
L'accès aux applications se fera depuis le menu à droite. Sur Owncloud, l'option se trouve à gauche depuis la partie administration.
Vous pourrez voir les différentes applications sur https://apps.nextcloud.com.
4-2-3. Personnalisation de l'apparence▲
Netxcloud permet la personnalisation de l'interface ainsi que la page de connexion, réglage accessible depuis paramètres (en haut à droite) → « Administration » → « personnaliser l'apparence ».
Exemple simple avec le logo et la couleur de fond DVP :
|
|
Owncloud possède une extension « Owncloud X Enterprise Theme », mais payante. Celle-ci n'a pas été testée :
|
|
4-2-4. Authentification via les comptes locaux▲
Nextcloud comporte un plugin nommé « Unix User Backend » permettant l'authentification avec des comptes locaux. Vous le trouverez dans la section « Intégration ». Il faudra cliquer sur « activer les applications non testées » en dessous de son image, avant de pouvoir cliquer sur « Télécharger et Activer ».
Une fois le plugin activé, si vous ajoutez un utilisateur via la commande adduser, celui-ci apparaîtra dans les utilisateurs Nextcloud. Par contre, l'ajout d'un utilisateur dans l'interface Nextcloud n'est pas répercuté dans les comptes utilisateurs du système. L'interface Nextcloud présente les comptes contenus dans sa base de données, et dans les autres sources d'authentification gérées.
La connexion depuis un compte utilisateur Unix via le plugin « Unix user Backend » nécessite la présence du paquet pwauth. Si pwauth n'est pas installé, le système réagira comme si le nom d'utilisateur/mot de passe est invalide.
Vous ne pourrez pas changer le mot de passe du compte Unix depuis l'interface Nextcloud. La tentative de suppression du compte générera une erreur. La suppression du compte depuis la console Unix (via deluser par exemple) sera prise en compte dès le rafraîchissement de la page Nextcloud. Les données Nextcloud de l'utilisateur ne seront pas effacées.
Il existe également un plugin permettant l'authentification via SMB : « External User Authentication », mais celui-ci n'a pas été testé.
4-2-5. Installation de ownCloud▲
La version testée et disponible au moment de l'écriture de ce tutoriel est la version 10.
ownCloud 10 requiert minimum PHP 7.1.0 (Debian 9 étant fourni avec PHP 7.0, il faudra faire la mise à jour). Pour la base de données, vous aurez le choix entre sqlite, MySQL/MariaDB, et PostgreSQL.
Sous Linux, il suffit de décompresser l'archive zip et de placer les fichiers dans /var/www (ou /var/www/html selon votre version, ou de configurer un fichier Virtualhost comme vous le souhaitez).
Il vous faudra un MySQL ou un PostGreSQL fonctionnel si vous souhaitez l'utiliser.
Les fichiers devront avoir les droits www-data.
Attention au fichier .htaccess non visible, qu'il faudra copier.
Au premier démarrage vous aurez l'écran suivant :
|
|
ownCloud requiert les paquets php-zip, php-dom, php-xml,php-gd,php-mb php-curl et php-intl :
apt-get install php7.1-zip php7.1-dom php7.1-xml php7.1-gd php7.1-mb php7.1-curl php7.1-intlNous redémarrons le service :
service apache2 restartVous aurez ensuite l'écran suivant :
|
|
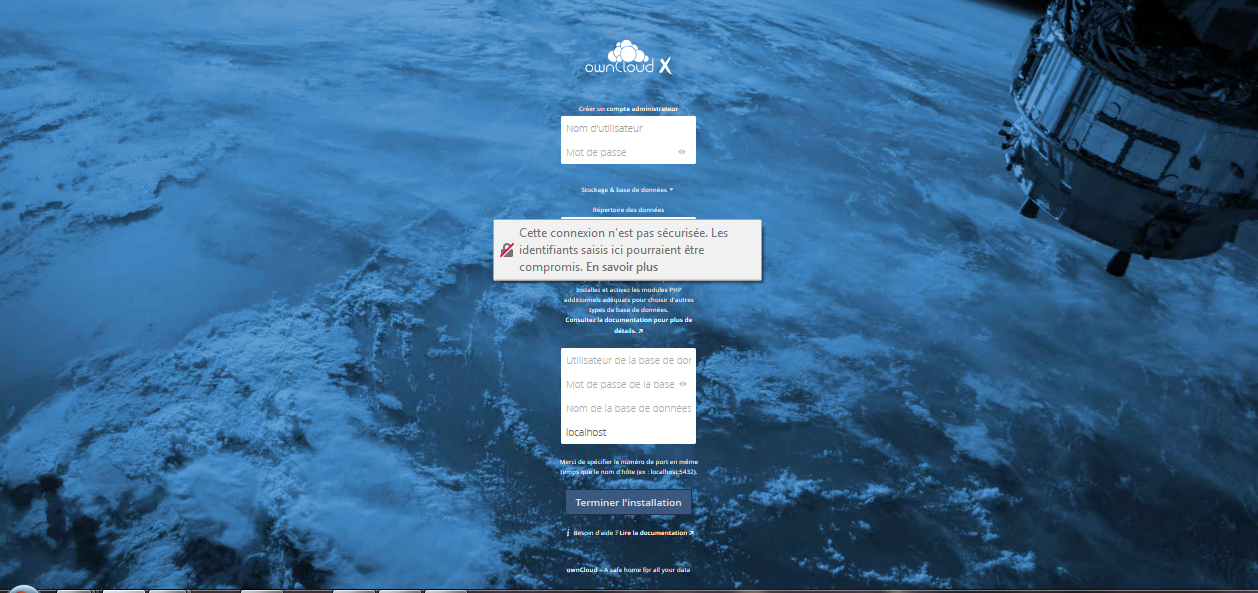
ownCloud vous demandera :
- un nom d'utilisateur administrateur ;
- un mot de passe ;
- le chemin de stockage des données (par sécurité, ne pas laisser dans un sous-dossier du site, si vous le faites ownCloud vous préviendra). Dans notre cas le stockage se fera dans /data. (/data étant le dossier ou point de montage devant contenir les données). Le dossier /data devra appartenir à www-data.
-
les informations de connexion à la base de données :
- nom d'utilisateur ;
- mot de passe ;
- nom de la base ;
- nom d'hôte /adresse IP.
La base devra être créée avant.
Il m'a été nécessaire de créer le dossier apps-external.
Une fois la préparation terminée, vous aurez l'écran de connexion ou vous devrez entrer l’identifiant préalablement choisi.
4-2-6. Première connexion à ownCloud▲
|
|
Vous aurez ensuite le premier écran de connexion (il faudra fermer la fenêtre d'accueil) :
|
|
Vous serez ensuite dans l'interface principale :
|
|
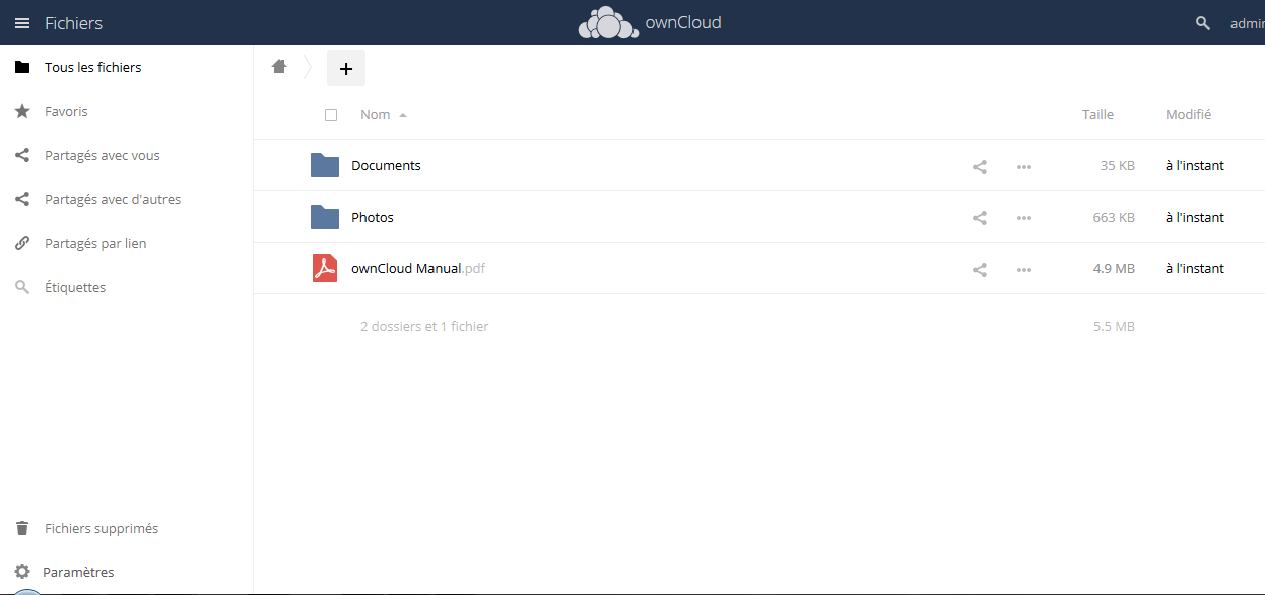
Les fichiers des utilisateurs sont stockés dans /data/[nom d'utilisateur]/files et /data/[nom d'utilisateur]/files_versions pour les anciennes versions.
La configuration se trouve dans le fichier config/config.php. Vous pourrez, en cas de changement de serveur par exemple, y changer les réglages tels que l'adresse du serveur, le dossier de stockage des données, le nom et les éléments de connexion de la base de données.
4-2-7. Utilisation de l'interface web d'ownCloud▲
Voici l'écran de l'interface :
|
|
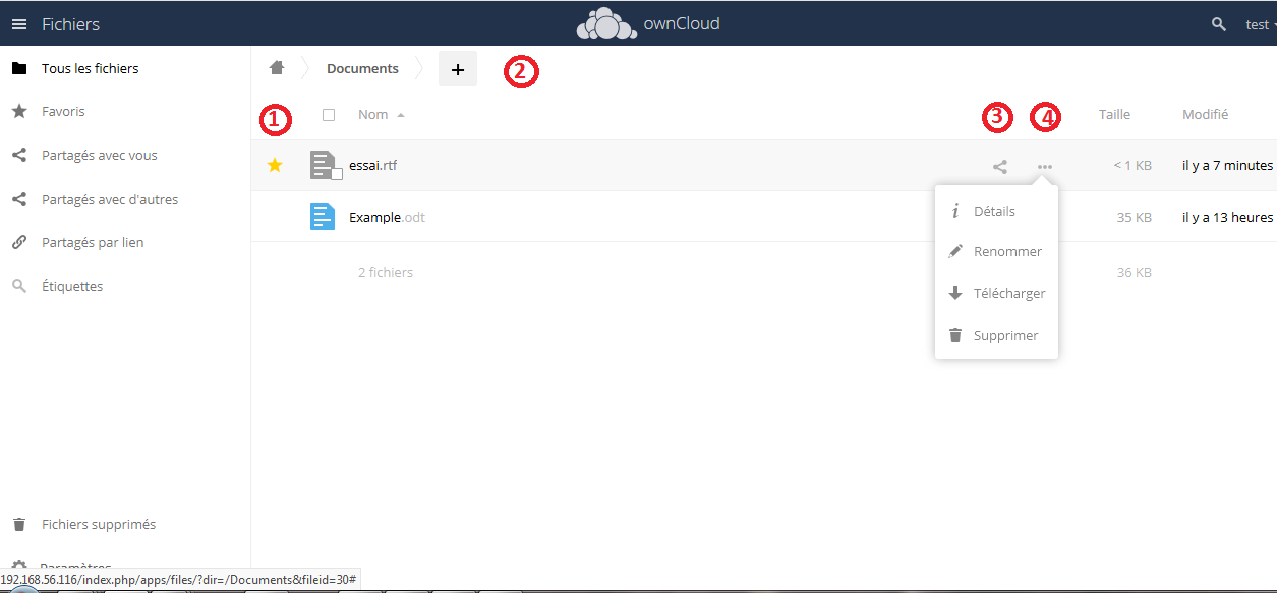
Vous pouvez uploader un fichier (le terme affiché est « Téléverser ») ou créer un dossier en appuyant sur le plus.
Sur la partie gauche, vous avez accès aux raccourcis :
- favoris ;
- documents récents ;
- documents partagés avec vous ;
- documents partagés avec d'autres.
Pour mettre un document ou un dossier en favori, il faut sélectionner celui-ci, et cocher l'étoile (en 1).
Cliquer sur un dossier va vous permettre de rentrer dedans, cliquer sur un fichier va le télécharger.
Vous voyez votre chemin d'accès en 2, un clic sur le pictogramme ![]() vous ramènera à la racine.
vous ramènera à la racine.
L’icône en 3 va ouvrir un écran de détail, vous permettant d'ajouter un commentaire ou de partager le fichier avec d'autres utilisateurs :
|
|
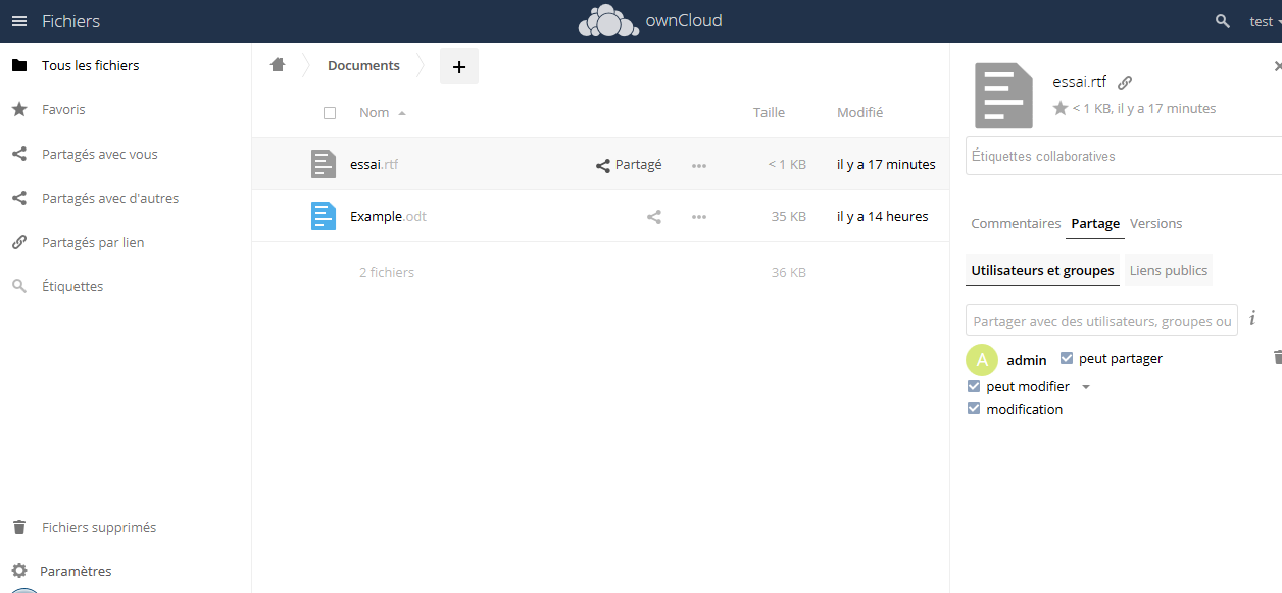
Vous verrez alors la notation partagée. Vous pouvez autoriser l'utilisateur à modifier le document, le repartager ou non, ou supprimer le partage. Vous pourrez également voir et gérer les partages depuis le client logiciel, comme nous le verrons ultérieurement.
Vous aurez également accès aux différentes versions d'un document. Vous pourrez soit les télécharger, soit les restaurer.
À chaque mise à jour, les versions sont ajustées comme ceci :
- les 10 premières secondes, conservation d'une version toutes les 2 secondes ;
- la 1re minute, conservation d'une version toutes les 10 secondes ;
- La 1re heure, conservation d'une version toutes les minutes ;
- Les 24 premières heures, conservation d'une version toutes les heures ;
- Les 30 premiers jours, conservation d'une version par jour ;
- Au-delà de 30 jours, conservation d'une version par semaine.
Si l'espace occupé dépasse les 50 %, le nombre de versions est diminué jusqu'à descendre en dessous de cette occupation.
Un fichier supprimé restera accessible depuis la corbeille accessible en bas à gauche.
L'ajout d'un fichier ou dossier se fera depuis l’icône ![]() qui affichera un menu :
qui affichera un menu :
|
|

Vous pourrez cliquer sur « Chargement » pour obtenir la boite de dialogue de sélection de fichiers, ou « dossier » pour créer un nouveau dossier.
Le Glisser-déplacer fonctionne également.
En cas d'upload d'un fichier déjà existant, vous aurez une boite de dialogue de confirmation :
|
|
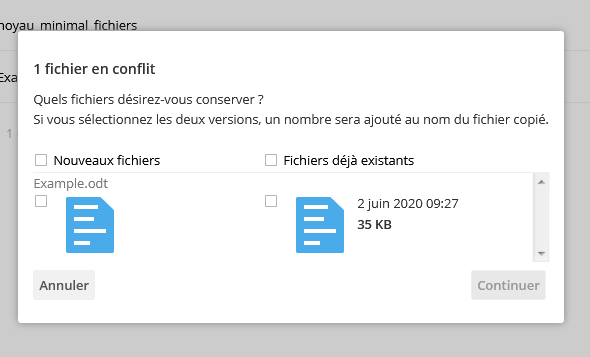
4-2-8. Administration▲
L'accès à l'interface d'administration s'effectue par l’icône crantée en haut à droite :
|
|
Pour revenir à l'écran des fichiers, il faudra cliquer sur paramètre à gauche :
|
|
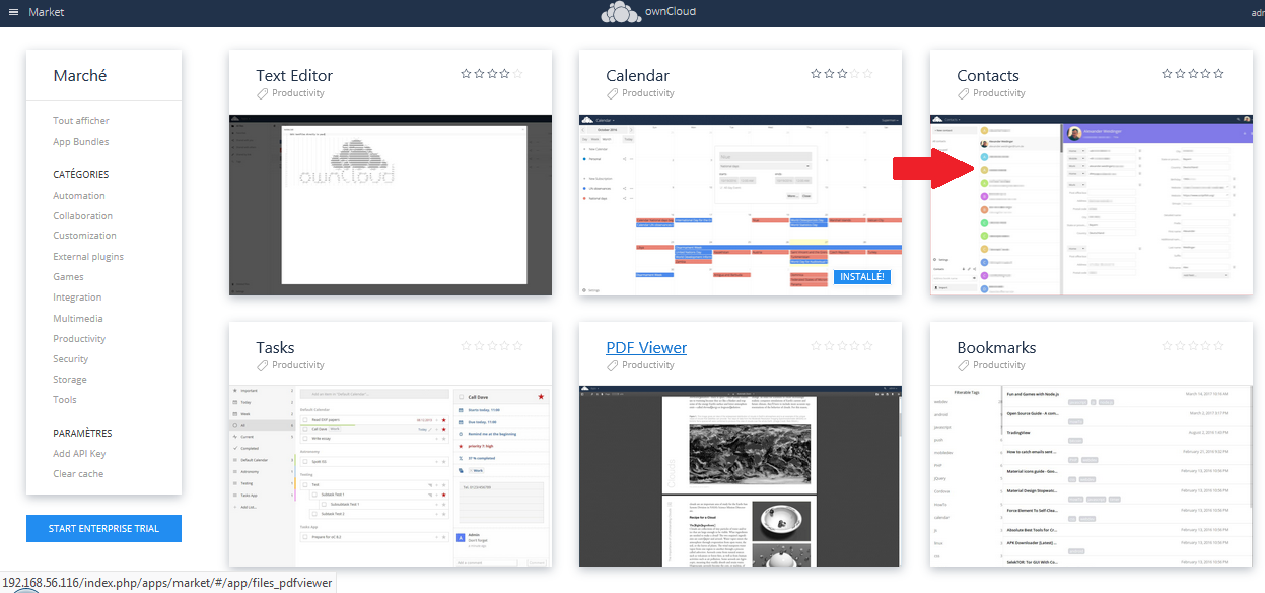
L’icône « Market » vous servira à ajouter des applets non natives à ownCloud. Nous en verrons certaines ultérieurement.
Vous pouvez avoir plus d'informations sur les applets ownCloud sur le site https://marketplace.owncloud.com.
Vous aurez les options suivantes :
- Paramètres ;
- Utilisateurs ;
- Se déconnecter.
L'onglet paramètres vous donnera accès à deux parties principales : Personnel et Administration.
La partie « Personnel » va concerner la configuration du compte proprement dit (avatar, adresse mail, mot de passe, langue).
Passons directement à la partie Administration.
- Personnel/Réglage stockage externe (désactivé par défaut) : donnant accès à la gestion d'espaces de stockage local, DropBox, Google Drive, SMB, S3, etc.
- Administration/Applications : permet de voir les applications activées et de les désactiver, en cliquant sur le bouton « Show disabled apps » ; il est possible de les lister et aussi de les désinstaller.
Après l'installation, seules les applications par défaut sont visibles, nous verrons plus tard comment ajouter celles qui ne sont pas présentes.
Administration/Généraux : vous verrez tout d'abord ici des avertissements sur la sécurité et la configuration. J'ai un avertissement sur le verrouillage translationnel, une recommandation sur l'utilisation de cron pour les tâches planifiées (configurable en bas de page), sur l'utilisation de HTTP au lieu de HTTPS et sur la non-présence de cache mémoire (memcached recommandé).
Ces avertissements ne sont pas bloquants.
Administration/stockage : ce menu va permettre l'usage d'un stockage externe, ceci étant désactivé par défaut et activable ici, (voir Personnel/stockage externe).
|
|
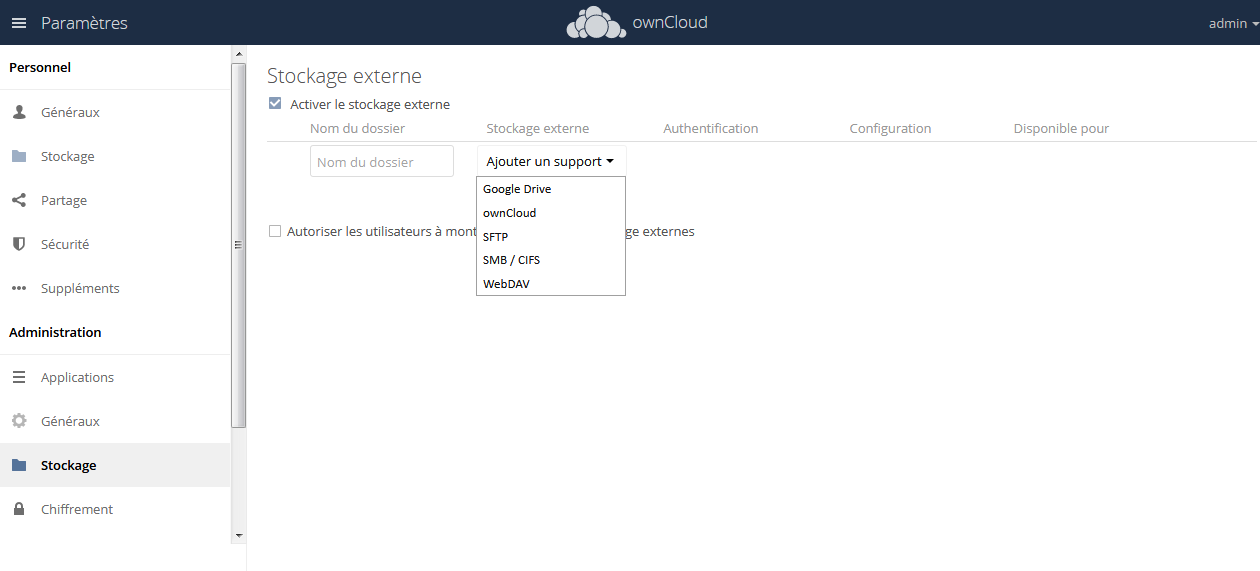
Les partages externes accessibles sont :
- Google Drive ;
- ownCloud (un autre serveur) ;
- SFTP ;
- SMB/CIFS ;
- WebDav.
Le paquet smbclient doit être installé pour pouvoir utiliser un partage SMB. ownCloud vous affichera un message en conséquence.
|
|

Il vous faudra cocher « Autoriser les utilisateurs à monter des espaces de stockage externes » pour que ceux-ci puissent y accéder.
Nous verrons alors le partage créé dans le menu Personel/stockage.
Le dossier partagé sera visible dans l'espace utilisateur avec une icône ![]() .
.
Administration/chiffrement : désactivé par défaut. Les fichiers ne sont donc pas chiffrés par défaut. Pour plus d'infos, consultez la documentation. Il vous faudra activer l'application « Default Encryption Module », que vous trouverez dans la liste des applications après avoir cliqué sur « montrer les applications désactivées ».
Une fois le module activé, dans la partie chiffrement, il vous faudra sélectionner le type de clé :
- une clé principale ;
- une clé par utilisateur.
|
|
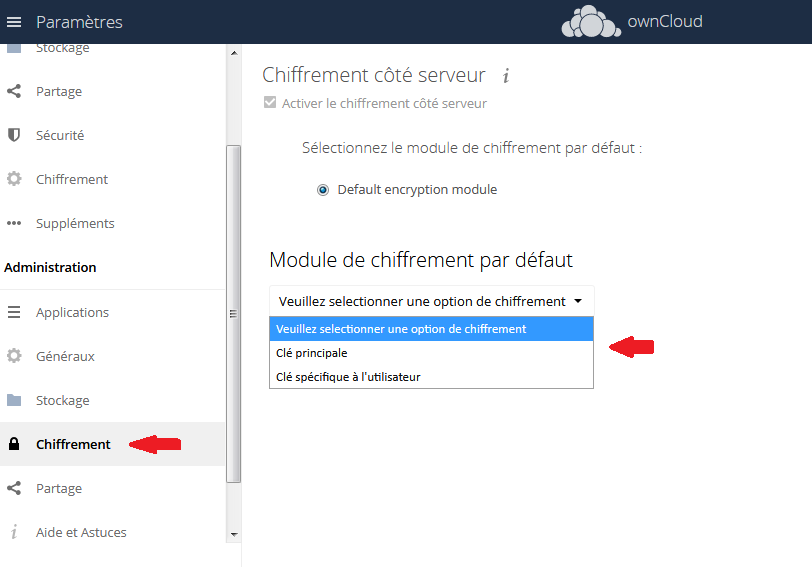
Dans le cadre du test, j'ai sélectionné une clé principale. Une fois le choix validé, il est demandé de se reconnecter.
|
|
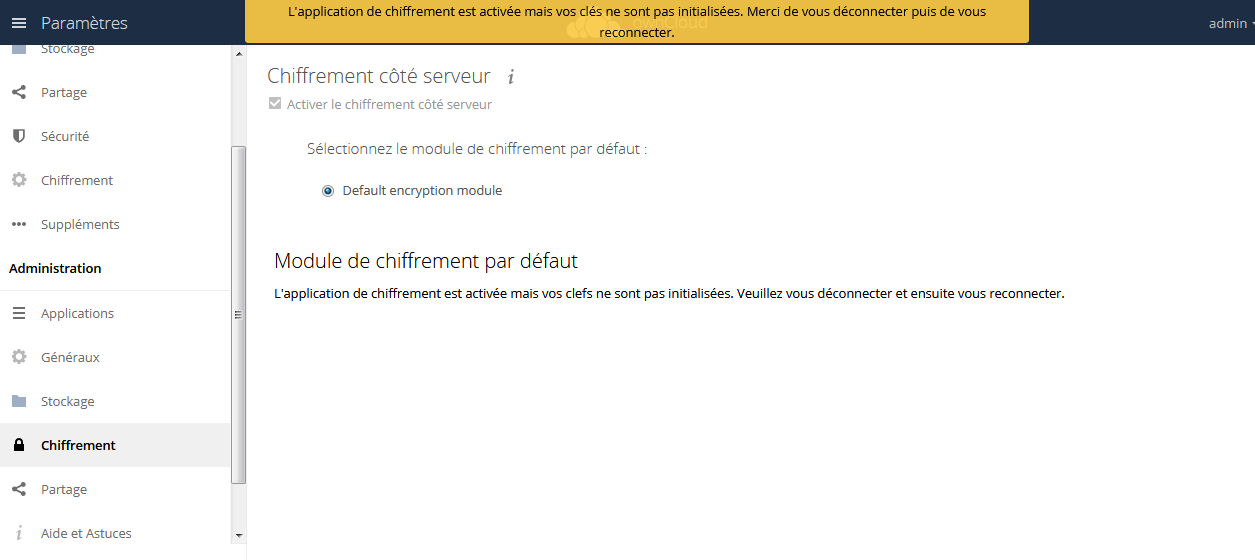
Seuls les nouveaux fichiers seront cryptés, les anciens ne le seront pas.
Seul le contenu des fichiers est crypté, pas leur nom. Un dossier files_encryption dans le dossier de l'utilisateur va contenir les éléments pour le décryptage (et notamment les clés des utilisateurs). Le dossier files_encryption du dossier data va lui contenir les fichiers de la clé maîtresse en cas de chiffrement unique pour tous les utilisateurs.
La perte des clés de cryptage entraînera l’impossibilité de lire les fichiers chiffrés.
Le téléchargement d'un fichier chiffré est transparent : il est déchiffré à la volée. Si vous désactivez le module « Encryption », la tentative de chargement du fichier déclenchera un message d'erreur :
|
|

Administration/Partage : vous trouverez ici les autorisations de partage ou repartage pour vos utilisateurs. Vous trouverez aussi les réglages concernant la fédération de serveurs ownCloud (partage d'annuaire d'utilisateurs entre plusieurs serveurs ownCloud).
Par défaut, il n'y a pas d'accès à un agenda ou à un calendrier, nous verrons cela dans les chapitres suivants.
Personnalisation de l'apparence : il existe une applet pour personnaliser l'image de fond de l'écran de connexion : « ownCloud X Enterprise Theme », extension payante, qui n'a pas été testée. Pour l'image de fond, il suffit de modifier l'image core/img/background.jpg. Pour les autres aspects, il vous faudra faire la recherche et certainement modifier les fichiers .css manuellement.
4-2-8-1. Gestion des utilisateurs▲
Pour accéder à la gestion des utilisateurs, il faut cliquer sur « utilisateurs » en dessous de « Paramètres ». Vous aurez alors accès à la gestion de ceux-ci :
|
|
Pour créer un utilisateur, il suffit d'entrer son login et son adresse mail. Une fois l'utilisateur créé, il faudra positionner son mot de passe. Vous pouvez créer des groupes, ceux-ci permettant de régler par exemple les droits de partage entre utilisateurs. Vous pouvez aussi mettre un quota disque à ceux-ci. Attention à ne pas mettre un utilisateur dans le groupe « admin » s‘il ne doit pas l'être.
En cliquant sur l’icône de roue crantée en bas à gauche, vous aurez des options supplémentaires, telles que l'affichage de l'adresse mail, le dossier de données, ou la provenance de l'utilisateur (base interne, connexion externe telle que LDAP).
Suppression
La suppression d'un compte via l’icône ![]() à sa droite va supprimer les fichiers de celui-ci. Vous aurez une demande de confirmation :
à sa droite va supprimer les fichiers de celui-ci. Vous aurez une demande de confirmation :
|
|

4-2-8-2. Authentification via LDAP▲
Si vous utilisez un serveur LDAP, vous pourrez l'utiliser pour authentifier vos utilisateurs sur ownCloud. Il vous faudra ajouter l'applet « LDAP Integration » dans la catégorie « Integration ».
L'installation d'un serveur LDAP sera présentée au chapitre 9.2LDAP.
Une fois l'applet installée, il faudra la configurer dans le menu « Paramètres ».
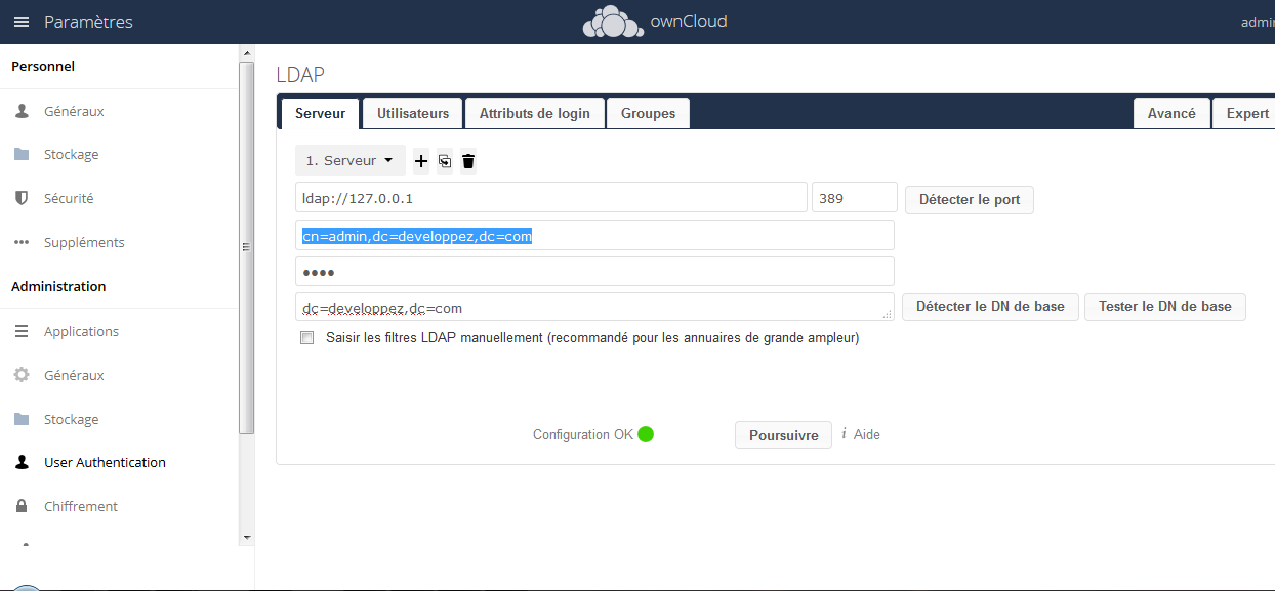
Dans le premier écran « Serveur », il faudra entrer :
- l'adresse du serveur : dans notre exemple ldap://127.0.0.1 (dans ce cas, un serveur LDAP installé sur la même machine que ownCloud, à adapter à votre situation), puis cocher « Détecter le port » (cela ne fonctionnera pas si vous avez changé le port par défaut) ;
- le nom d'utilisateur : dans notre cas d'exemple cn=admin,dc=developpez,dc=com ;
- le mot de passe ;
- le DN de base : dans notre cas dc=developpez,dc=com.
Une fois les éléments entrés, cliquez sur « Tester le DN de base », si vos informations sont correctes, vous aurez « configuration OK » :
|
|
Cliquez ensuite sur poursuivre, puis basculez sur l'onglet attributs de login.
Sélectionnez ensuite Autres attributs : cn :
|
|
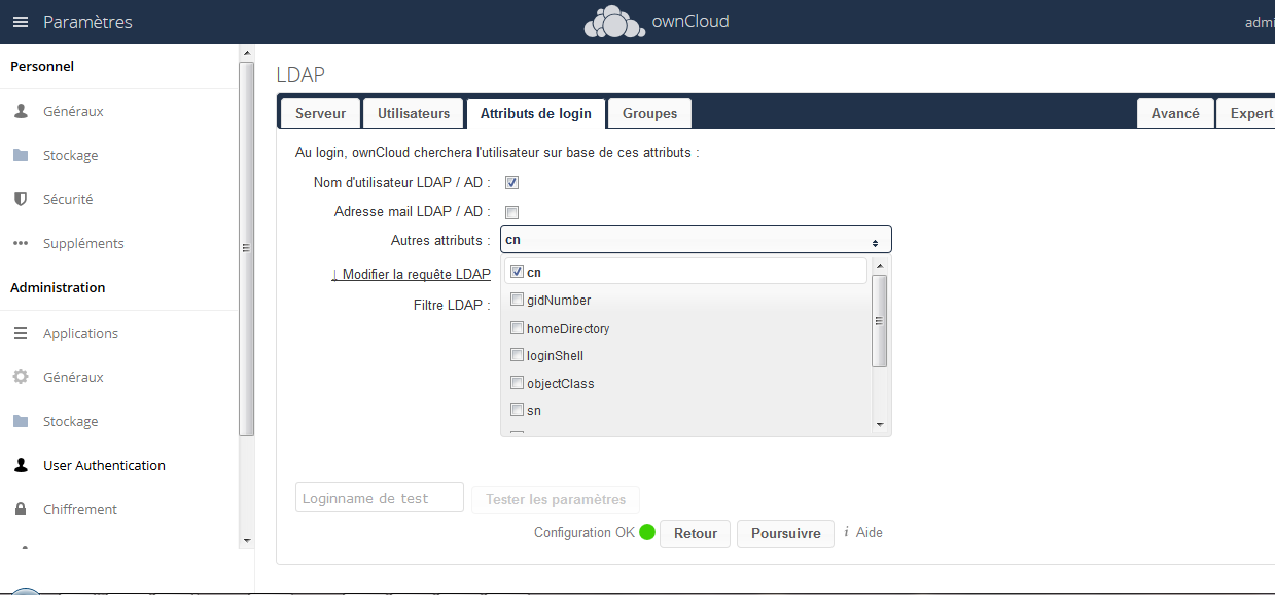
Ne maîtrisant pas LDAP, les réglages ne sont peut-être pas optimaux, mais sont fonctionnels dans ce cas de figure.
Nous allons ensuite dans les réglages avancés :
|
|
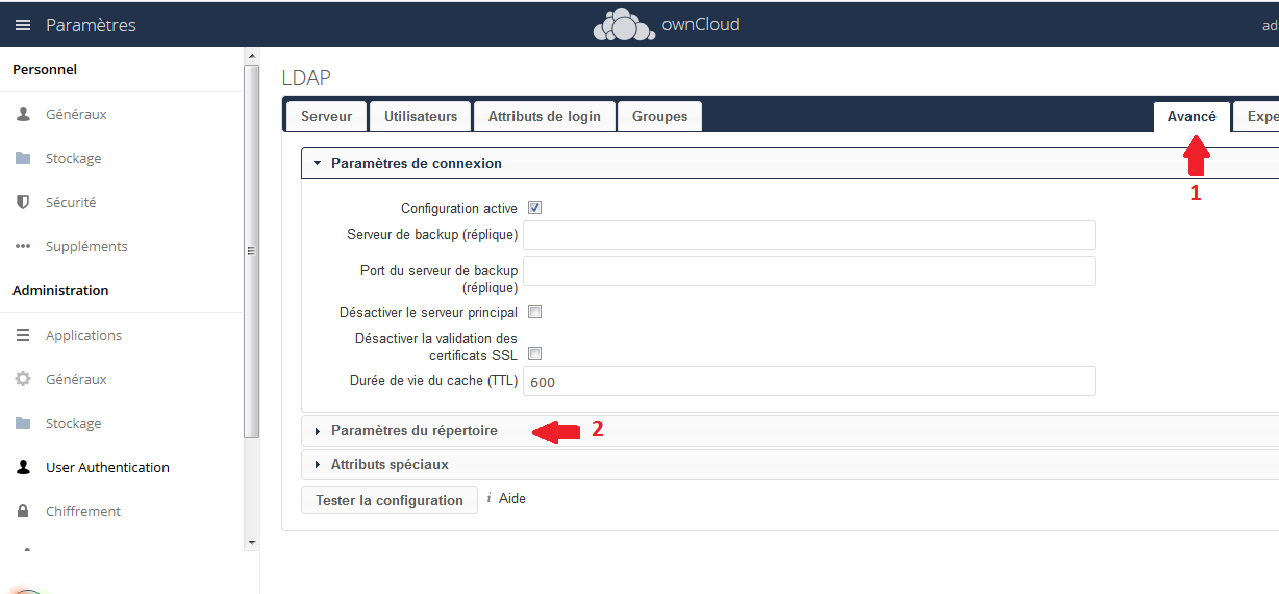
Dans les paramètres du répertoire (2), je saisis en suite « cn » dans le champ nom d'affichage de l'utilisateur. Si ce réglage n'est pas positionné, le nom d'utilisateur qui apparaîtra sera l'UUID de celui-ci (champ LDAP entryUUID).
Dans les Attributs spéciaux (3), je saisis également « cn » dans le champ règle de nommage du répertoire utilisateur, pour que le dossier contenant les fichiers de l'utilisateur ne soit pas l'UUID.
En cas de suppression du compte dans ownCloud, ceci n’impactera pas le compte LDAP, ce qui est logique, car d'autres services peuvent être utilisés par ce compte LDAP.
En cas de suppression du compte LDAP, l’utilisateur ne pourra plus s'identifier, mais son compte reste présent dans la liste des utilisateurs ownCloud ainsi que ses données. Il suffit de recréer le compte dans l'annuaire LDAP avec le même nom pour récupérer l'accès.
Il est beaucoup plus simple de gérer l'authentification directement depuis la base ownCloud, mais cela vous obligera à maintenir plusieurs bases d'authentification en cas d'autres services utilisés tels qu'un serveur mail.
4-2-9. Édition de documents en ligne▲
ownCloud dispose d'un connecteur OnlyOffice, ainsi que d'un connecteur Collabora.
Collabora est basé sur LibreOffice.
Dans les deux cas, il vous faudra effectuer le paramétrage depuis « Paramètres » → « suppléments », une fois le serveur installé (hors périmètre ownCloud).
4-2-10. Sauvegarde▲
Pour sauvegarder OwnCloud, il vous faut sauvegarder le dossier des données (dossier data) ainsi que la base de données.
4-2-11. Connexion à partir du client Windows▲
|
|
La connexion au serveur se fait en HTTP/HTTPS :
|
|
Nous avons la demande d'authentification :
|
|
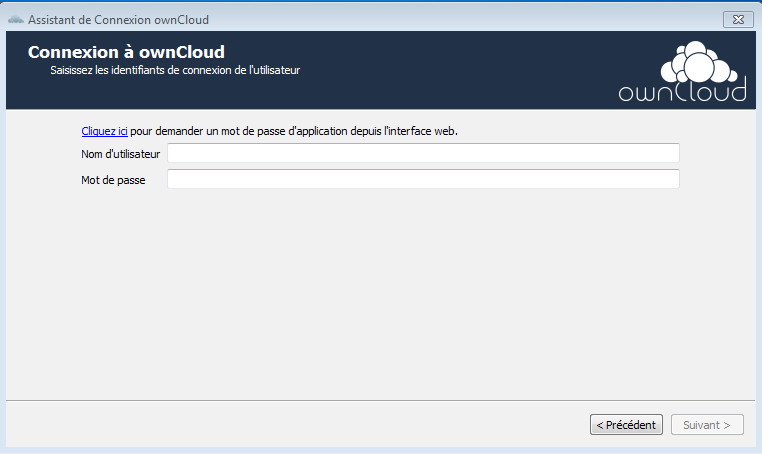
Une fois les identifiants saisis, vous aurez accès aux réglages par défaut :
|
|
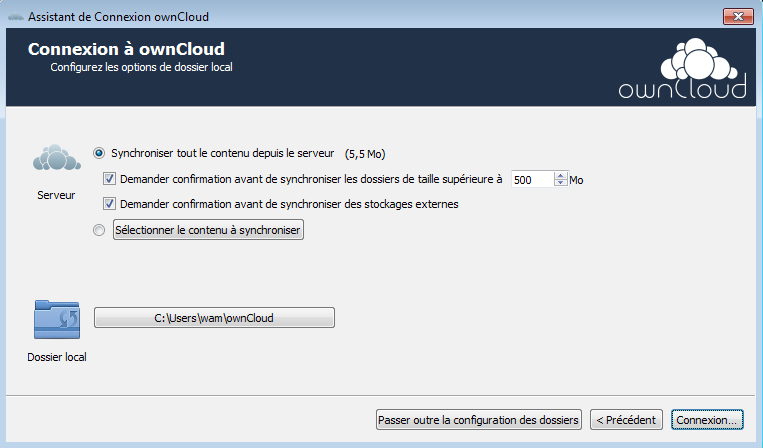
La première partie permet le choix de récupérer les fichiers déjà présents sur le serveur, la seconde concerne les dossiers à synchroniser, où préciser ce que vous souhaitez synchroniser. Ce sera par défaut le dossier ownCloud stocké dans votre profil utilisateur, vous pouvez changer celui-ci.
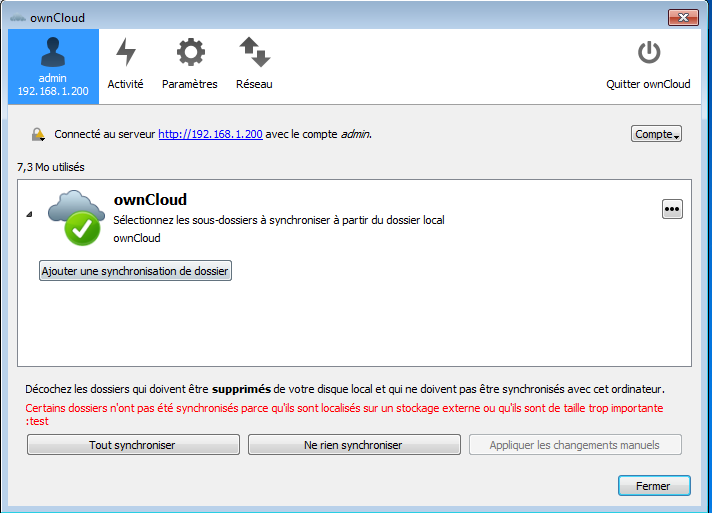
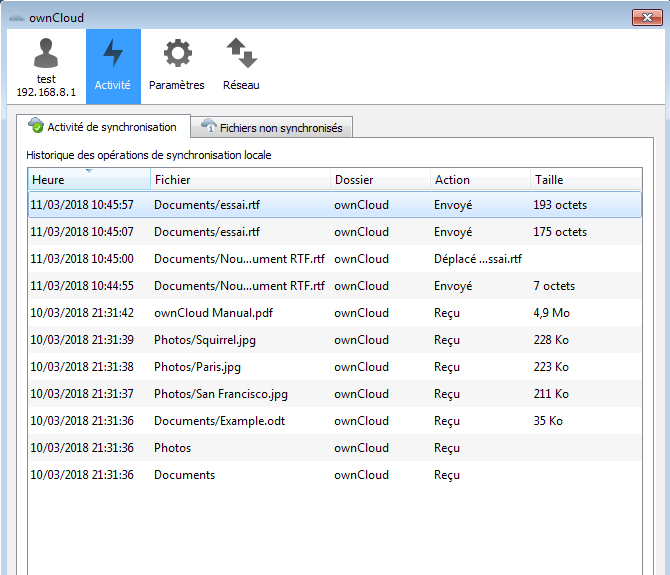
Une fois la connexion effectuée, vous aurez une icône dans la barre des tâches, ouvrant le tableau de bord ownCloud. Vous serez par défaut sur l'onglet « Activité », montrant les derniers fichiers synchronisés.
|
|
L’icône « Paramètres » donne accès aux réglages tels que le démarrage automatique d'ownCloud quand le système démarre, et aussi l'accès à une liste des fichiers exclus.
Par défaut, les fichiers cachés ne sont pas synchronisés, il faut entrer dans la liste des exclusions pour cocher leur synchronisation.
|
|
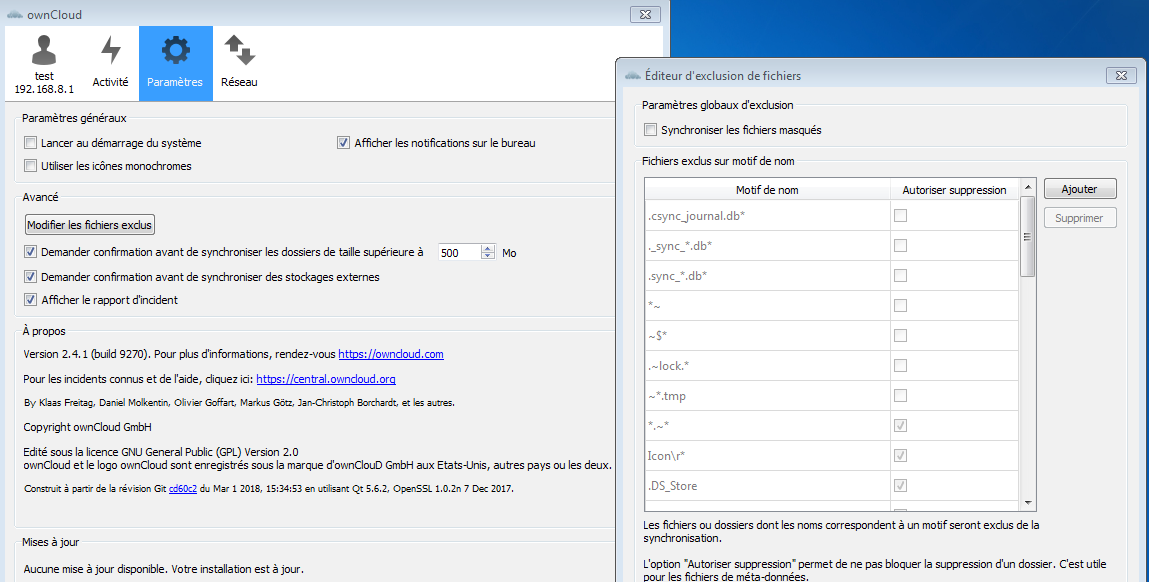
L’icône réseau permet d'indiquer un proxy si ceci est nécessaire, et de limiter l'usage de la bande passante si vous le souhaitez.
L’icône utilisateur vous permet de changer les réglages de synchronisation, forcer la mise à jour de la synchronisation. Une autre option intéressante : la possibilité de synchroniser plusieurs comptes, dans ce cas, ownCloud va créer par défaut un autre dossier (owncloud2 dans mon cas, l'application va créer un dossier avec le nom incrémenté). Vous aurez ensuite une nouvelle icône concernant le nouvel utilisateur.
|
|
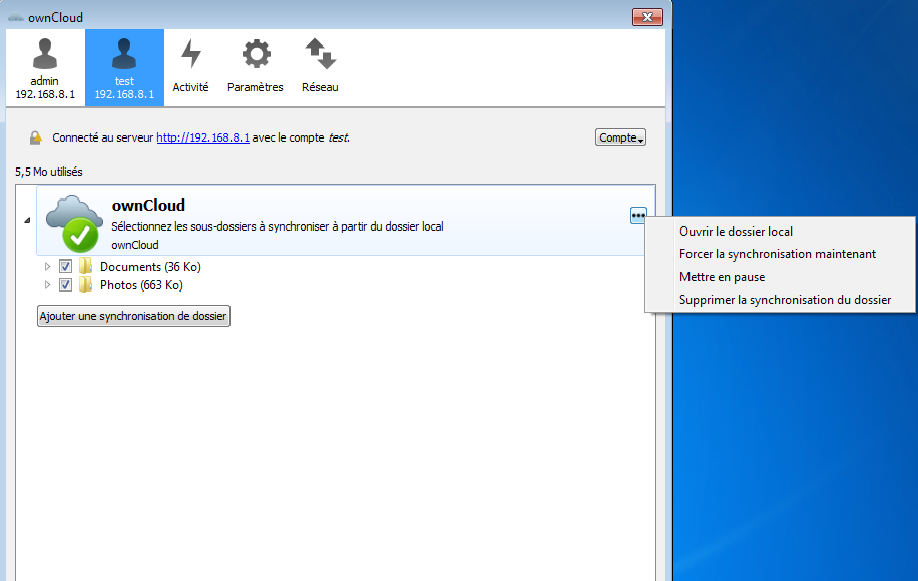
Pour ajouter un compte, il faut cliquer sur le bouton compte, puis ajouter un nouveau compte. Vous pouvez à partir de ce bouton vous déconnecter ou supprimer le compte.
Le ou les dossiers contenant les données synchronisées ne sont pas supprimés.
4-2-11-1. Partage de documents▲
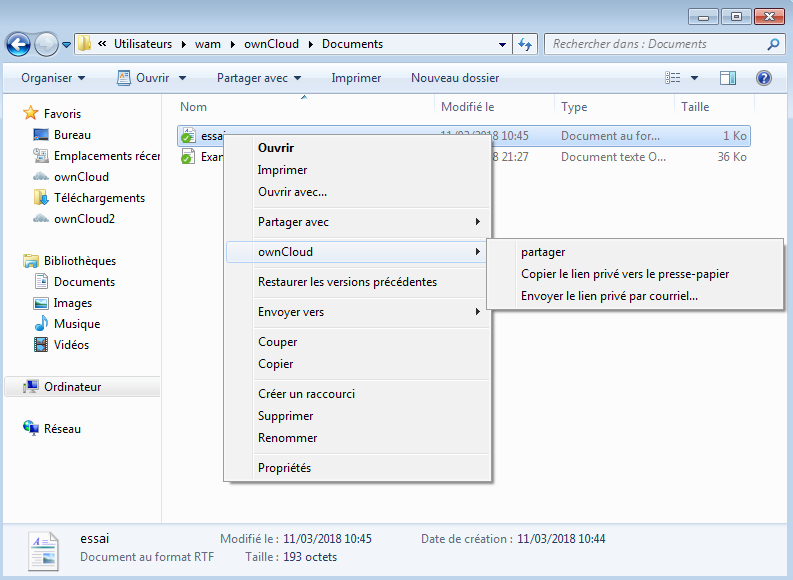
Nous avons vu comment partager un document depuis l'interface web. Il est également possible de le faire depuis l'explorateur de fichiers.
|
|
|
|
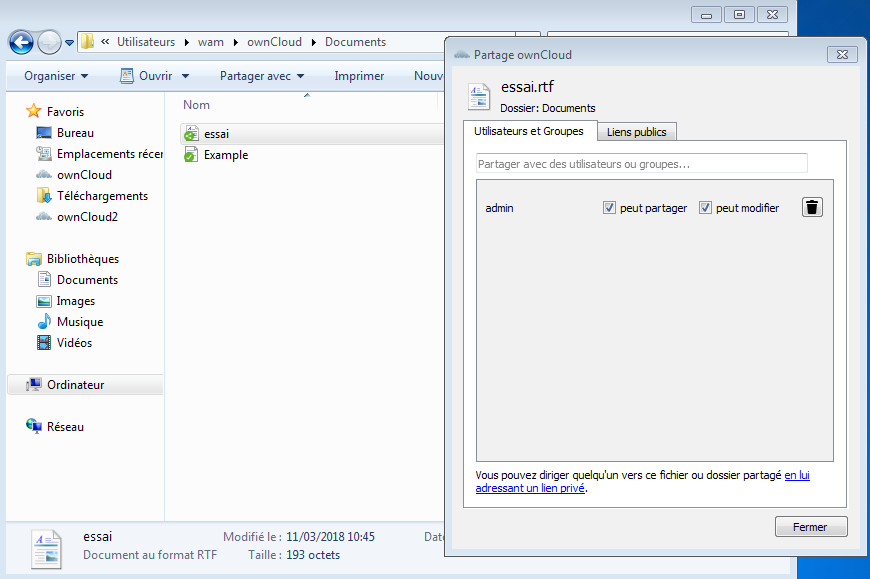
L'onglet lien public permet de générer un lien accessible depuis une URL (avec ou sans mot de passe et possibilité d'expiration), si l'administrateur ownCloud vous le permet :
|
|
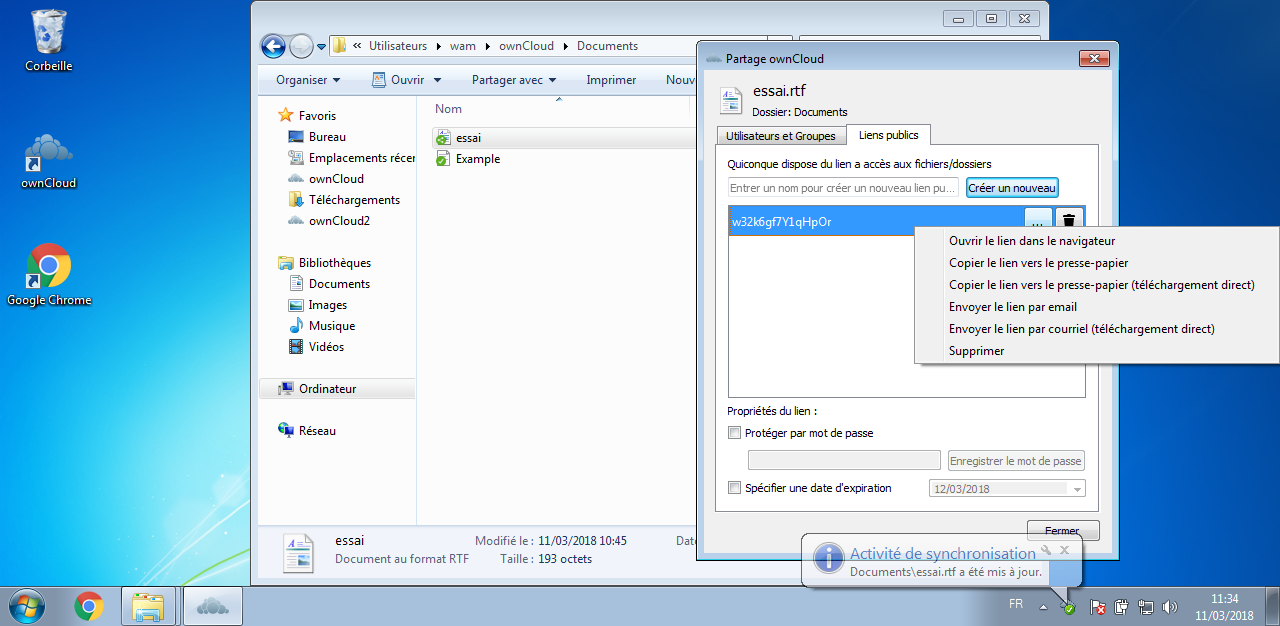
Vous pourrez envoyer directement le lien par mail, le copier dans le presse-papier, etc.
Le destinataire aura un lien tel que celui-ci :
|
|
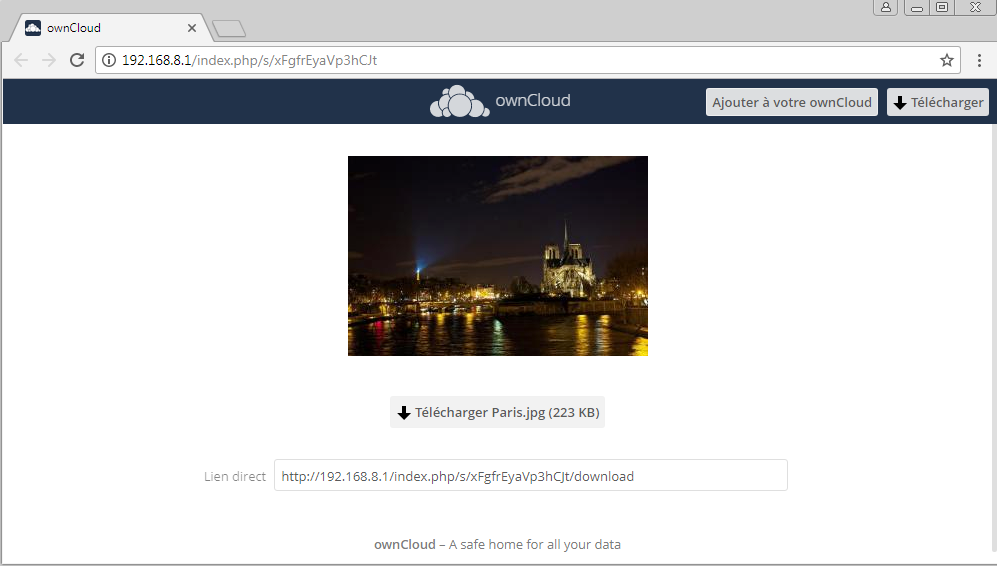
Un test de partage de fichier RTF m'a provoqué l'affichage du contenu du fichier RTF comme un document texte, alors qu'un document avec une extension inconnue va afficher un simple logo générique.
Versions des documents
Il n'est pas possible d'accéder aux versions des documents depuis le client, l'accès doit se faire depuis l'interface web.
Suppression de documents
La suppression d'un document déclenche sa suppression immédiate sur le serveur (enfin son déplacement vers la corbeille). Le document est restaurable depuis la corbeille Windows/Linux/Mac OS. Vous perdrez par contre l’historique des versions.
4-2-12. Agenda partagé▲
Pour avoir accès à l'agenda, il faut commencer par activer l'applet correspondante. Vous trouverez celle-ci dans le market (accès réservé aux administrateurs) :
|
|
Vous aurez alors accès aux applets rangées par catégorie.
|
|
L'ordre d'affichage des icônes dépendra de votre résolution d'écran. Ne soyez donc pas surpris de les voir dans un ordre différent.
L'applet calendrier se trouve dans la section « Productivity » :
|
|
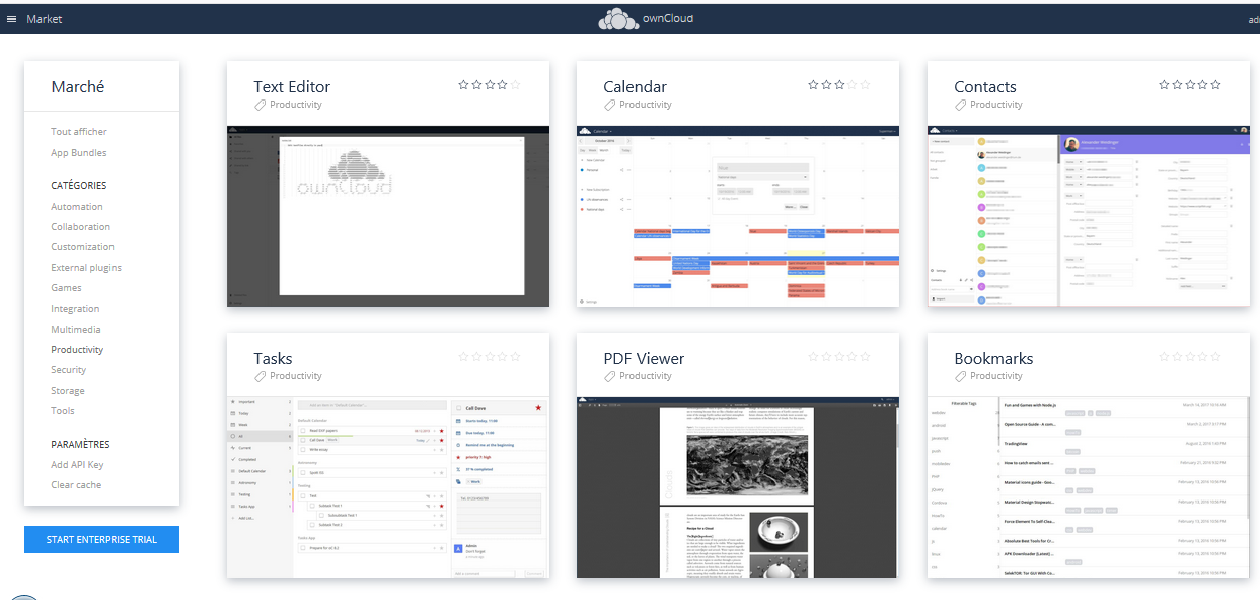
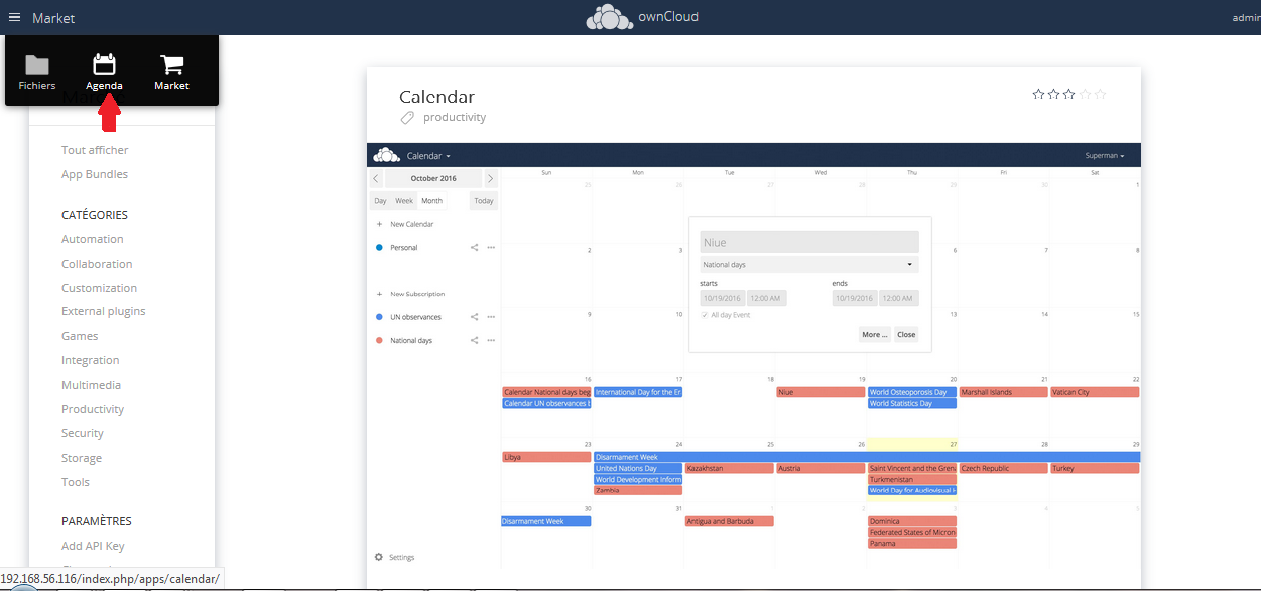
Il suffit de cliquer sur l'image de l'applet, puis sur le bouton « Installer ».
|
|

Une fois celle-ci installée, elle est disponible dans le menu en haut à gauche :
|
|
|
|
|
|
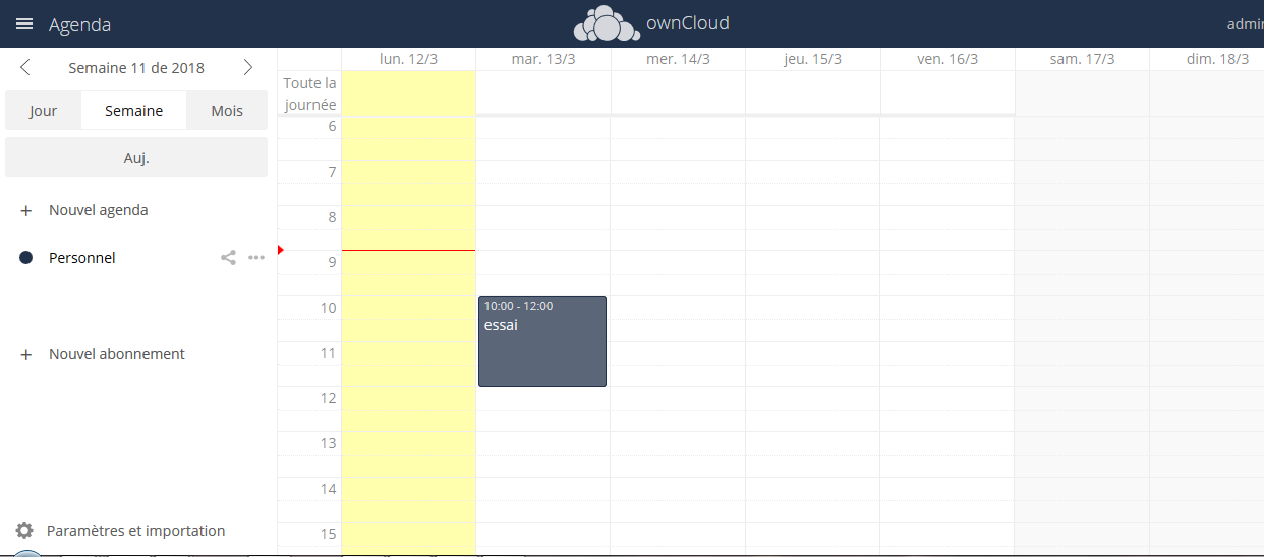
Vous pourrez ajouter des participants en appuyant sur plus :
|
|
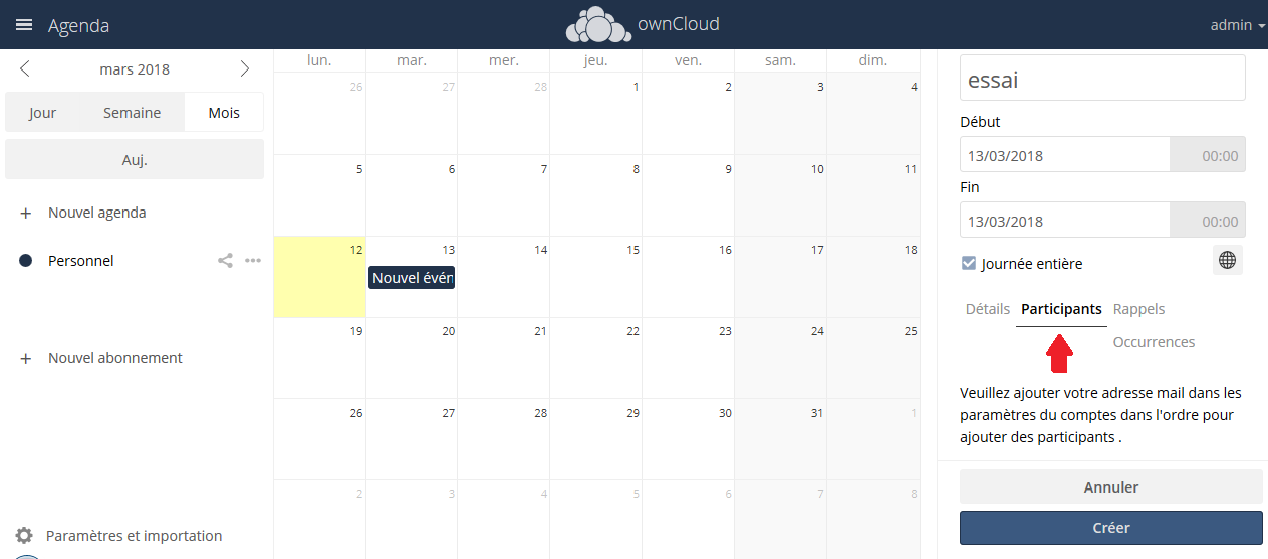
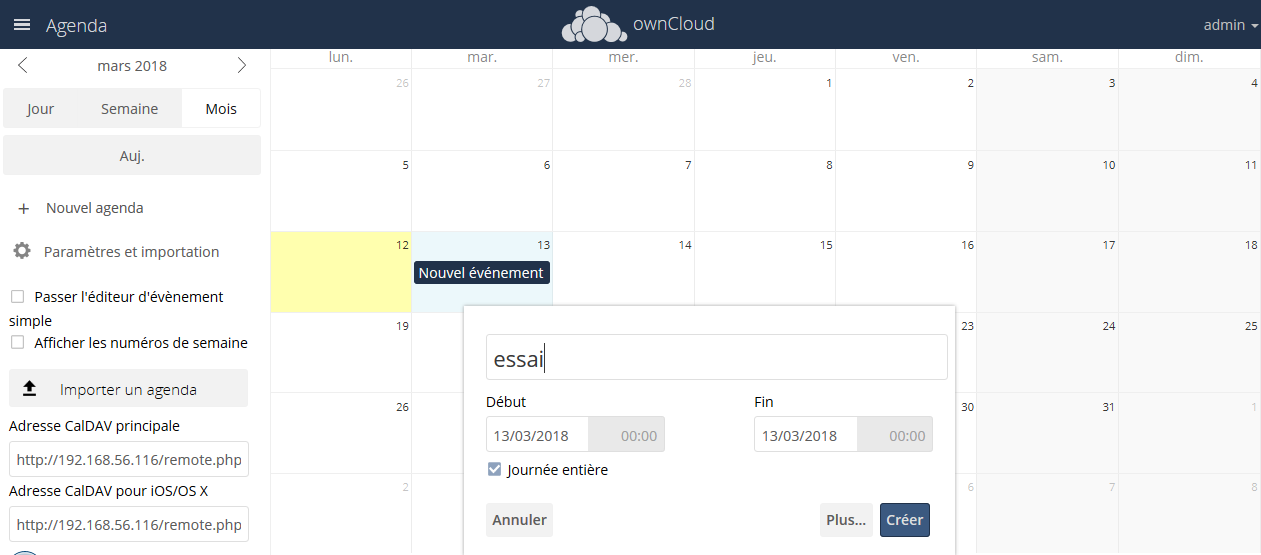
Vous pouvez déplacer un rendez-vous par simple glisser-déplacer.
4-2-12-1. Installation dans Thunderbird▲
Nous aurons besoin pour commencer du lien CalDAV généré par ownCloud. Nous le trouverons en cliquant sur les … à côté du nom de l'agenda :
|
|
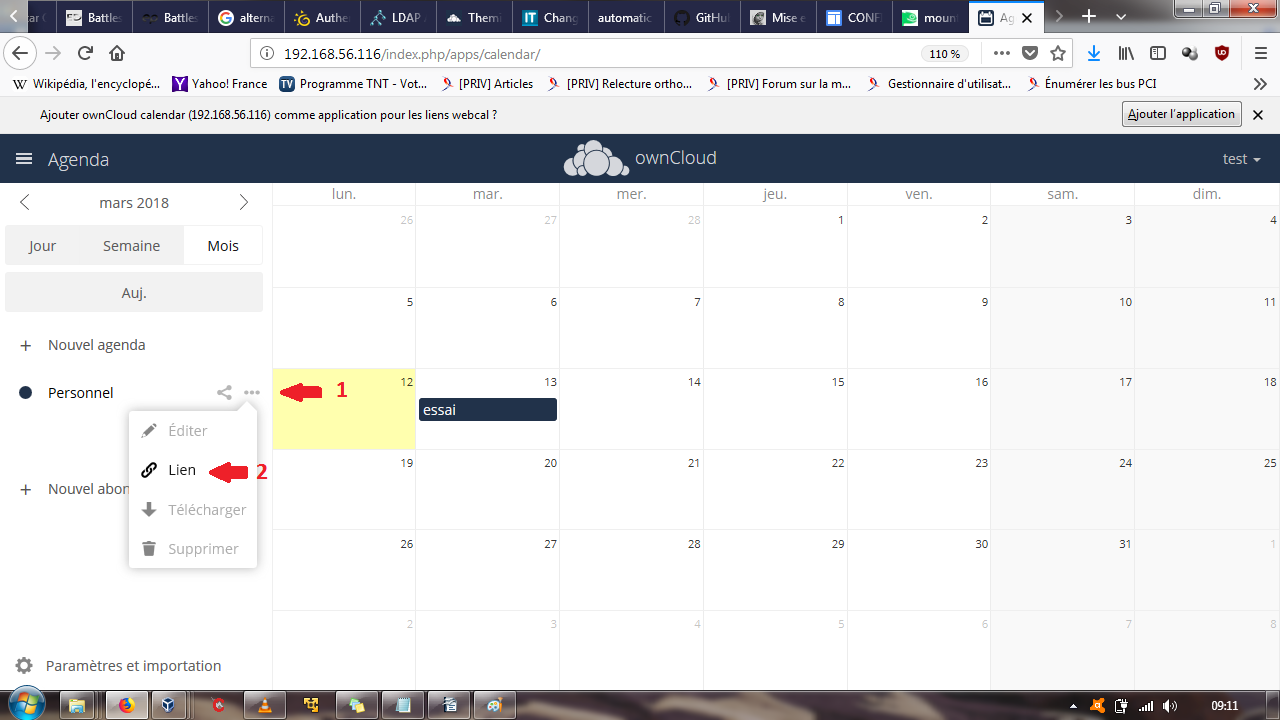
Dans mon cas : http://192.168.56.116/remote.php/dav/calendars/test/personal/
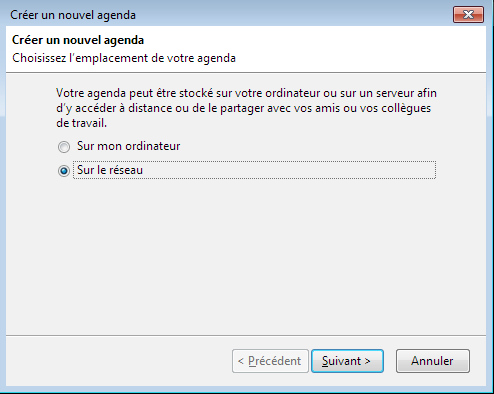
Pour intégrer un agenda CalDAV, il vous faudra aller dans le menu fichier->nouveau->agenda
Sélectionner ensuite agenda sur le réseau :
|
|
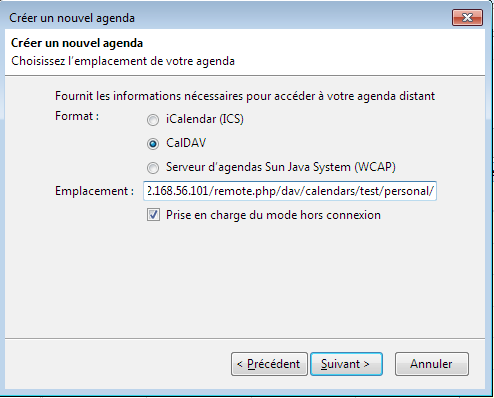
Il faudra ensuite sélectionner « CalDAV » et entrer l'URL indiquée dans l'interface web.
|
|
|
|
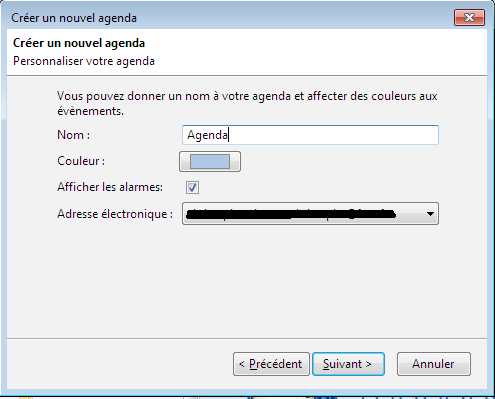
Après un nom d'agenda, Thunderbird vous demandera l’identifiant et le mot de passe :
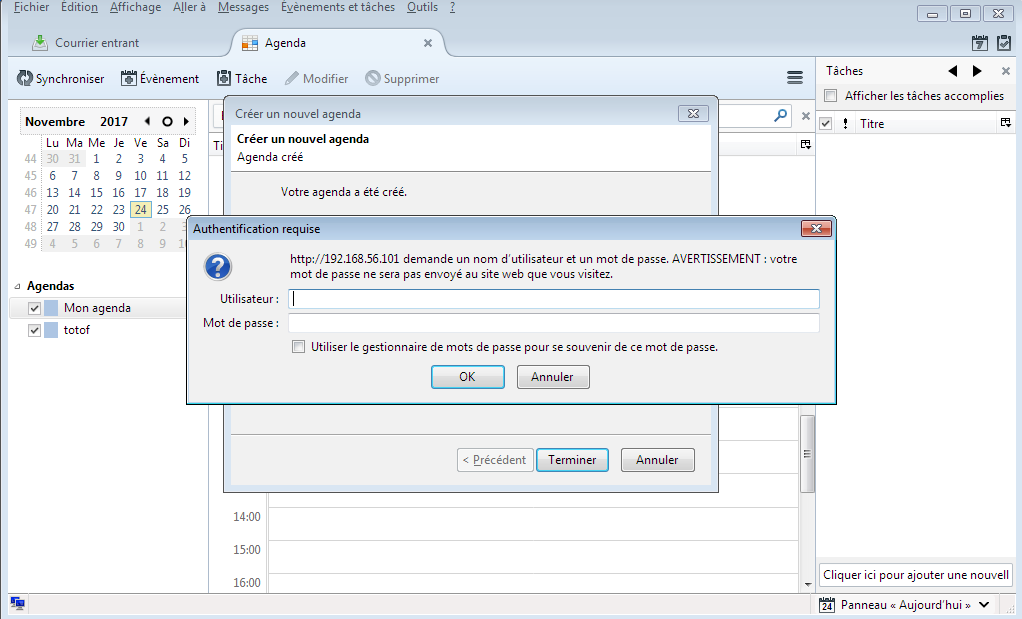
|
|
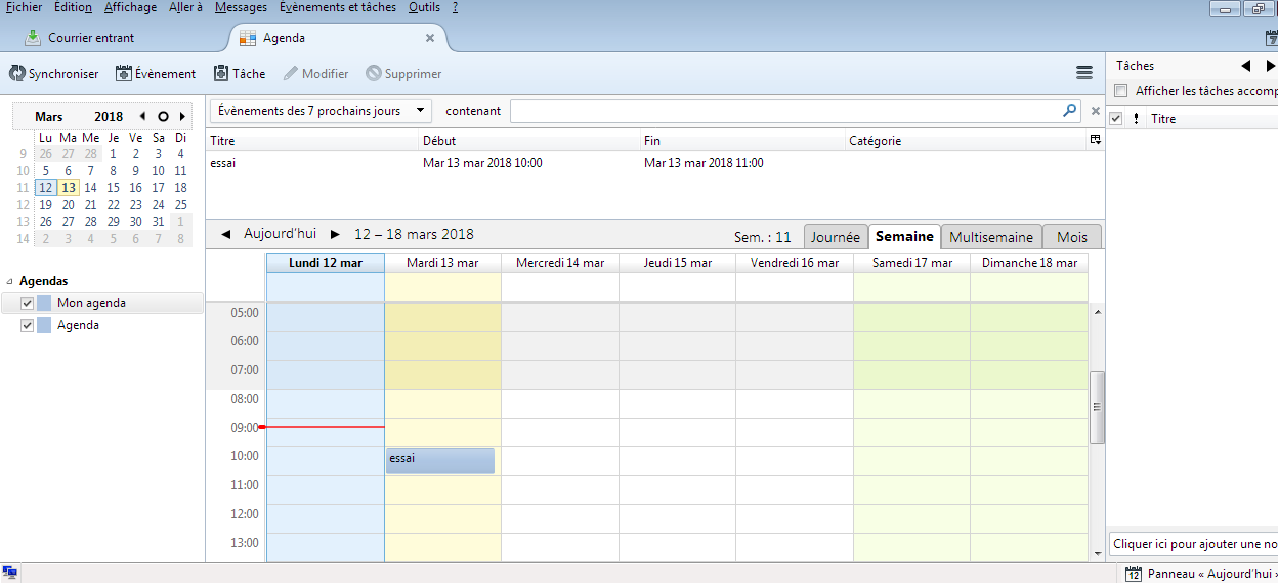
Votre agenda est ensuite disponible :
|
|
Pensez à faire attention à l'agenda où est stocké l’événement, il y a toujours un agenda local. Mettez l'agenda en ligne par défaut. Vous pouvez désactiver l'agenda local si vous ne l'utilisez pas.
En cas de déconnexion réseau, si le mode hors connexion a bien été coché lors de la création de l’agenda dans Thunderbird (par défaut), vous pourrez toujours modifier l'agenda. Lors de votre retour sur Internet, il y aura un petit ralentissement, le temps de la resynchronisation.
4-2-12-2. Calendrier avec Outlook▲
Il nous faut installer l'application caldav synchroniser disponible sur SourceForge :
https://sourceforge.net/projects/outlookcaldavsynchronizer/
L’application requiert Visual C 2010 redistributable et .net framework 4.5 qui seront installés automatiquement si nécessaire.
Une fois l'installation terminée un onglet supplémentaire apparaîtra dans Outlook :
|
|
|
|
Ceci va ouvrir la fenêtre de gestion des profils à partir de laquelle nous allons ajouter un profil :
|
|
Nous cliquons sur le plus pour avoir l'écran suivant :
|
|

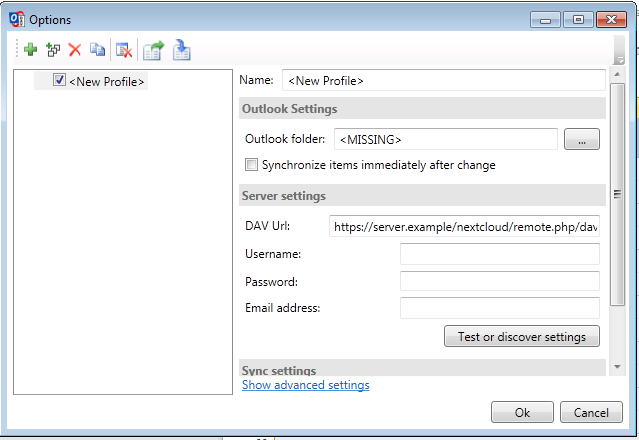
Nous restons sur « générique » et entrons ensuite les paramètres :
|
|
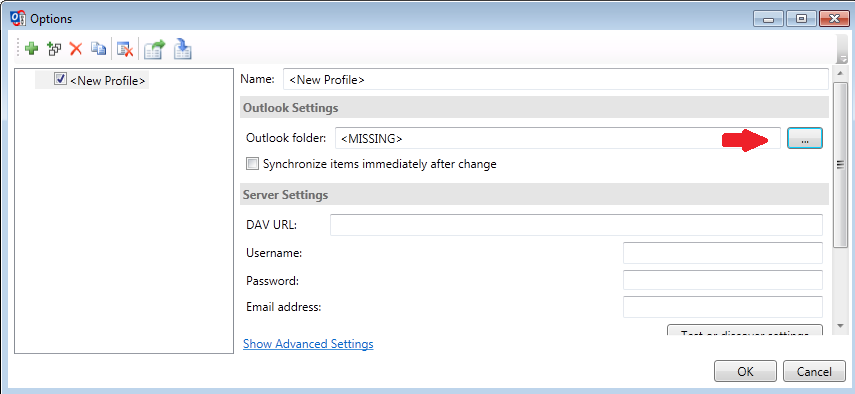
Je sélectionne le dossier de synchronisation du calendrier et rentre les paramètres :
|
|
|
|
|
|
|
|
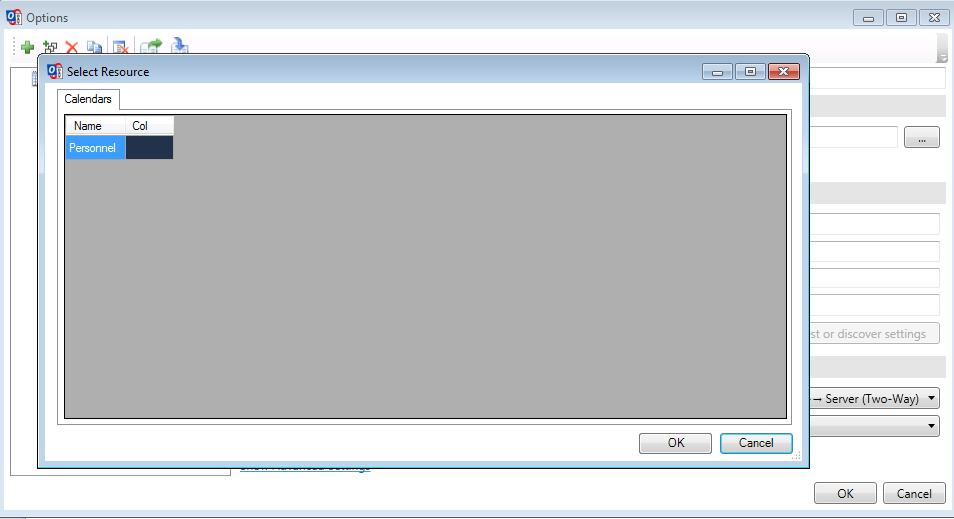
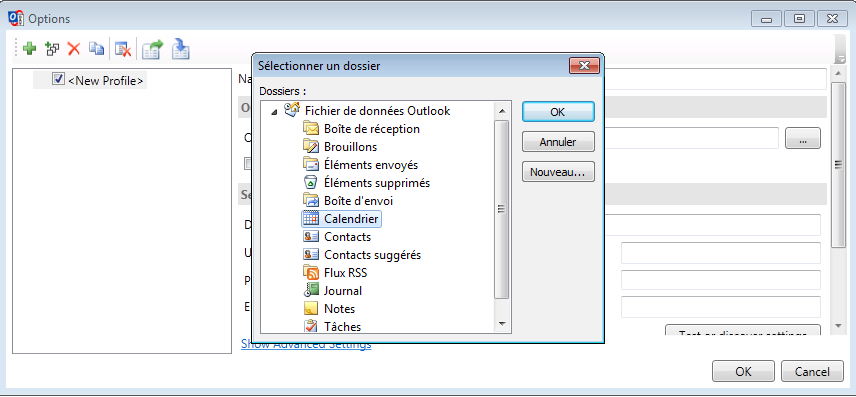
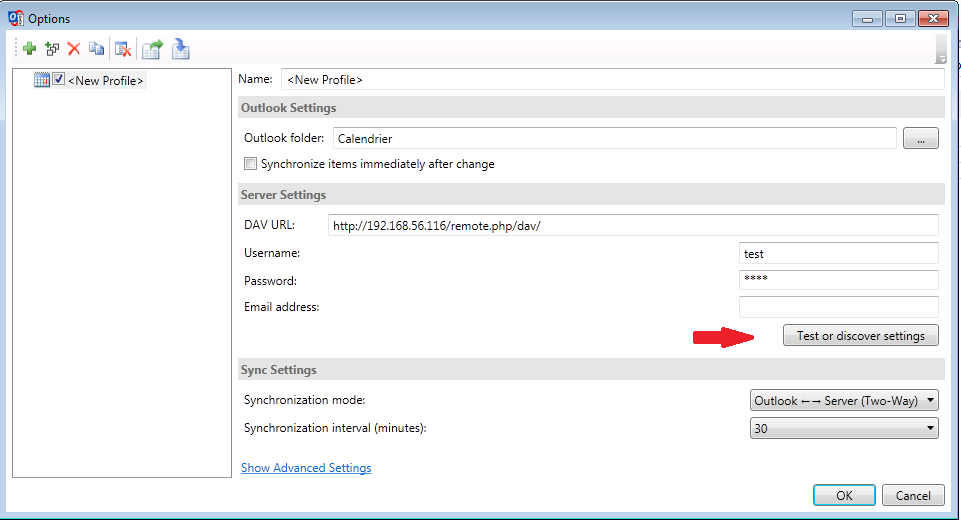
Vous pouvez régler le sens de la synchronisation (bi-directionel, Outlook vers serveur, serveur vers Outlook) et la fréquence de celle-ci.
Contrairement à Thunderbird, la synchronisation se fait depuis l'agenda local (on peut sélectionner le dossier de synchronisation, il est donc possible de créer un agenda spécifique dans le fichier Outlook par défaut ou dans un fichier Outlook secondaire présent dans le profil.
Comme nous sommes en train de parler de Outlook, j'en profite pour vous informer qu'un plugin payant permet d'interfacer Outlook avec Owncloud. Celui-ci étant payant, il n'a pas été testé.
4-2-13. Utilisation depuis Mac OS X ou iOS avec l'application Calendrier▲
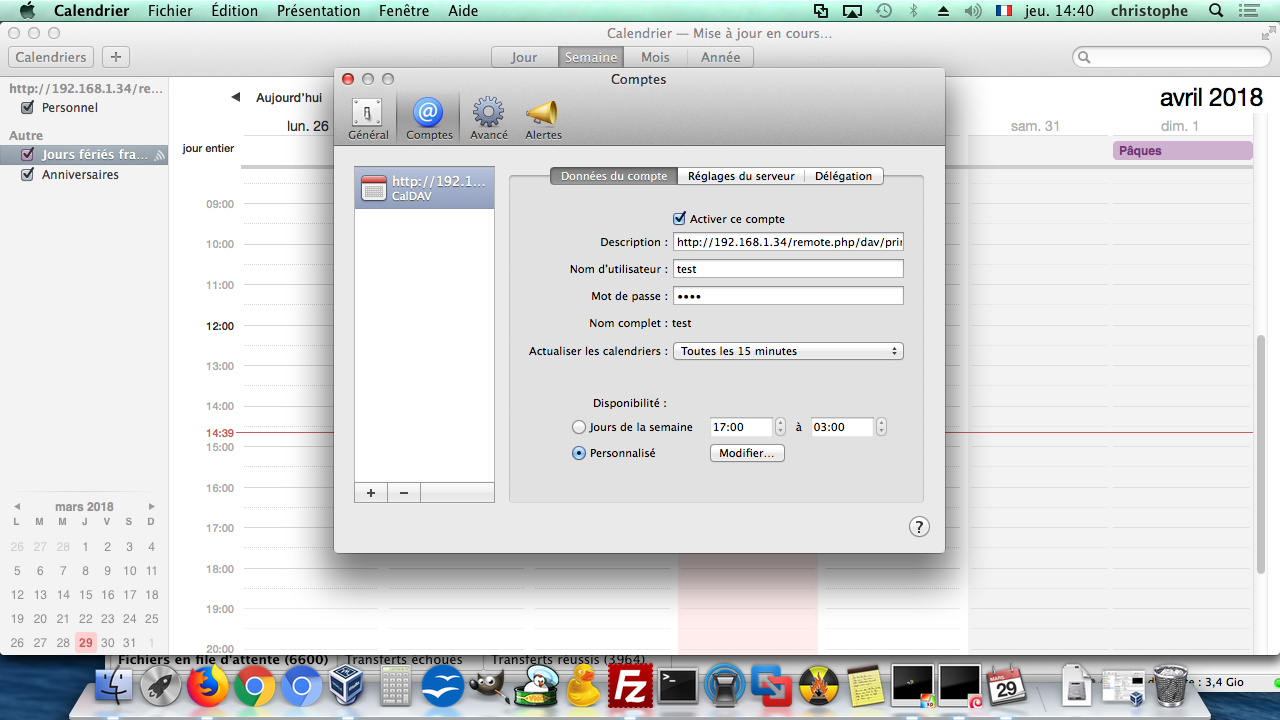
L'application Calendrier (anciennement nommée iCal) synchronise les agendas sur la solution cloud d'Apple iCloud via le protocole CalDAV. Il suffit donc de se connecter via CalDAV sur le serveur ownCloud.
L'URL de connexion pour calendrier est différente que pour les autres serveurs.
Adresse normale :
http://adresse IP/remote.php/dav/
Adresse pour iOS/OS X :
http://adresse IP/remote.php/dav/principals/users/test/
Pour créer le compte, il faut aller soit dans fichier/comptes de l'application Calendrier, soit dans préférences systèmes/comptes Internet.
Vous aurez alors l'écran suivant, où il faudra sélectionner « compte CalDAV » :
|
|

Si vous passez par le menu pomme → préférences systèmes → comptes Internet, il faudra sélectionner « autre » sur le premier écran pour avoir accès à CalDAV (ou CardDAV pour les contacts que nous verrons plus tard).
Il faudra ensuite sélectionner manuel dans le champ « type de compte » et entrer les identifiants et l'URL de connexion :
|
|
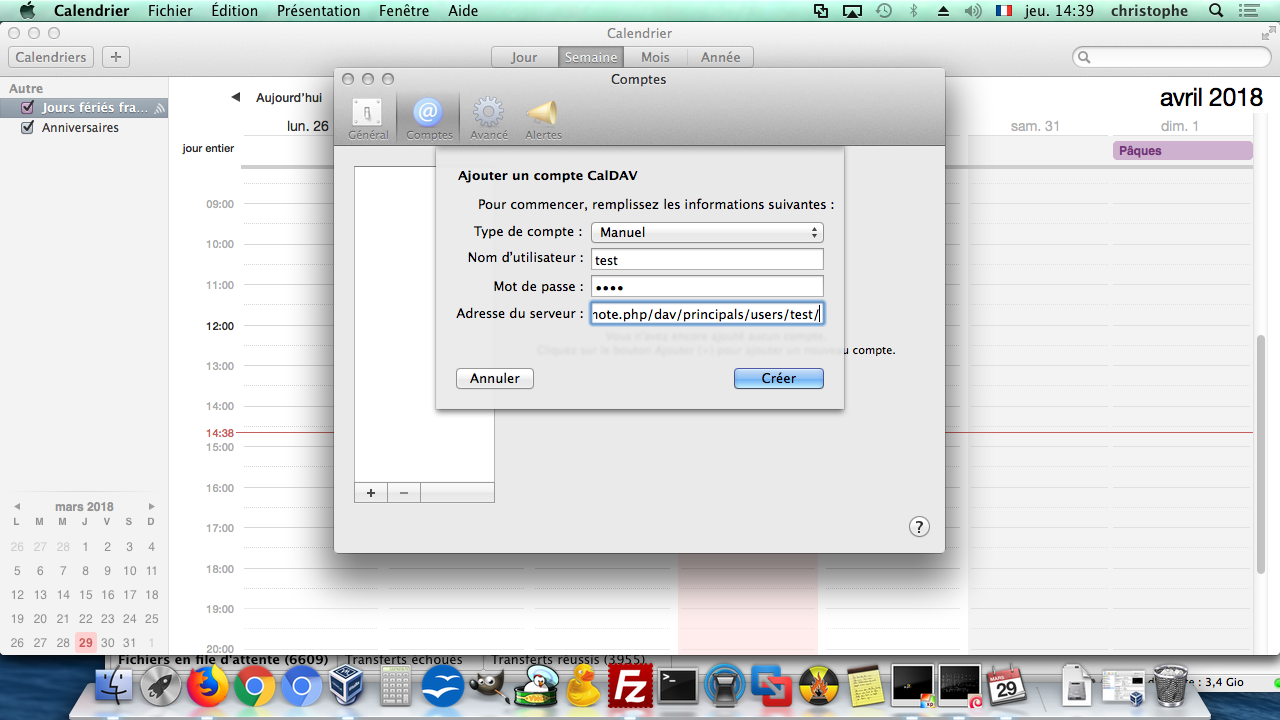
Vous pourrez ensuite régler la fréquence de synchronisation, ainsi que les réglages d'affichage de l'agenda (heure début-fin de journée, etc.) :
|
|
4-2-14. Partage de contacts▲
Il faut tout d'abord activer l'application dans ownCloud, tout comme pour l'agenda :
|
|
Tout comme pour l'agenda, une icône supplémentaire sera ajoutée dans la barre de gauche (![]() ).
).
Tout comme pour le calendrier, nous récupérons le lien (CardDAV) :
|
|
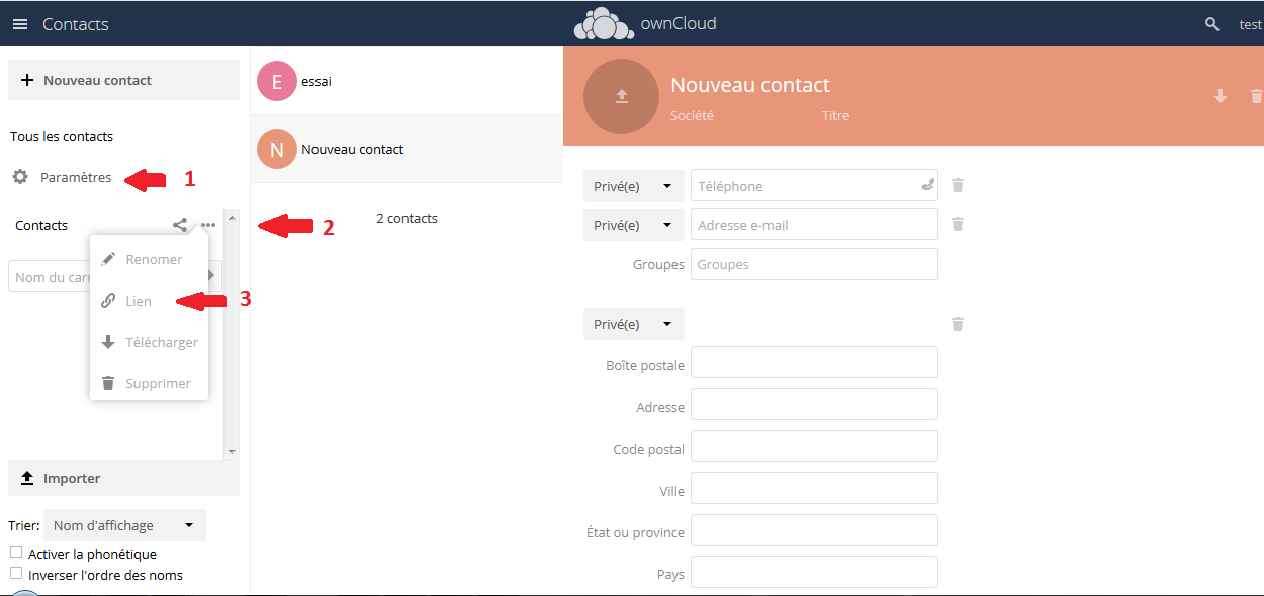
Dans mon exemple : http://192.168.56.116/remote.php/dav/addressbooks/users/test/contacts/
4-2-14-1. Thunderbird▲
Nous allons utiliser l'extension Thunderbird CardBook que nous téléchargeons et installons depuis le menu « Outils » → « modules supplémentaires ». Après redémarrage, il faudra intégrer les carnets d'adresses de base à CardBook.
|
|
|
|
Par défaut CardBook va rechercher les carnets d'adresses sur les comptes mails paramétrés. Si les services sont compatibles CardDav, CardBook chargera les contacts externes dans un carnet d'adresses.
Il faudra ensuite ouvrir l'écran CardBook par le menu « Outil » → « CardBook », puis cliquer sur le bouton droit de la souris depuis la partie gauche :
|
|
Il faudra ensuite choisir « nouveau carnet d'adresses », sélectionner « carnet d’adresses distant » puis renseigner l'URL et les identifiant/mot de passe via le protocole CardDAV.
|
|
|
|
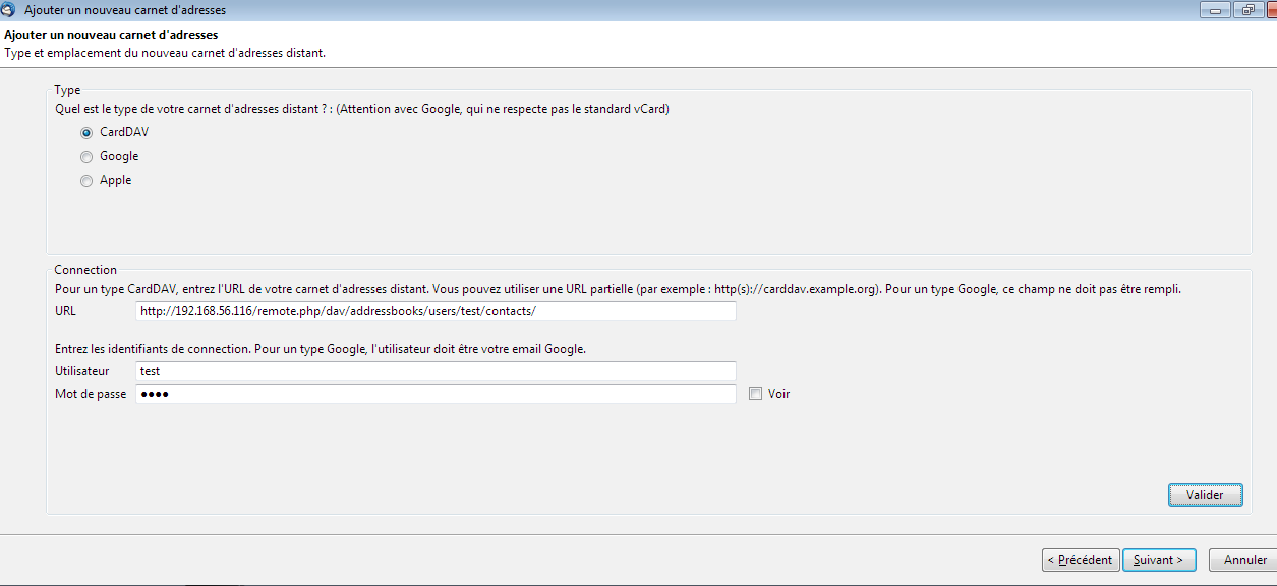
Le lien CardDAV est disponible dans les paramètres des contacts depuis l'interface web, comme vu au chapitre précédent.
Il vous faudra cliquer sur valider après avoir rempli les champs URL, identifiant et mot de passe pour pouvoir cliquer sur suivant. Vous pourrez changer les réglages de synchronisation depuis l’icône « Préférences », puis l'onglet « Synchronisation ».
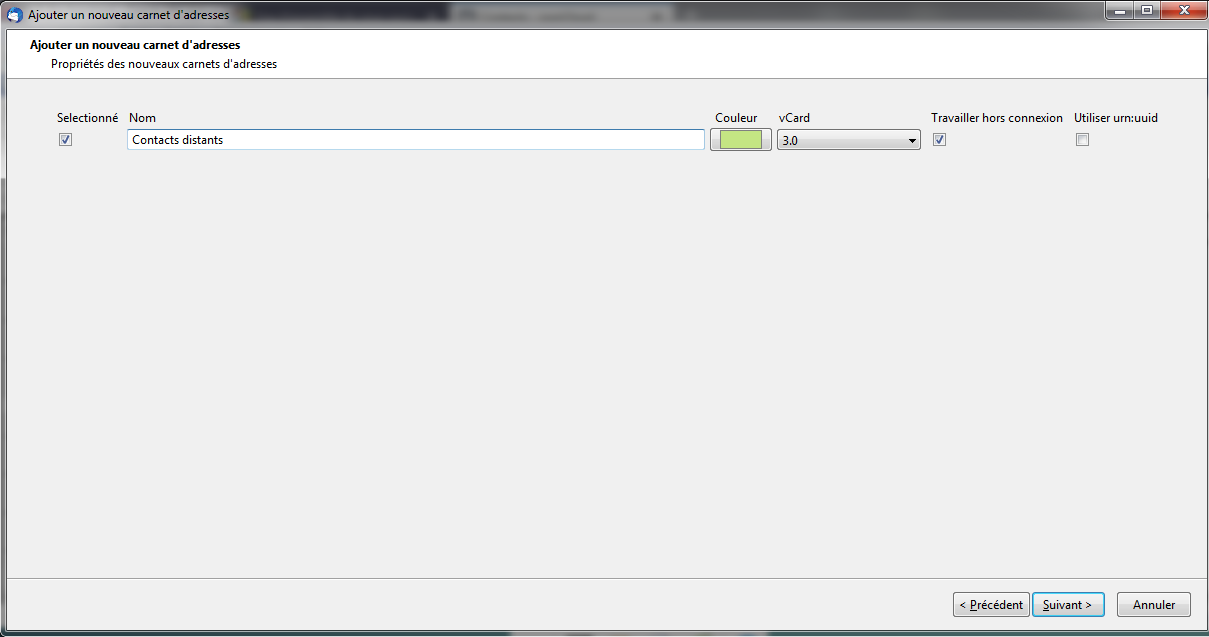
Vous pourrez ensuite nommer le carnet d’adresses et choisir sa couleur :
|
|
Le carnet d'adresses sera alors disponible et il sera possible de régler les préférences de synchronisation en cliquant sur « Préférences » :
|
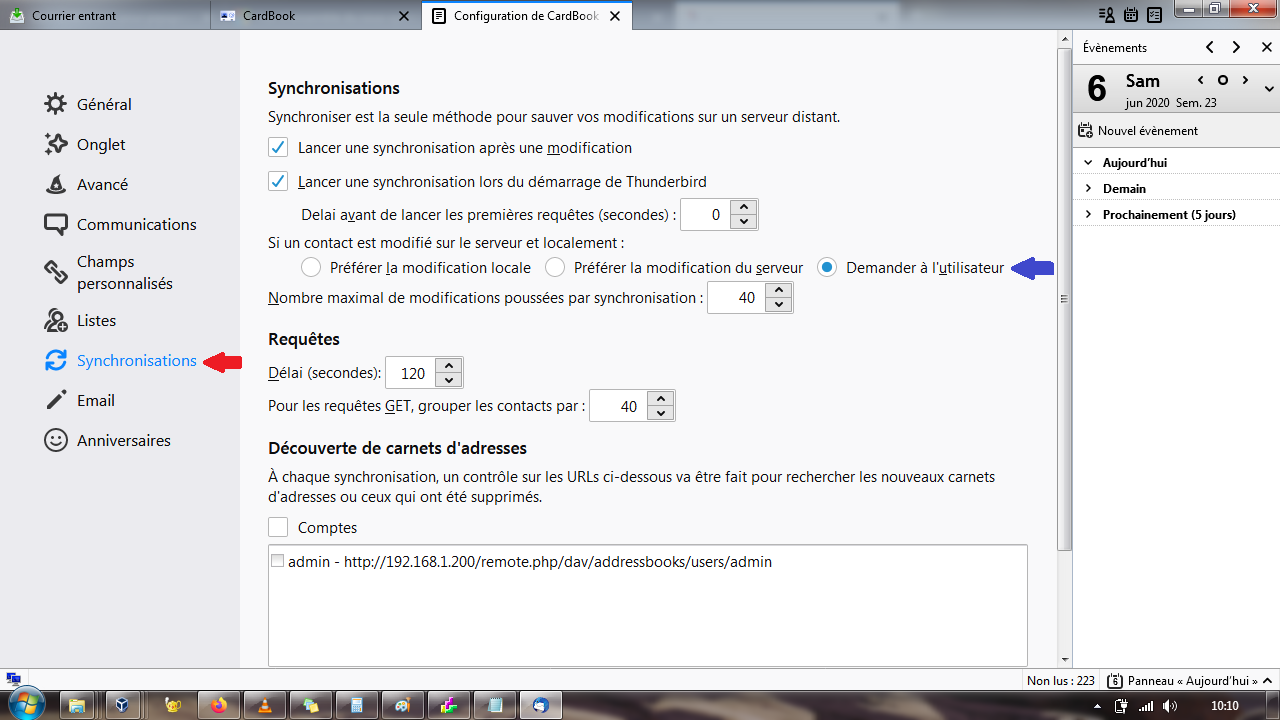
|
Pour les réglages de synchronisation :
|
|
4-2-14-2. Outlook▲
Pour Outlook, nous avons déjà ce qu'il faut : outlookcaldavdsynchronizer, vu au chapitre sur les calendriers. Il suffit de dupliquer le profil existant via l’icône ![]() depuis le gestionnaire de profils.
depuis le gestionnaire de profils.
Bien que son nom n'évoque que calDAV, l'application est bien compatible CardDAV.
Il faudra ensuite sélectionner le dossier Outlook pour sélectionner les contacts, et changer l'URL par le lien CardDAV.
4-2-14-3. Application Apple Contacts pour OS X et iOS▲
Le principe est le même que pour l’application Calendrier, il faut ajouter un compte CardDAV en prenant le lien :
http://192.168.56.121/remote.php/dav/addressbooks/users/test/contacts/
Adapter l'URL à votre situation.
4-2-15. Outils collaboratifs▲
4-2-15-1. OnlyOffice – modification de documents bureautique en ligne▲
OnlyOffice est une suite collaborative. Il existe une version communautaire, gratuite. ownCloud fournit un connecteur pour un serveur OnlyOffice. OnlyOffice devra être installé au préalable.
OnlyOffice n'a pas été testé dans le cadre de ce tutoriel.
Sur Nextcloud, un système OnlyOffice Community peut être installé, ceci n'a pas été testé dans le cadre de ce tutoriel.
4-2-15-2. Collabora▲
Collabora est un produit concurrent d'OnlyOffice. ownCloud et Nextcloud gèrent l'intégration d'un serveur Collabora.
4-2-16. Utilisation avec un cluster de bases de données▲
Dans le cadre de l'utilisation d'un cluster de bases de données (MariaDB dans notre cas), vous aurez le message d'erreur suivant :
|
|
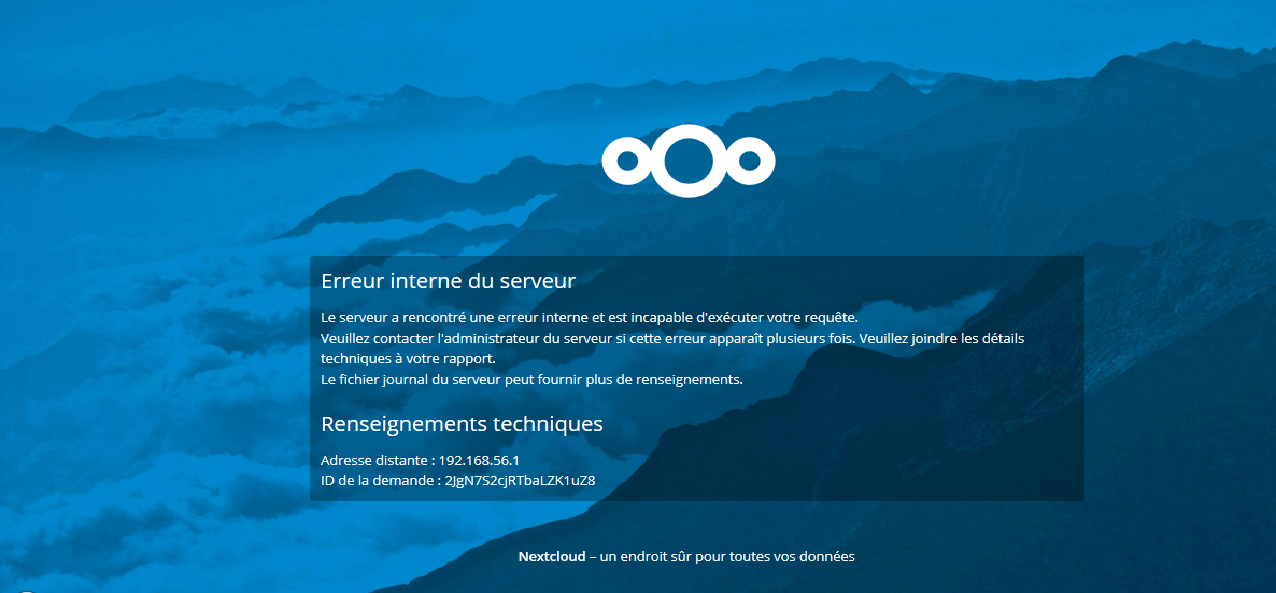
Ceci pourra être corrigé en changeant le format des journaux binaires dans les fichiers de configuration :
binlog_format = MIXEDIl faudra redémarrer le serveur SQL.
4-2-17. Panne serveur▲
En cas de perte totale du serveur, si celui-ci n'a pas de redondance et se retrouve vide, lors de la reconnexion du poste client, celui-ci vous affichera l'avertissement suivant :
|
|
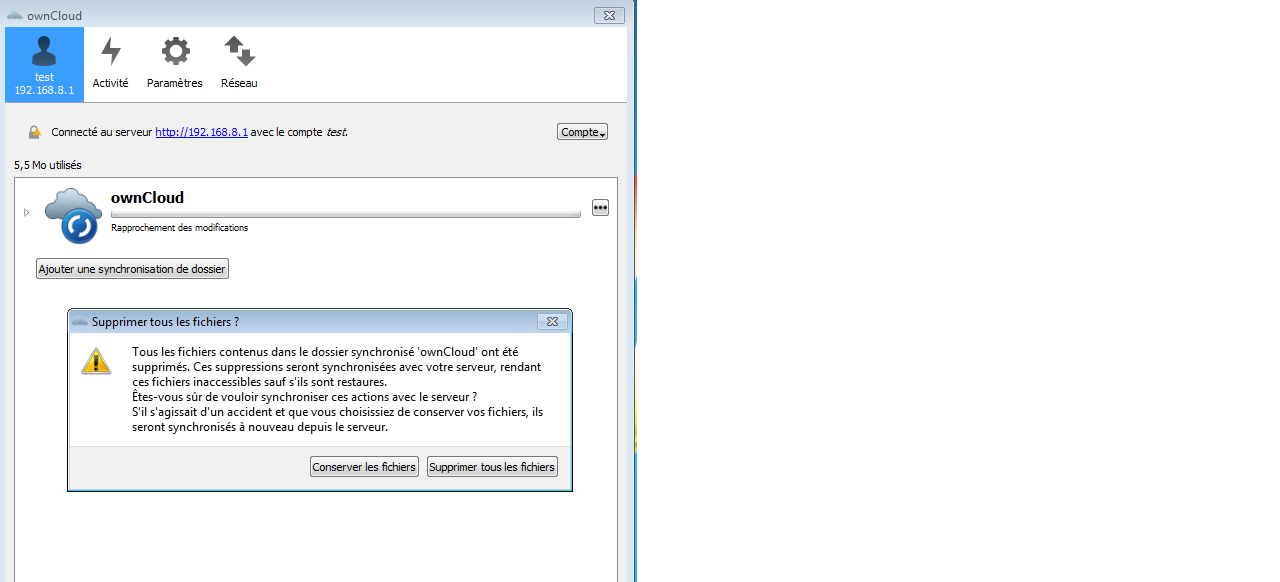
Le client ownCloud détecte que le compte distant est vide et vous propose soit de conserver le contenu du dossier de synchronisation, soit d'effacer le contenu. Si vous choisissez « conserver », ceux-ci seront resynchronisés sur le serveur, si vous choisissez « supprimer », les fichiers locaux seront supprimés. Les dossiers locaux et distants seront alors synchrones.
Pour l'agenda Outlook, le clic sur l’icône ![]() « clear cache of selected profile » des profils CalDAV Synchronizer a permis de refaire une synchronisation.
« clear cache of selected profile » des profils CalDAV Synchronizer a permis de refaire une synchronisation.
Pour Thunderbird, si la synchronisation après réinstallation pose problème, il suffira de supprimer l'agenda en faisant un clic droit → se désabonner de l'agenda. Il vous faudra d'abord le sauvegarder en faisant un clic droit → exporter. Une fois le compte recréé, pour importer la sauvegarde, il faudra aller dans le menu « événement et tâches » plutôt que par un clic droit de la souris. Thunderbird vous demandera dans quel agenda importer les éléments. Ceci ne sera pas nécessaire si une sauvegarde de la base ownCloud a été remontée.
Pour Calendrier Apple, le test n'a pas été fait, mais le principe est le même. Il faudra exporter le calendrier en format .ics (sélectionner « Exporter », pas archiver : une archive restaurée écrase le contenu déjà présent) pour le réimporter ci-besoin.
4-2-18. Utilisation en ligne de commande▲
ownCloud est fourni avec un outil en ligne de commande pouvant être appelé via php occ <option> depuis le dossier contenant l'installation ownCloud. occ est également présent dans Nextcloud.
4-2-19. Redondance d’une instance Nextcloud▲
Prérequis
Pour avoir une redondance d'une instance ownCloud, le dossier contenant les données devra être stocké dans un système de fichiers distribué. La base de données devra faire partie d'un cluster de bases de données.
Pour gérer cet aspect, je vous invite à consulter le paragraphe sur la création d'un cloud personnelÉtude de création de notre propre cloud.
Il est nécessaire de copier les fichiers PHP de Nextcloud depuis srv1 vers srv2 via scp.
Ensuite, il est nécessaire d’installer les dépendances de Nextcloud : php7-curl, memcached, php7-memcached.
La première connexion sur le nouveau serveur donne le message suivant :
|
|
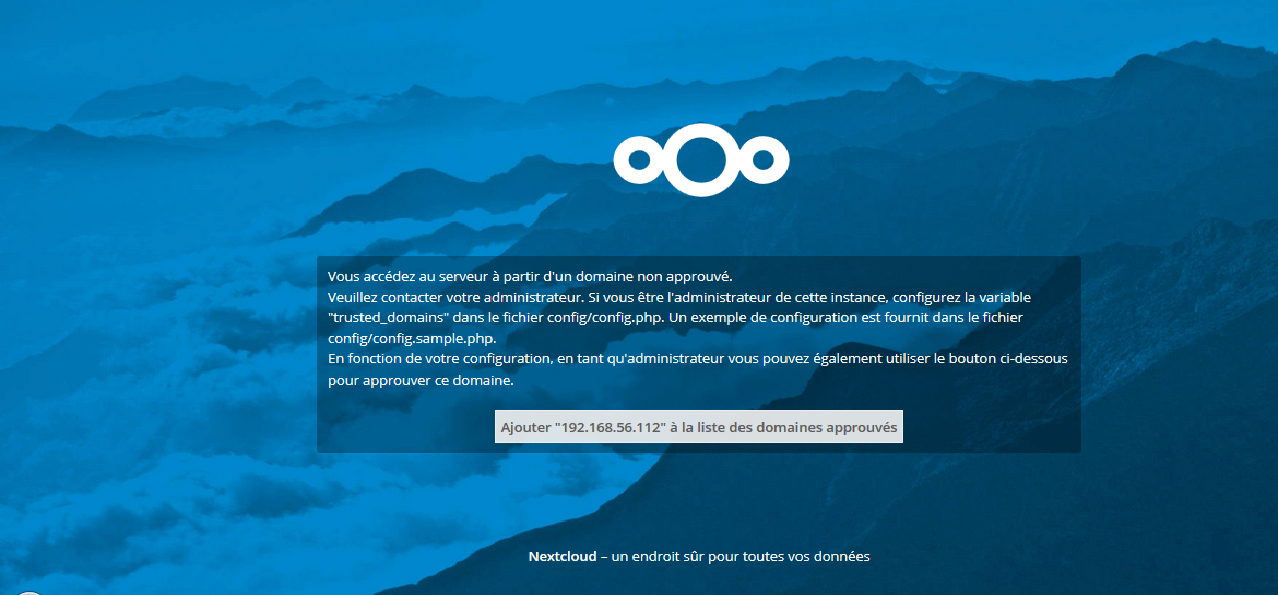
Suite au clic :
|
|
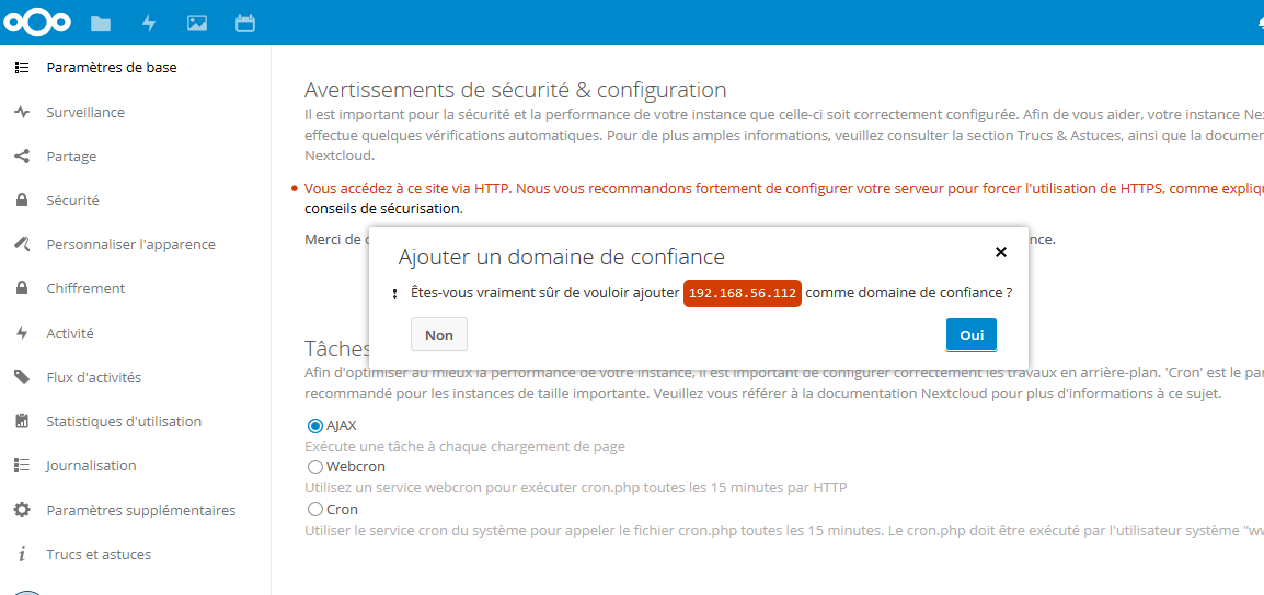
Ceci va rajouter une entrée dans le tableau trusted_domains de config/config.php de srv1.
Il nous faut donc recopier ce fichier modifié dans srv2.
Vous pourrez ensuite utiliser un système de load balancingRépartition de charge.
4-3. YunoHost - L'autohébergement▲
YunoHost est une distribution incluant des logiciels packagés et ayant pour but de faciliter l'autohébergement. La distribution intègre un serveur LDAP qui sera utilisé par toutes les applications packagées pour leur authentification (via authentification unique utilisant SSO). Il intègre également un serveur mail (PostFix/Dovecot/rspamd).
Yunohost permet la gestion de plusieurs domaines.
4-3-1. Installation sur machine vierge▲
Yunohost est fourni sous forme de DVD d’installation, basée actuellement sur Debian Buster (YunoHost version 4.0.3). Il s'agit d'un DVD d’installation qui a été personnalisé. Vous retrouverez donc les mêmes écrans qu'avec un DVD d'installation standard, mais vous ne pourrez faire aucune sélection mise à part la langue (exemple : pas d'accès au partitionnement du disque, pas de choix des paquets).
Yunohost fournit une ISO 64 bits, 32 bits, et des ISO pour Raspberry Pi ainsi que pour Orange Pi. Yunohost fournit également une image de machine virtuelle au format Virtualbox.
Il vous sera également possible de l'installer sur un système existant.
Commençons par voir la version CD :
|
|
Une fois la langue et le clavier sélectionnés, l'installation est automatique.
Vous ne pourrez pas intervenir sur le partitionnement du disque. Par ailleurs, le « expert install » retourne l'erreur :
« Le fichier prérequis nécessaire à la configuration n'a pas pu être téléchargé à l'adresse file://cdrom/simple-cd/advanced.preseeed ».
Si la machine contient des données, YunoHost effacera celles-ci sans demander de confirmation.
Au redémarrage après l'installation, vous aurez l'écran de postinstallation suivant :
|
|
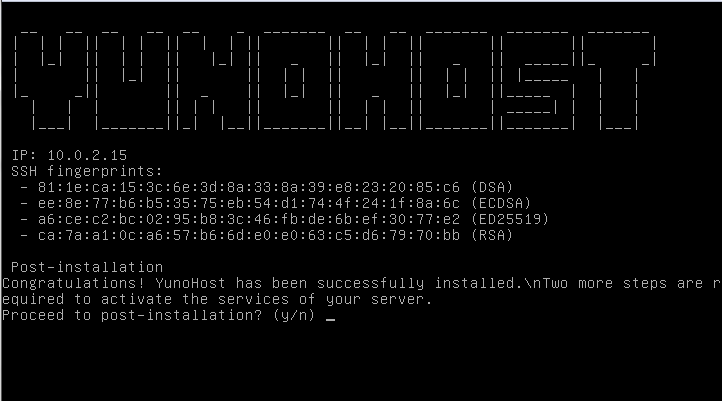
Nous répondrons bien entendu par « yes ».
Nous sera alors demandé le domaine principal.
Domaine principal :
Mot de passe :Des messages de notifications seront affichés dans la console indiquant la configuration des différents services. La machine sera prête quand vous aurez le message :
Succès ! Yunohost a été configuréIl nous restera à régler l'adresse IP. Pour cela, il faudra ouvrir une session avec le login « admin » et le mot de passe communiqué précédemment (admin est un compte sudoer). Nous pourrons ensuite fixer l'adresse dans le fichier /etc/network/interfaces.
La suite de la configuration se passera depuis le navigateur web. À la première connexion, vous aurez une alerte du navigateur « votre connexion n'est pas privée », le certificat étant autosigné. Il vous sera possible de paramétrer vos certificats ultérieurement. YunoHost intègre la génération d'un certificat Lets'Encrypt et vous pourrez intégrer vos propres certificats émis depuis une autorité de certification si vous en possédez.
4-3-2. Installation sur système existant▲
Une version Debian Stretch sera requise.
Nous commençons par récupérer le fichier de dépôt :
wget https://install.yunohost.org -–no-check-certificateCeci va télécharger un fichier index.html suivi de :
bash < index.htmlLe script échouera si Apache est installé, notifiant dans les journaux que celui-ci peut entrer en conflit avec nginx, serveur web utilisé par Yunohost.
Yunohost va alors installer les paquets dont il a besoin :
|
|
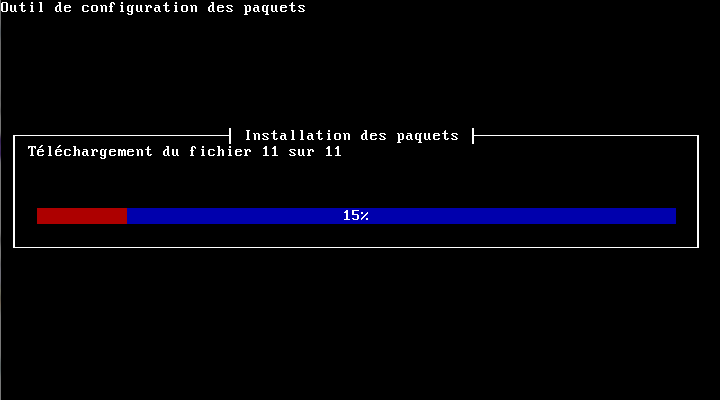
Vous aurez ensuite une demande de confirmation concernant l'écrasement de fichiers de configuration, au cas où des configurations sont présentes pour les services indiqués :
|
|
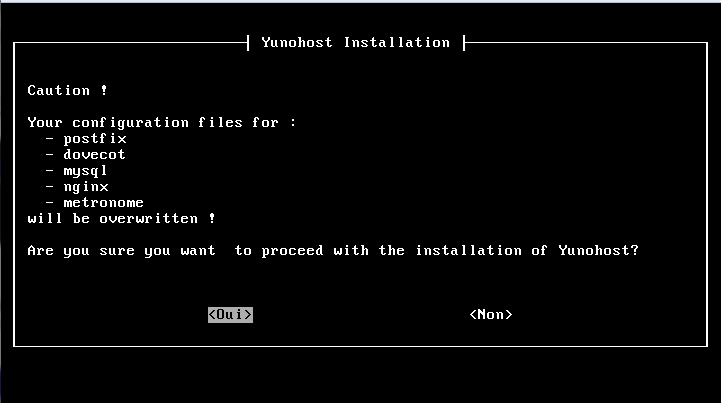
Une fois l'installation des paquets terminée, il vous sera demandé de faire la postinstallation :
J'ai lancé la postinstallation depuis la ligne de commande :
yunohost tools postinstallL'installation s'est ensuite finalisée, après avoir entré le nom de domaine et le mot de passe tout comme pour l’installation depuis l'ISO.
La version ISO utilise automatiquement LVM, il sera à votre charge de le faire de façon à pouvoir facilement augmenter l'espace de stockage, voire utiliser un volume réparti pour monter les données Yunohost.
4-3-3. Prise en main▲
La première connexion devra se faire sur l'URL https://votre_ip/admin :
|
|
Une fois le mot de passe saisi, vous aurez l'écran suivant :
|
|
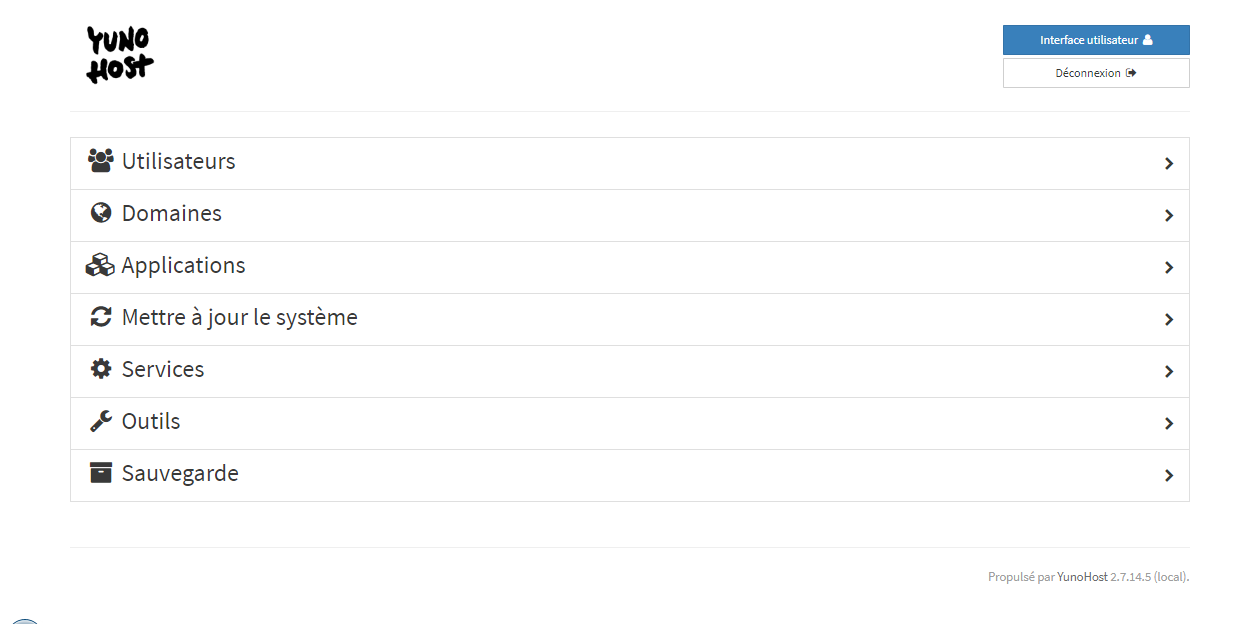
Pour gérer le certificat, il faudra aller dans le menu « Domaines », sélectionner le domaine présent, puis gérer les certificats :
|
|
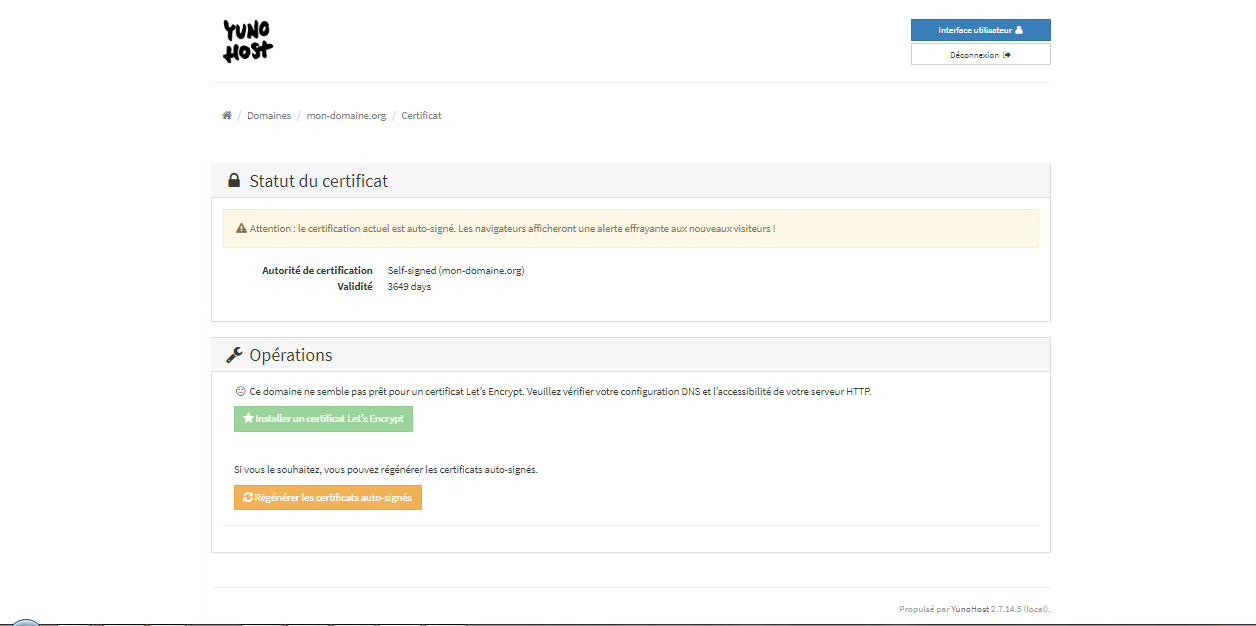
Vous pourrez créer gratuitement un certificat Let's Encrypt. Si vous avez déjà vos propres certificats, il vous faudra les installer à la main depuis le terminal, l'interface graphique ne proposant que la génération d'un certificat autosigné ou let's Encrypt.
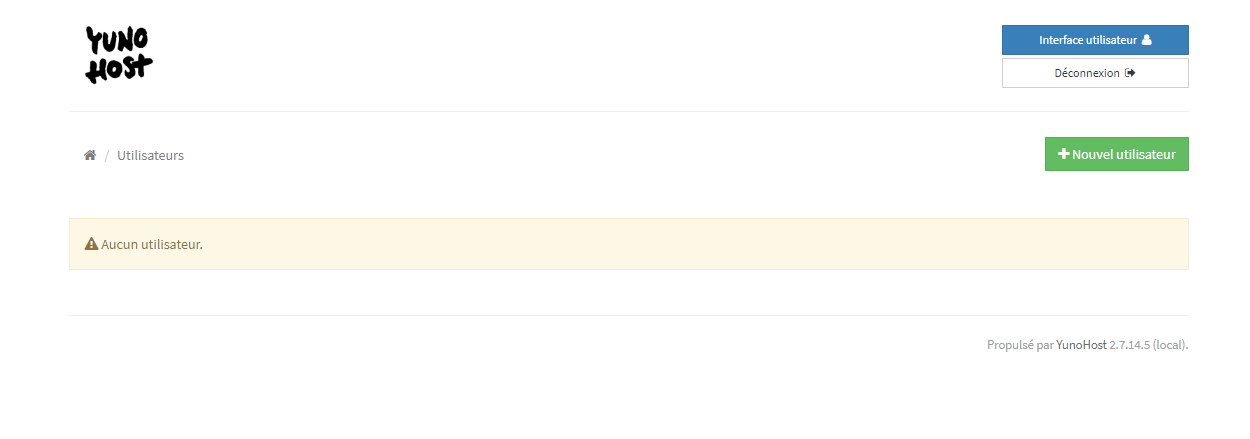
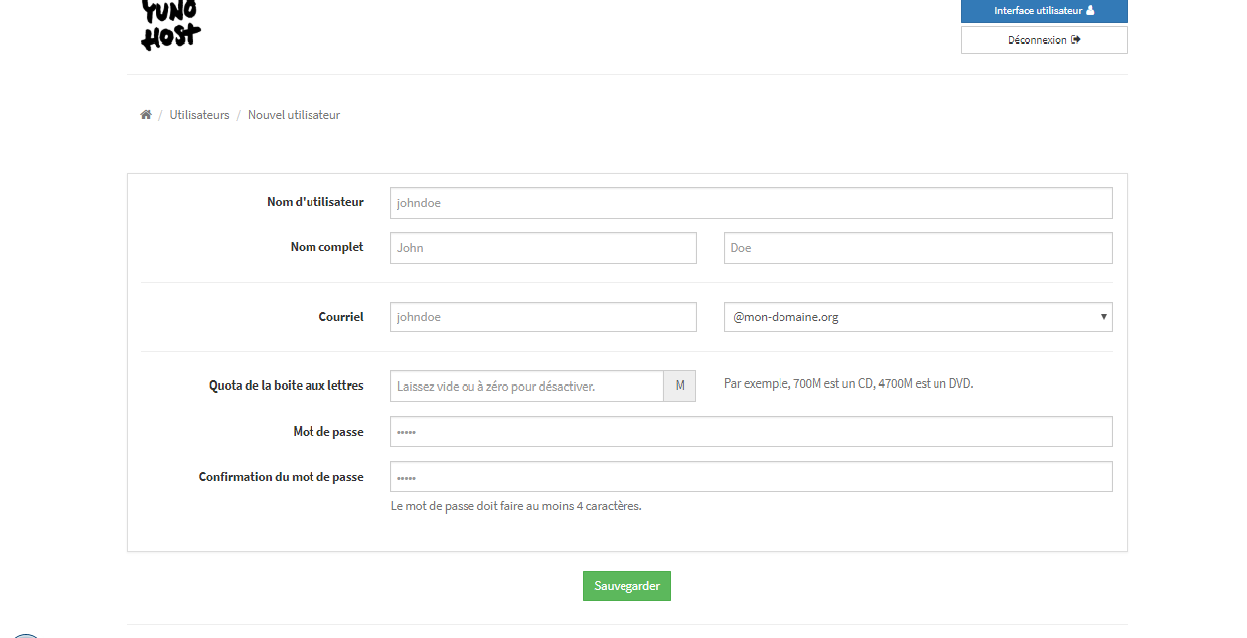
La prochaine étape sera de créer un utilisateur :
|
|
|
|
À ce stade, vous pourrez accéder à l'interface utilisateur, interface par défaut lors de l'accès :
|
|
Voici l'interface de connexion pour un utilisateur standard :
|
|
À la connexion, vous aurez un écran comme ci-dessous. Vous pouvez retourner à l'interface d'administration en cliquant sur le lien « Administration » :
|
|
Il n'y a pas beaucoup d'options actuellement au niveau de la connexion utilisateur, aucune application n'étant installée. Nous allons maintenant installer les applications que nous souhaitons utiliser.
Allons voir ce qui est disponible dans Applications (depuis l'interface d’administration) :
|
|
|
|
En cliquant sur « Installer », vous aurez une sélection d'applications par type :
|
|
Si nous cliquons par exemple sur synchronisation, nous pouvons voir qu'il est possible d'effectuer un filtrage supplémentaire (fichiers, calendriers, contacts, mots de passe, autres) :
|
|
Voici les principales applications (liste non exhaustive) :
- synchronisation de fichiers : Nextcloud, Seafile, Syncthing (pour ceux que nous verrons ultérieurement) ;
- synchronisation d'agenda : AgenDAV, Nextcloud ;
- synchronisation de contacts : Baikal (CardDAV, CalDAV), Nextcloud ;
- gestionnaires de mots de passe : bitwarden, keeweb ;
- gestionnaire de favoris : Firefox sync server ;
- CMS : Drupal, SPIP, WordPress ;
- Wiki : MediaWiki, dokuwiki ;
- Messagerie : Horde, Roundcube (YunoHost intégrant un serveur mail) ;
- CRM/ERP : Dolibarr ;
- phpMyadmin : le fameux gestionnaire de bases de données MySQL.
4-3-4. Installation d'application▲
4-3-4-1. Exemple d'installation de Nextcloud▲
Nous commençons par installer Nextcloud.
En sélectionnant Nextcloud, vous aurez l'écran suivant :
|
|
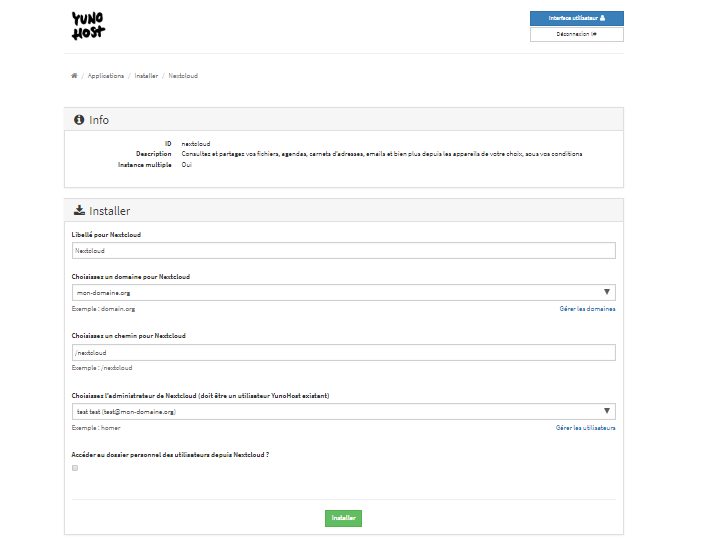
Vous pourrez choisir :
- le libellé de l'application tel qu'il apparaîtra dans Nextcloud ;
- le nom de domaine ;
- le chemin/l'url ;
- le compte administrateur Nextcloud : à sélectionner dans la liste des comptes existants (seul celui-ci pourra installer les applets Nextcloud) ;
- une case à cocher « Accéder au dossier personnel des utilisateurs depuis Nextcloud ».
Les réglages par défaut conviendront très bien. Je vous conseille la création d'un compte spécifique pour l'administration de Nextcloud. N'oubliez pas de cocher la case si vous souhaitez que Nextcloud accède aux données hors Nextcloud.
La version Nextcloud fournie est la version 18 (la version 19 est disponible au moment de la réalisation de ce tutoriel).
Une fois « Installer » cliqué, vous verrez la sortie de l’application un « pacman » défilant comme une barre de progression et représentant le traitement en cours. Vous pouvez voir en haut les commandes exécutées :
|
|
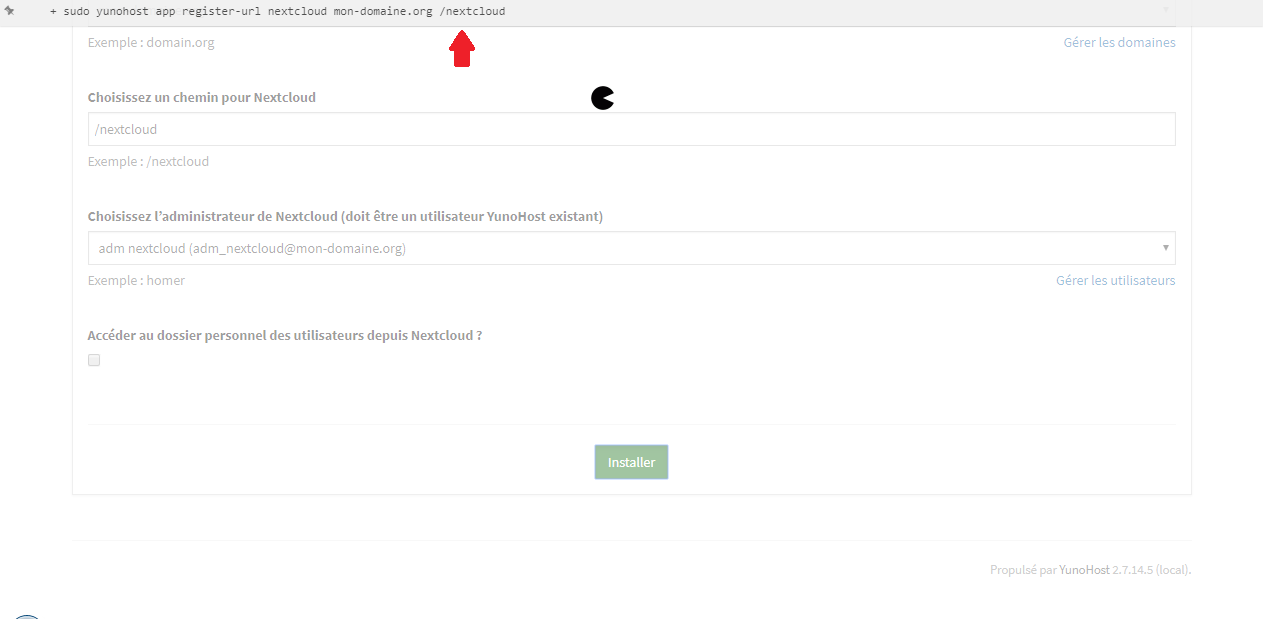
Si vous cliquez sur la barre, vous pourrez voir le détail :
|
|
Une fois l'installation effectuée, tous les utilisateurs auront accès par défaut à l'application. Si vous souhaitez filtrer l'accès, il faudra cliquer sur l'application et sélectionner les utilisateurs autorisés en cliquant sur « Accès » :
|
|
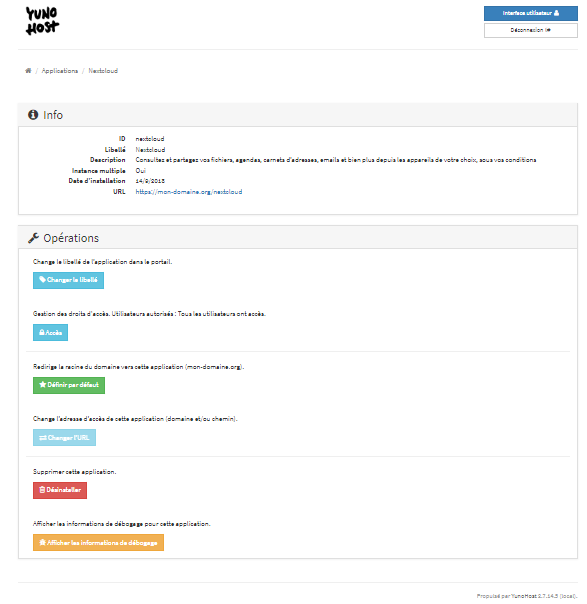
|
|
Depuis l'interface utilisateur, vous aurez ensuite accès à l'application :
|
|
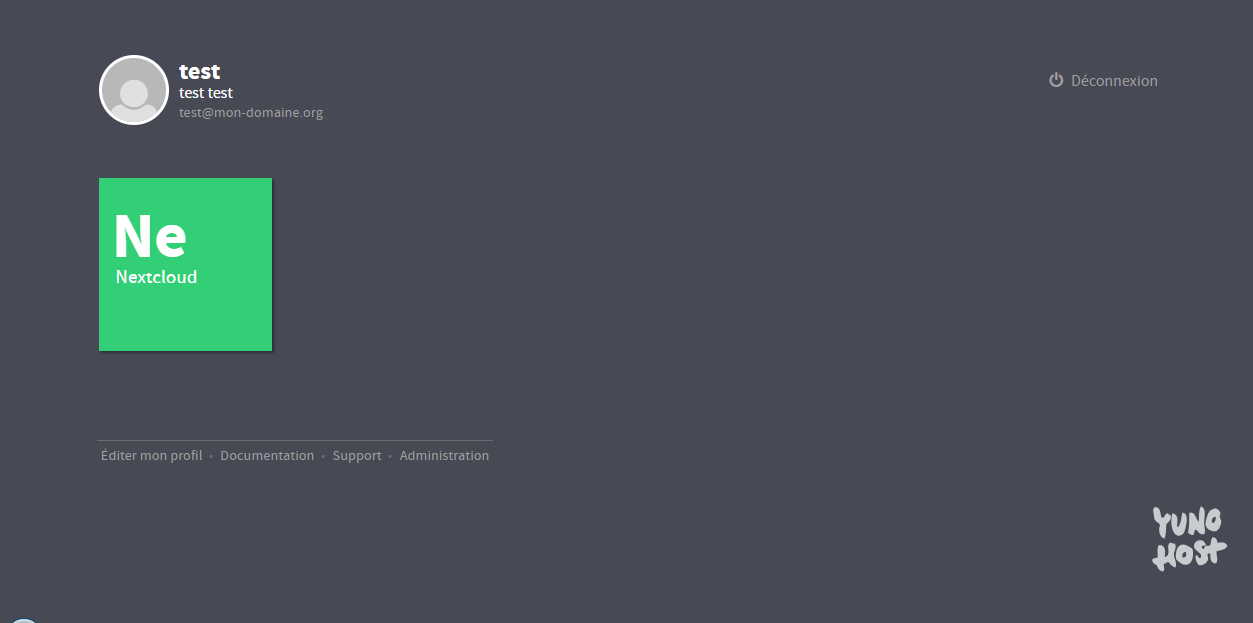
En cliquant sur l’icône, vous aurez accès à Nextcloud directement sans devoir vous identifier. Je vous invite à revenir au paragraphe précédent pour de plus amples informations sur Nextcloud. Pour ce qui est de la gestion du calendrier (et des contacts via le protocole CardDAV), vous pourrez installer les modules de Nextcloud (choix que je privilégierais), ou utiliser d'autres applications fournies par Yunohost comme Baikal (serveur CalDAV/CardDAV)/agenDAV).
Option bien pratique : il est possible de revenir au menu des applications en cliquant sur l’icône « Yuno Host » qui vient s'afficher en bas à droite des écrans des applications. Cette fonction n'est pas accessible pour toutes les applications.
|
|
Se déconnecter de Nextcloud depuis le menu en haut à droite vous déconnectera de Yunohost et vous renverra vers l'écran de connexion de celui-ci.
Les données de Nextcloud seront stockées dans /home/yunohost.app/nextcloud/data. Et ensuite un dossier pour chaque utilisateur.
Le site web Nextcloud va lui se trouver dans /var/www/nextcloud.
Pour mettre à jour vers une version plus récente, il vous faudra activer l'applet « update notification » que vous trouverez dans (1) Applications → (2) Applications désactivées.
|
|
Après déconnexion et reconnexion, en allant dans le menu « Paramètres » → « administration » → « vue d'ensemble », vous pourrez effectuer une mise à jour :
|
|
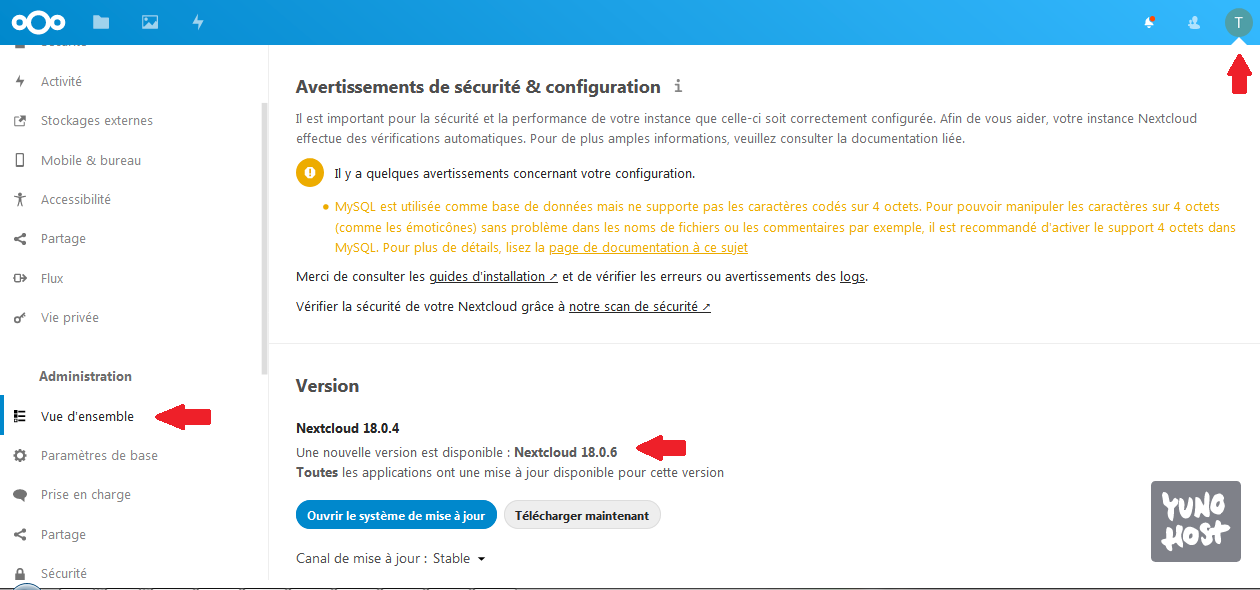
Nous pouvons voir que nous sommes en version 18 et que la version proposée est la version 18.0.4.
Cliquer sur « ouvrir le système de mise à jour » va afficher l'écran suivant :
|
|

La procédure se déclenchera via l'appui sur « Start Update ».
Une fois les opérations effectuées, Nextcloud va vous proposer de laisser ou non le mode maintenance actif. Comme nous ne souhaitons pas utiliser le mode en ligne de commande, nous choisissons « no » :
|
|
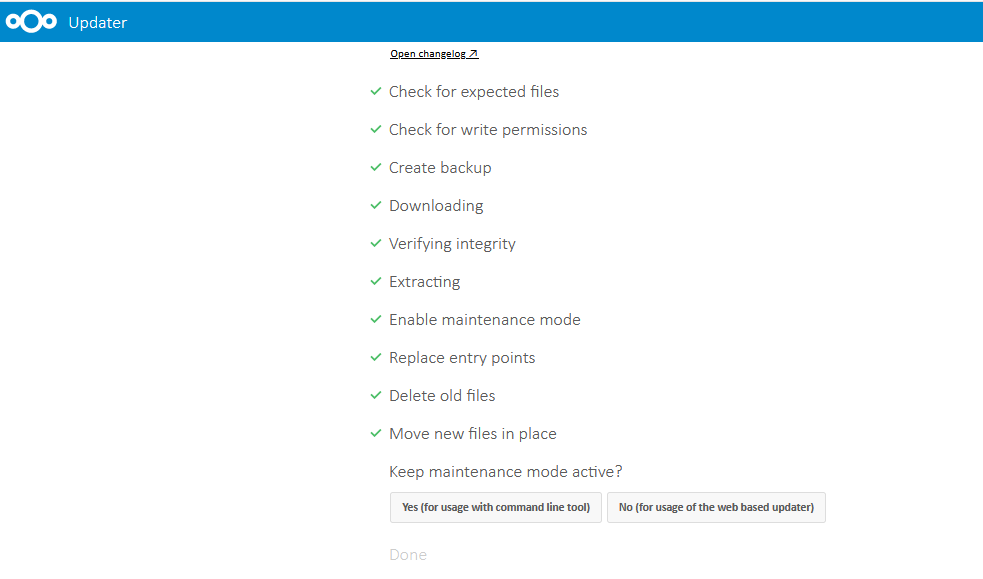
Il faudra ensuite cliquer sur « go back to your nextcloud instance… », qui vous affichera l'étape suivante :
|
|
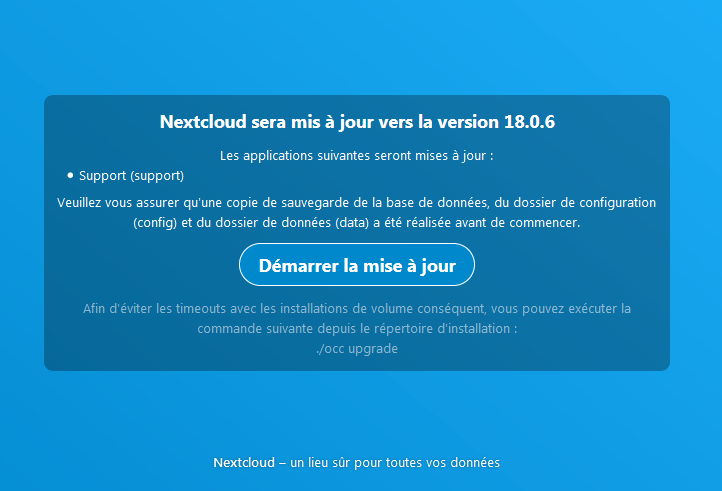
Une fois l'opération effectuée, vous serez automatiquement redirigé vers l'interface de Nextcloud.
En modifiant le canal de mise à jour de Stable à Beta, j'ai pu avoir accès à la version 19.0.0.
Le fait de changer de version majeure peut vous exposer à la disparition de certaines applets dépréciées ou remplacées.
4-3-4-2. Roundcube▲
Roundcube est un webmail répandu écrit en PHP. L'installation se déroule de la même façon, la seule différence étant la case à cocher concernant le plugin de synchronisation CardDAV.
Votre nom et adresse mail vous sera demandé lors du premier démarrage (mauvaise configuration de mon serveur de test ?) :
|
|
Les carnets d'adresses ne reprennent pas automatiquement les contacts YunoHost. Il semble que la configuration prévoit par défaut l'utilisation de l'application Baikal. Il devrait être possible de lier Roundcube aux contacts Netxcloud via l'ajout d'un carnet d'adresses CardDAV,
4-3-4-3. WordPress▲
L'installation s’effectuera de la même façon. Les options spécifiques que vous pourrez choisir :
- l'utilisateur YunoHost administrateur du site ;
- la langue ;
- option multisite (décoché par défaut) ;
- option site public (coché par défaut – ne pas confondre avec les droits WordPress).
L'accès se présentera comme ceci :
|
|

L'administration se fera par défaut via [URL du wordpress]/wp-admin comme pour tout site WordPress.
À la connexion au WordPress, j'ai pu constater que la version actuelle était 5.4.
La mise à jour de WordPress, des extensions et des thèmes n'a posé aucun problème. L'installation de plugins additionnels ne posant pas non plus de problème.
Le site Wordpress sera stocké dans /var/www/wordpress.
4-3-4-4. phpMyAdmin▲
Il vous faudra choisir le seul utilisateur autorisé à se connecter (vu comme administrateur phpMyAdmin). L’icône d'accès ne sera logiquement ajoutée que dans celui-ci, le clic dessus lancera l'interface sans demande d'authentification (authentification SSO - Single Sign-On). Taper l'URL d'accès à phpMyAdmin depuis un autre compte n'aura aucun effet.
Depuis l'interface phpMyAdmin, il n'est pas possible de sortir de celle-ci.
4-3-5. Sauvegarde/restauration▲
YunoHost intègre un mécanisme de sauvegarde.
4-3-5-1. Sauvegarde▲
Pour effectuer une sauvegarde, il faudra aller dans le menu idoine :
|
|
|
|
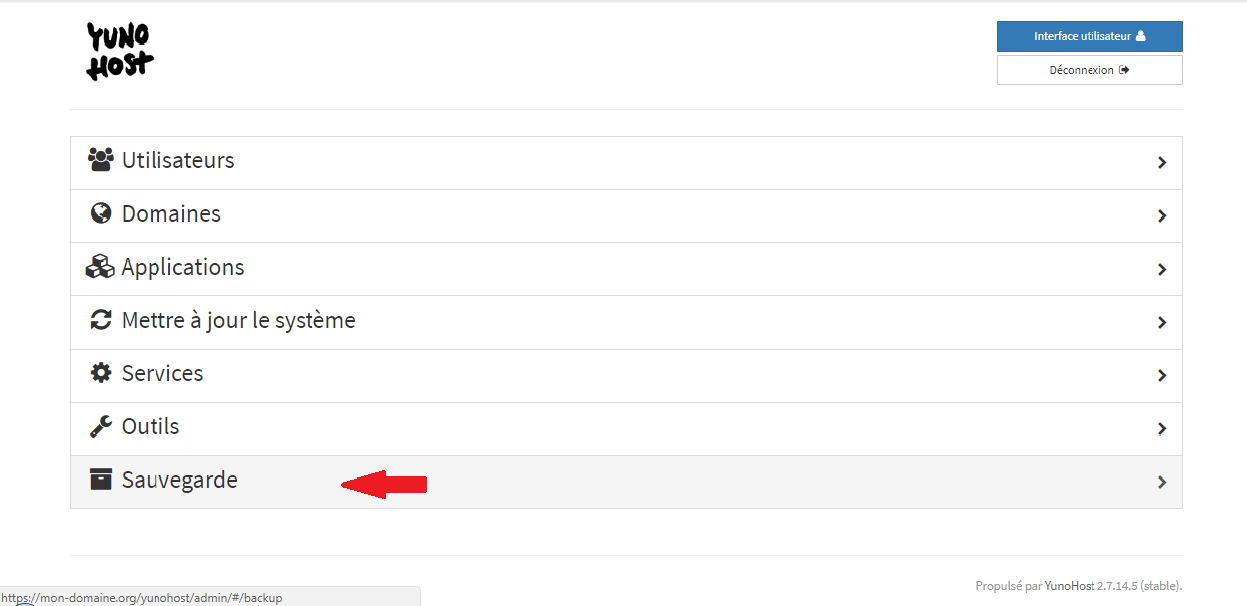

Vous pouvez voir que les sauvegardes sont stockées dans /home/yunohost.backup. Si vous souhaitez effectuer une sauvegarde à un autre endroit, il vous suffit de faire un point de montage de votre volume sur cette destination.
Nous lançons la sauvegarde :
|
|
Dans l'écran suivant, vous pourrez choisir ce que vous voulez sauvegarder :
- les données système ;
- la configuration ;
- les mails ;
- les données utilisateurs (dossier home) ;
-
les applications, dans notre exemple :
- Nextcloud,
- phpMyAdmin,
- roundcube,
- WordPress.
Vous obtiendrez alors une sauvegarde sous forme d'archive .tar.gz accompagnée d'un fichier d'information .json :
|
|
Le nom du fichier correspondant à la date de celle-ci encodée, stockée dans /home/yunohost.backup/archives.
En explorant l'archive, nous retrouvons les données de Nextcloud (chemin apps/nextcloud/backup/home/yunohost.app/nextcloud/data/*), le site WordPress (apps/wordpress/backup/var/www/wordpress/*), les mails (data/home/vmail/*). Nous voyons aussi des fichiers db.sql dans les dossiers d'applications correspondant aux dumps des bases de données les concernant.
4-3-5-2. Restauration▲
J'ai simulé une panne en réinstallant un serveur de zéro.
Une fois celui-ci réinstallé, il faut uploader la sauvegarde dans le dossier /home/yunohost.backup/archives.
Il m'a fallu créer le dossier archives dans /home/yunohost.backup. Celui-ci n'est créé que lors de la première sauvegarde.
Une fois la sauvegarde copiée, celle-ci apparaîtra dans le menu sauvegardes de YunoHost :
|
|
Cliquer dessus permettra de voir le détail :
|
|
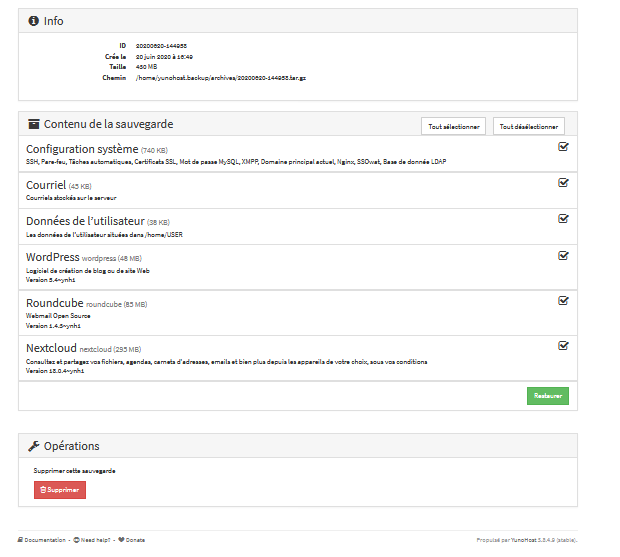
Il suffira de cliquer « restaurer ». Comme vous pouvez le voir, celle-ci peut être partielle.
Vous aurez une demande de confirmation :
|
|
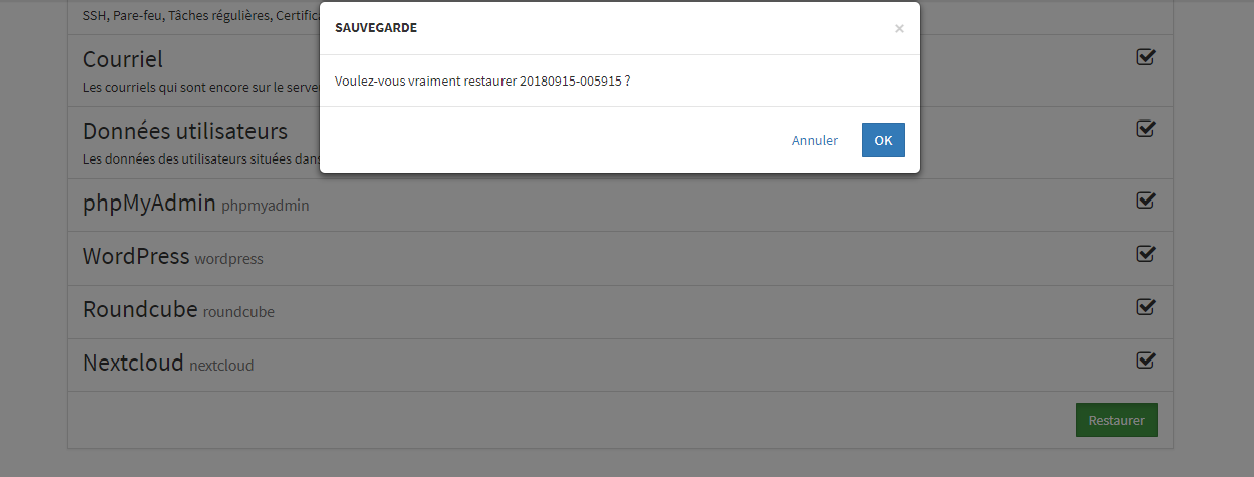
Les applications seront installées si elles sont absentes.
4-3-5-3. Automatiser les sauvegardes▲
Pour automatiser les sauvegardes, il vous faudra utiliser la commande suivante depuis le terminal :
yunohost backup createCette commande va effectuer une sauvegarde complète. Il vous suffira de la lancer depuis un cron.
Si vous ne souhaitez sauvegarder qu'une application de façon à morceler les sauvegardes :
yunohost backup create --apps <nom de l'application>Vous trouverez plus d'informations ici.
Pensez à faire des sauvegardes offline.
Pour les applications pouvant stocker beaucoup de données telles que Nextcloud, vous pouvez envisager d'utiliser un système de synchronisation comme rsync pour faire des sauvegardes incrémentales, en dehors du système de sauvegarde de Yunohost. Il est à noter que si vos utilisateurs utilisent le client Desktop pour synchroniser les données de leurs postes, celles-ci s'y trouvent. Mais je ne conseillerais pas de ne vous appuyer que sur cela pour les sauvegardes.
4-3-6. Mises à jour▲
Le lancement de « Mises à jour » sera l'équivalent de la commande :
apt-get upgradeAvant de mettre à jour les paquets, vous aurez leur liste.
Yunohost vous proposera aussi une mise à jour de Yunohost si présente, ainsi que des applications Yunohost installées. Pour cela, il faudra vous rendre dans le menu « outils » → « migrations » :
|
|
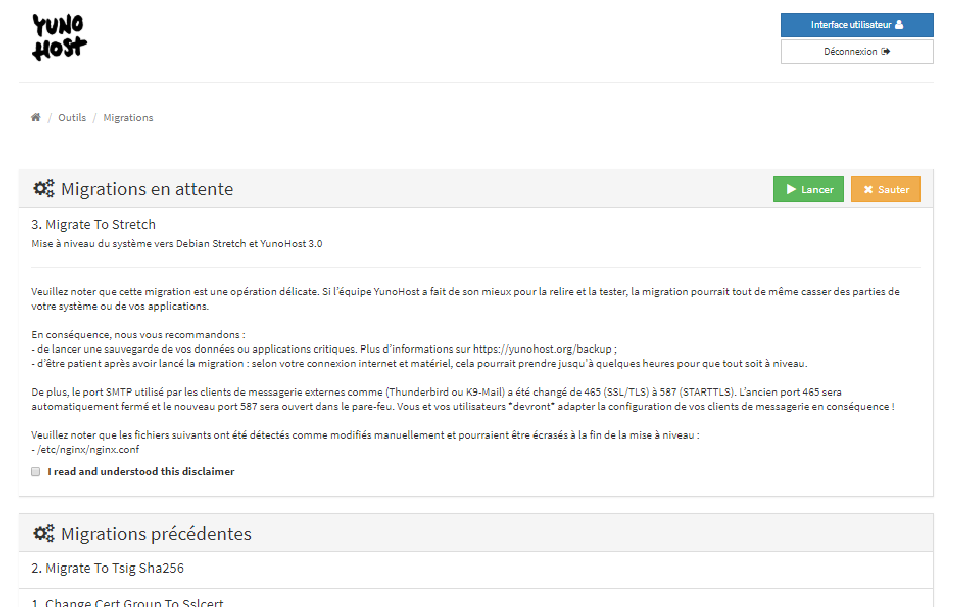
Vous voyez ci-dessus un écran correspondant à une ancienne version demandant une mise à jour vers Debian Stretch.
4-3-7. Bilan▲
Yunohost est une solution fournissant toutes les applications nécessaires à la création de son propre Cloud.
Dans le cadre de multiservices à héberger sur plusieurs machines avec tolérance de panne, l'utilisation manuelle des briques évoquées dans la partie création de notre propre cloud sera plus judicieux. Il reste possible de stocker les données dans un système de fichiers distribué, dans une base de données sur plusieurs machines.
5. Étude de création de notre propre cloud▲
Nous allons ici étudier la mise en place de notre propre cloud. Ce service pourra servir à titre personnel ou à titre professionnel.
Notre cloud proposera les services suivants :
- la synchronisation/partage de documents ;
- la synchronisation de contacts et calendriers ;
- un serveur mail.
Ces services seront fournis soit par un seul produit, soit par une agrégation de produits. Le système pourra être réparti et redondant (voir les chapitres sur la répartition de charge et la haute disponibilitéSystèmes de fichiers distribués).
Par contre, nous ne verrons pas spécifiquement l'utilisation du cloud pour stocker une application métier, dans ce document. Tout ce qui est vu ici sera applicable pour une application métier.
Aussi, il est possible d’ajouter des clients lourds ou des applications accessibles à travers un site web et se connectant à un serveur proposant une base de données :
- des Content Management System (CMS) ou système de gestion de contenu tel que WordPress, Joomla ;
- des Customer Relationship Management (CRM) ou Enterprise Resource Planning (ERP), systèmes de gestion de clients tels que SugarCRM, Oddo (anciennement OpenERP) ;
- des boutiques en ligne comme Prestashop ;
- des systèmes de Gestion Électronique de Documents (GED) comme SeedDMS.
Des solutions en mode web seront plus faciles d'utilisation en cloud qu'un client lourd, mais rien n'empêche l'utilisation d'un client lourd tant que l’infrastructure le prévoit.
6. Les briques minimales▲
Pour réaliser notre cloud, il nous faudra :
- un système de fichiers (filesystem) répartis et/ou distribué (chapitre 8Systèmes de fichiers distribués) ;
- un système de centralisation de la gestion des accès (login/mots de passe), compatible avec tous les services utilisés, et répliqué (chapitre 9Centralisation de la gestion des accès) ;
- des bases de données répliquées (chapitre 10Réplication/clustering de bases de données) ;
- un système de répartition de charges / tolérance de panne (chapitre 11Répartition de charge).
À ce stade, nous aurons notre plateforme IaaS/PaaS sur laquelle nous pourrons ajouter les logiciels permettant d'avoir notre plateforme SaaS.
Tous ces services pourraient être gérés sur une seule machine, votre propre matériel stocké dans le centre de données d'un hébergeur, sur une machine louée chez celui-ci, ou même en ligne dans vos locaux. Dans ce dernier cas, il ne s'agira pas de cloud.
Toutes les briques peuvent être stockées sur une seule machine, mais cela n'aura pas de sens en termes de cloud, car le but du cloud est de répartir la charge, ne pas avoir de points de défaillance, et pouvoir facilement modifier augmenter/diminuer les ressources.
Sur ces briques, nous utiliserons des services de :
- partage de fichiers ;
- gestion d'agenda et de contacts.
6-1. Le cloud et la virtualisation▲
Il faut voir le cloud comme un accès à de la ressource et non à du matériel. Bien qu'il soit possible d'avoir un cloud ou de monter un cloud avec votre propre matériel dans une baie d’un centre de données, ou même chez vous, il est beaucoup plus simple d'avoir de la ressource virtualisée.
Un système de fichiers virtualisé permettra plus facilement de mettre en place une politique de redondance, de tolérance de panne et l'augmentation d'espace. L'usage de disques en RAID matériel vous permettra de pallier une panne disque, mais ne vous permettra pas d'agrandir facilement un volume. LVM vous permettra de facilement ajouter de l'espace en ajoutant par exemple un disque à un volume logique, vous permettra de facilement remplacer un disque en déplaçant son contenu d'un disque à l'autre, de créer des snapshots, voire d'utiliser un SSD en cache d'un disque mécanique. L’utilisation d’un système de fichiers distribué, comme nous allons le voir, vous permettra de gérer cela à plus grande échelle : il sera possible de sortir une machine contenant x disques du système pour la remplacer, et cela automatiquement. Le système de fichiers distribué se chargera de la répartition/duplication des données.
Même sans parler de cloud, utiliser un hyperviseur vous permettra de limiter le nombre de serveurs physiques à gérer (il faudra bien entendu une machine correctement dimensionnée) et de plus facilement le remplacer en déplaçant, d'une machine à l'autre, les machines virtuelles à chaud. Vous pourrez mettre en place une réplication et gérer de la répartition de charge.
L'intérêt d'utiliser des ressources mises à votre disposition par un hébergeur plutôt que votre propre matériel vous décharge de la surveillance matérielle de celui-ci, et vous permet de facilement augmenter ou diminuer les ressources que vous utilisez. La mise à disposition d'une machine virtuelle se fait en quelques minutes, voire quelques secondes ; solution qui vous demanderait en interne beaucoup de ressources ne serait-ce que par la préparation de templates (en temps passé et en matériel), vous monopolisant de la ressource pour un usage pas forcément fréquent. Chez un hébergeur, ce type de template n'occupe pas forcément de ressources de votre point de vue et n’est pas facturé si vous utilisez des templates prédéfinis par votre hébergeur.
6-2. Et les conteneurs dans tout ça ?▲
Un conteneur peut être vu comme un système de virtualisation léger, qui va servir à virtualiser une application ou un service (au sens démon Unix) plutôt qu'un OS complet. Contrairement à une machine virtuelle, un conteneur va partager le noyau de l'hôte. C'est un cloisonnement moins strict, mais demandant moins de ressources.
Les conteneurs prennent de plus en plus d'ampleur, et la plupart des fournisseurs de cloud fournissent du Container as a Service (CaaS).
Kubernetes est le système d'orchestration faisant référence et à la mode. Il est utilisé par la plupart des services cloud. Il vous permettra de déployer et de surveiller vos conteneurs.
6-3. Cadre des tests▲
Nos tests seront effectués depuis une distribution Debian 9 Stretch 64 bits. Au moment de la rédaction, Debian 10 Buster est la dernière version de la distribution, sortie le 6 juillet 2019. Celle-ci étant encore jeune, nous utilisons la version antérieure.
Les machines seront nommées srv1, srv2 et ainsi de suite. Aussi, le fichier hosts de chaque machine virtuelle doit permettre la correspondance entre l’adresse IP de la machine et son nom. Il est également possible d'utiliser un serveur DNS.
La compatibilité étant en général ascendante, le tutoriel pourra globalement s'appliquer aux versions système supérieures.
Les outils utilisés sont en général disponibles dans les autres distributions Linux.
Certaines commandes devront être adaptées comme remplacer :
/etc/init.d/mysql startpar :
service mysql startou :
systemctl mysql start7. Synchronisation de fichiers▲
Nous allons commencer par présenter la fonction me paraissant la plus simple à implémenter : la synchronisation de fichiers. Il s'agit globalement d'une des fonctions les plus utilisées par le grand public. Nous remplacerons ici les solutions grand public comme Dropbox ou Google Drive, ou les solutions similaires comme Owncloud/Nextcloud que nous avons déjà étudié.
Nous n'évoquerons dans cette partie que l'aspect brique minimal bas niveau de synchronisation.
Dans cette partie, nous ferons abstraction de l'aspect répartition de charge/haute disponibilité/tolérance de panne. Nous supposerons que votre système de synchronisation s'appuie sur une seule machine ou que le système de haute disponibilité est opérationnel.
Plusieurs produits de synchronisation de fichiers ont été testés :
- Seafile ;
- Syncthing ;
- SparkleShare ;
- Pydio.
Dans les produits testés, Syncthing et Pydio ont une version serveur sous Windows, tous le produits testés ont un client windows.
Cette liste n'est pas exhaustive et ne tient compte que des solutions testées.
7-1. Seafile▲
Seafile dispose d'une version serveur pour Linux, Raspberry, et Windows. Il est installable sous Mac OS X via les macports.
Seafile propose un client pour Windows, Linux, et Mac OS X. Il y a une application pour Android et une pour iPhone/iPad.
Il existe deux éditions, une community edition gratuite et une version sous licence propriétaire pour les entreprises, utilisable sans licence jusqu’à trois utilisateurs.
Vous pouvez voir sur cette page les différences entre la version community et la version professionnelle.
Seafile travaille avec une base de données, et va utiliser soit sqlite, soit MySQL.
Seafile nécessite Python et les dépendances suivantes :
- python-setuptools ;
- python-imaging ;
- python-mysqldb (ou python sqlite si utilisation de sqlite).
Nous pouvons les installer avec la commande suivante. Dans nos tests, nous utiliserons SQLite comme base de données.
apt-get install python-setuptools python-imaging python-sqlite sqlite3L'installation s'effectue par le chargement d'un tar.gz depuis le site Internet.
Vous pouvez récupérer le fichier ainsi (mais il y a de grandes chances qu’une nouvelle version soit disponible, lien à vérifier sur le site web) :
wget https://download.seadrive.org/seafile-server_7.0.5_x86-64.tar.gz --no-check-certificateUne fois le fichier tar.gz décompressé, l'installation s’effectue en lançant le script depuis le dossier contenant l’application décompressée :
setup-seafile.shPour la version MySQL, il faut lancer le script setup-seafile-mysql.sh.
Au cours de l’installation, les informations suivantes vous seront demandées :
- le nom du serveur ;
- le domaine ou l’adresse IP du serveur ;
- le chemin par défaut pour les données seafile (~/seafile-data par défaut) ;
- le port à utiliser : 8082 par défaut.
seafile va créer ses dossiers (conf, logs, pids, ccnet) dans le dossier parent de l'installeur. Le dossier data par défaut proposé se situe également dans le dossier parent.
Une fois la configuration effectuée, il va falloir modifier le fichier conf/gunicorn.conf et modifier bind = "127.0.0.1:8000" par "0.0.0.0:8000" pour pouvoir utiliser toutes les interfaces, ou l'adresse IP de la carte réseau sur laquelle vous voulez que seafile fonctionne. Vous pouvez également changer le port d'écoute (8000).
Une fois la configuration effectuée, il faudra démarrer le service seafile :
seafile.sh startpuis seahub :
seahub.sh startAu premier démarrage de seahub.sh, une adresse mail qui servira d'identifiant administrateur vous sera demandée dans la console, puis un mot de passe.
La connexion sur l'interface web se fera (par défaut) sur le port 8000 : http://addresse:8000
|
|

Il faudra utiliser l'adresse mail préalablement renseignée.
Vous aurez accès à l'écran d'interface :
|
|
Pour gérer vos documents, il vous faudra cliquer sur votre bibliothèque nommée « Ma bibliothèque ». Vous pourrez créer d'autres bibliothèques qui peuvent être vues comme des dossiers principaux.
Vous pourrez ensuite gérer vos documents :
|
|
Le menu « importer » permet d'importer des documents ou dossiers.
Sur la ligne des fichiers, vous pourrez :
- télécharger un document ;
- partager un document ;
- supprimer un document.
Les icônes sont explicites.
Sur la droite, vous aurez des liens permettant de voir les fichiers qui sont partagés avec vous ou que vous partagez.
7-1-1. Administration▲
Pour administrer les utilisateurs, il vous faudra depuis le compte administrateur cliquer sur l’icône en haut à droite (1), puis sélectionner « Administrateur système » (2) :
|
|
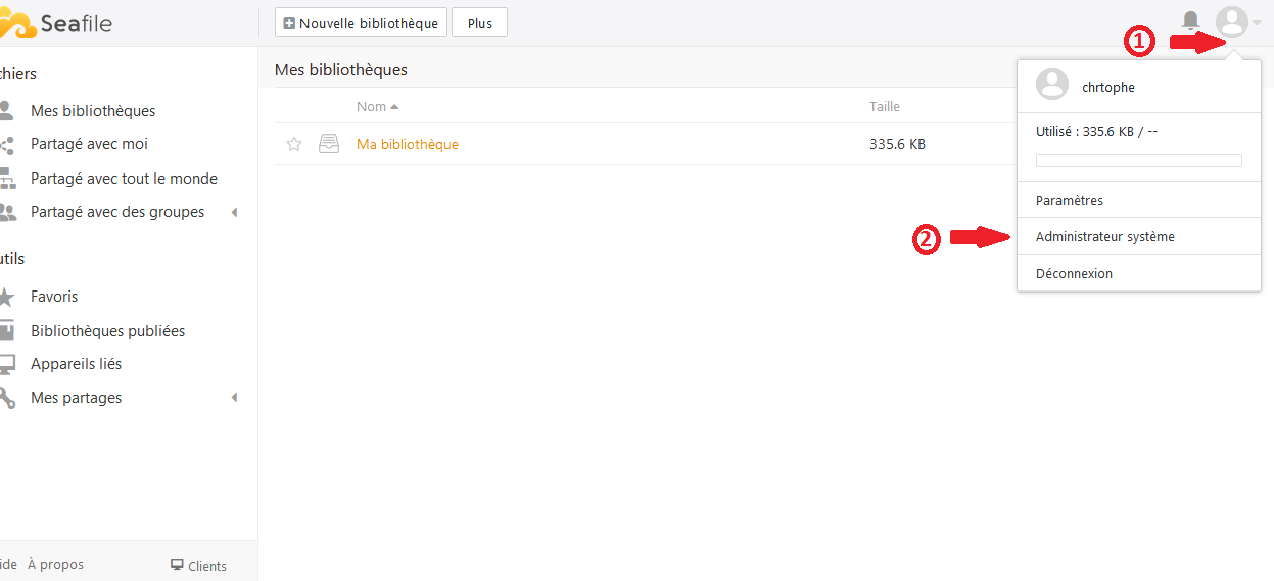
|
|
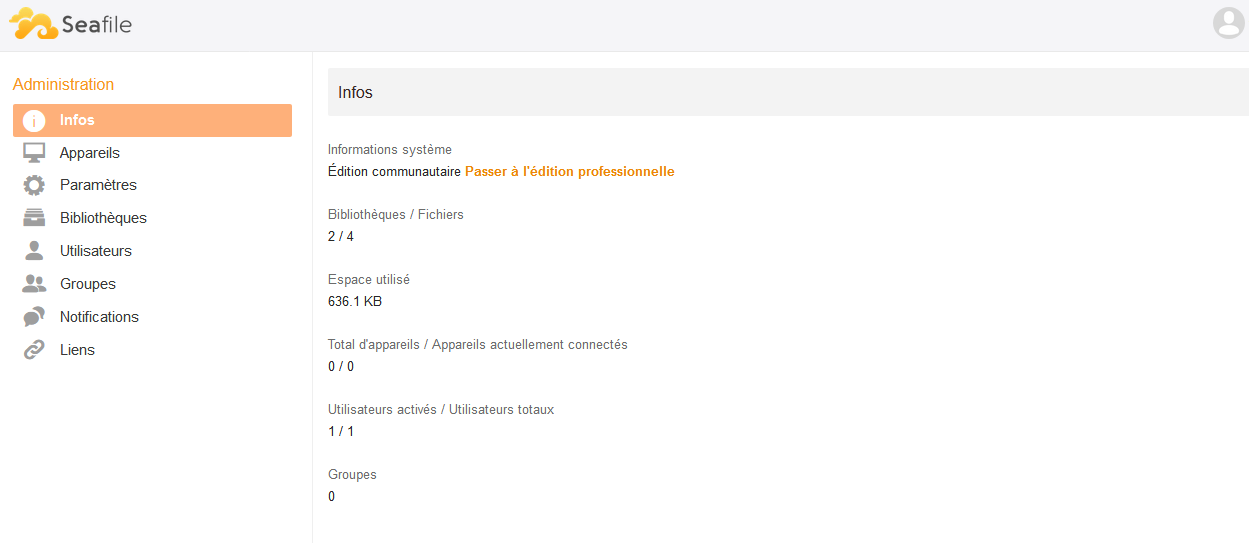
Dans l'interface Administration, vous pourrez :
- gérer les utilisateurs et groupes ;
- gérer les bibliothèques des utilisateurs (les supprimer, les partager, les transférer à d'autres utilisateurs) ;
- gérer les équipements connectés ;
- modifier les URL du serveur, le logo, l'image de fond.
Il est possible d'utiliser une connexion LDAP ou Active Directory. Mais vous devrez modifier la configuration du fichier ccnet.conf à la main. Rien n'est prévu dans l'interface graphique (du moins dans la partie graphique de la version communautaire). Exemple LDAP :
[LDAP]
HOST = ldap://192.168.1.123/
BASE = cn=users,dc=example,dc=com
USER_DN = administrator@example.local
PASSWORD = secret
LOGIN_ATTR = userPrincipalNamePour plus de détails, veuillez consulter la documentation.
Depuis l'interface web utilisateur, vous pourrez télécharger et uploader les fichiers, les gérer (les supprimer, les renommer), créer un lien de partage, accéder à l'historique des différentes révisions.
La gestion de la rétention des versions se fait depuis la bibliothèque. Vous pourrez choisir :
- pas d'historique ;
- historique illimité ;
- historique sur x jours.
Vous pourrez partager une bibliothèque avec d'autres utilisateurs ou groupes d'utilisateurs ou la transférer à un utilisateur.
Une bibliothèque peut contenir des dossiers.
Pour chaque bibliothèque, dossier, fichier, vous pouvez partager avec un utilisateur ou un groupe en lecture/écriture ou en lecture seule. Vous pouvez générer une URL de partage depuis l’icône ![]() sur la ligne de l'élément avec ou sans mot de passe de protection et avec ou sans expiration du lien.
sur la ligne de l'élément avec ou sans mot de passe de protection et avec ou sans expiration du lien.
7-1-2. Installation et utilisation du client▲
Une fois le client installé, lors de son premier démarrage, celui-ci vous demandera où stocker le dossier de synchronisation en local :
|
|
Vous seront ensuite demandées les informations de configuration (URL du serveur, identifiants) :
|
|
Vous pouvez choisir ou non une connexion automatique.
Vous aurez ensuite l'écran suivant :
|
|
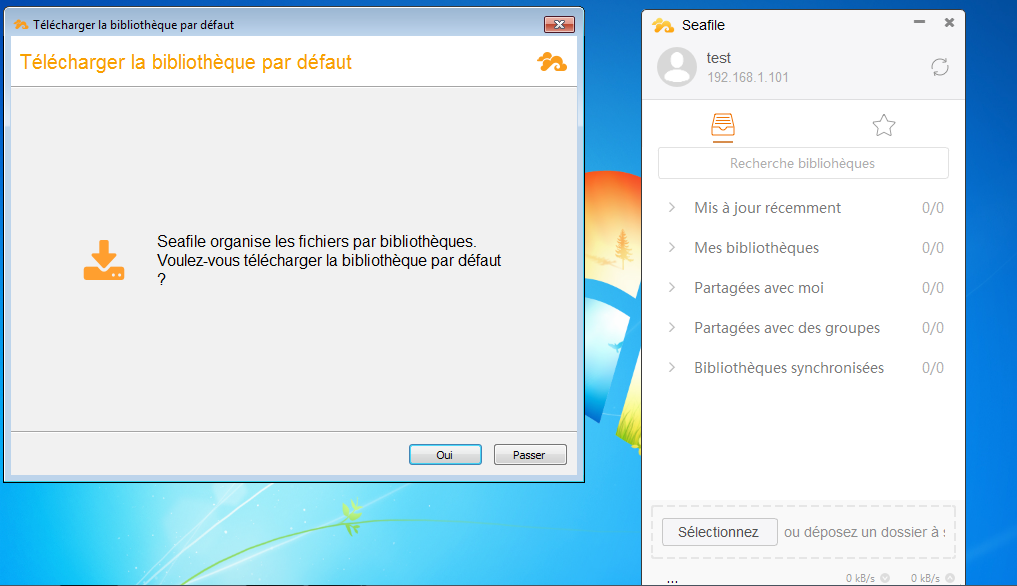
Un ajout ou modification de document sera répercuté sur le serveur.
Seafile ajoute un menu contextuel (uniquement disponible depuis le dossier synchronisé) :
|
|
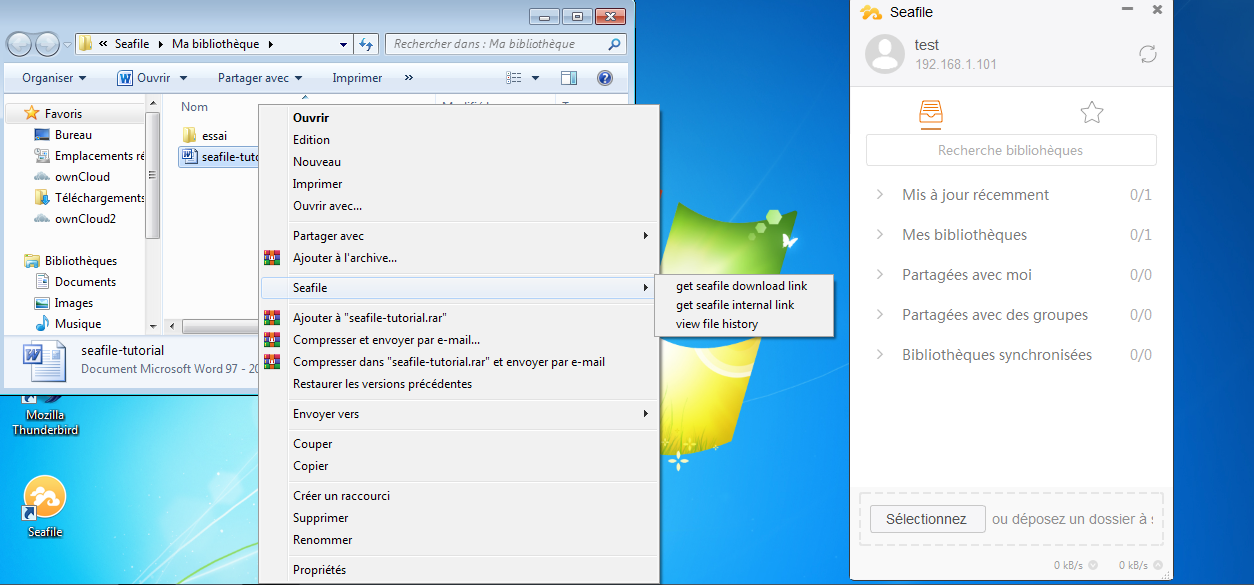
Ce menu – seulement disponible depuis le dossier synchronisé par Seafile – propose les options suivantes (le texte n'est pas traduit) :
- get seafile download link ;
- get seafile internal link ;
- view file history.
La première option va fournir un lien pouvant être communiqué. Connaître ce lien permettra le téléchargement sans authentification. L'option « téléchargement direct » télécharge sans ouvrir de page.
La seconde option est un lien nécessitant une connexion. Nous pouvons constater que le nom du fichier apparaît dans le lien, contrairement à la première option.
La troisième option permet d'accéder à l'historique des modifications du fichier. Ceci ouvre une page web à partir de laquelle nous pourrons restaurer une version précédente :
|
|
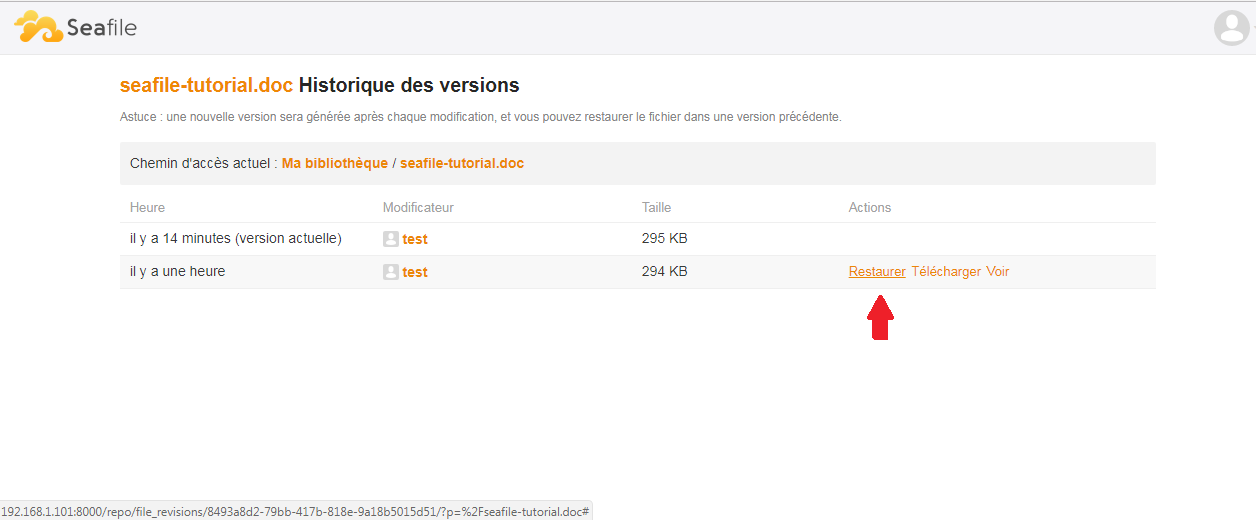
Pour synchroniser un dossier supplémentaire, il suffit de le sélectionner depuis le panneau seafile :
|
|
Nous pouvons voir que le dossier « nouveau dossier » qui a été sélectionné apparaît comme nouvelle bibliothèque.
Celle-ci sera visible depuis l'interface web :
|
|
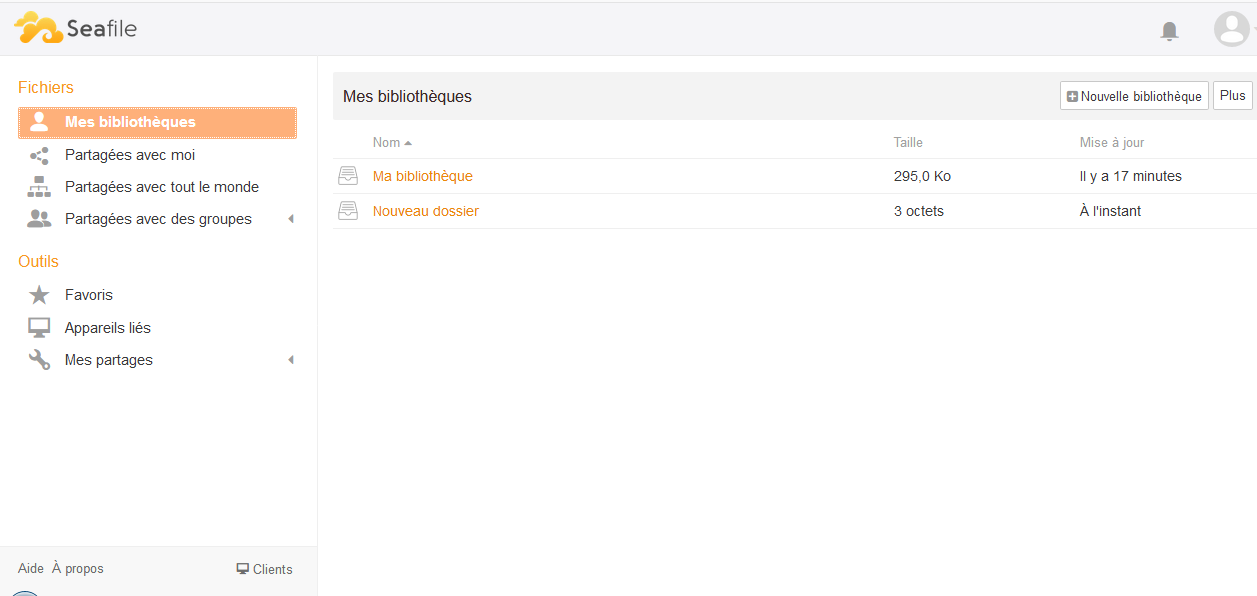
Lors de la sélection du dossier, nous pouvons voir une option permettant le chiffrement :
|
|
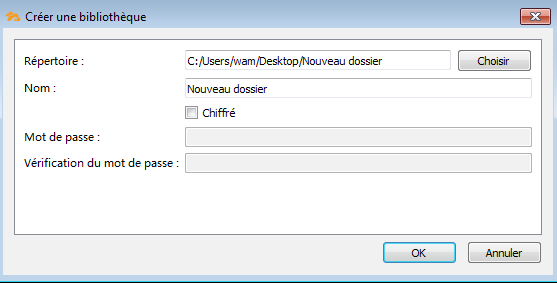
Il est possible d'utiliser HTTPS pour les dialogues, il faudra passer par Apache avec une configuration de virtualhost comme ci-dessous :
<VirtualHost *:443>
ServerName www.myseafile.com
# Use "DocumentRoot /var/www/html" for Centos/Fedora
# Use "DocumentRoot /var/www" for Ubuntu/Debian
DocumentRoot /var/www
Alias /media /home/user/seafile/seafile-server-latest/seahub/media
RewriteEngine On
<Location /media>
Require all granted
</Location>
#
# seafile fileserver
#
ProxyPass /seafhttp http://127.0.0.1:8082
ProxyPassReverse /seafhttp http://127.0.0.1:8082
RewriteRule ^/seafhttp - [QSA,L]
#
# seahub
#
SetEnvIf Authorization "(.*)" HTTP_AUTHORIZATION=$1
ProxyPass / http://127.0.0.1:8000/
ProxyPassReverse / http://127.0.0.1:8000/
</VirtualHost>Les chemins sont à adapter à votre situation.
Il faudra activer les modules rewrite et proxy_http :
a2enmod rewrite
a2enmod proxy_http7-1-3. Bilan▲
Les fichiers stockés dans le dossier seafile-data ne sont pas exploitables tels quels, ils sont stockés sous forme de blocs avec des noms de fichiers sous forme de UUID. La perte des bases de données signifiera la perte des documents sur le serveur. Il est possible d’effectuer un montage FUSE avec la commande seaf-fuse en indiquant le point de montage :
./seaf-fuse.sh start /mntDans le point de montage, vous allez trouver un dossier pour chaque utilisateur, qui va contenir un dossier par bibliothèque de l'utilisateur. Le nom du dossier de bibliothèque est composé d'un UUID suivi du nom de la bibliothèque. Les bibliothèques cryptées n’apparaîtront pas.
L'application Android fonctionne et m'a permis de modifier un document Word depuis l'application Word Android. Le document peut également être ouvert depuis stockage interne/seafile/nom utilisateur/[nom de la bibliothèque].
7-2. Syncthing▲
Syncthing est un système qui fonctionne en mode Peer 2 Peer, un peu comme BitTorrent. Des membres de la communauté mettent à disposition des serveurs de découverte, servant à mettre en communication deux postes devant se synchroniser. Ces serveurs ne participent pas au transfert de données. Vous pouvez utiliser vos propres serveurs de découverte, que vous pouvez ouvrir ou non à la communauté.
Syncthing est libre et écrit en Go.
Dans le cadre de ce tutoriel, nous installerons Syncthing sur une machine Linux qui se comportera comme un serveur dédié.
L'installation se fera via les dépôts de syncthing.
Vous pouvez aussi télécharger l'archive tar.gz sur le site de Syncthing.
Voici les commandes pour installer Syncthing :
wget https://syncthing.net/release-key.txt
apt-key add release-key.txt
apt-get update
echo 'deb https://apt.syncthing.net/ syncthing stable' >> /etc/apt/sources.list
apt-get update
apt-get install syncthingVous devrez peut-être installer le paquet apt-transport-https.
Dans les messages affichés sur la console, nous pouvons voir que par défaut, l'interface d'écoute est sur 127.0.0.1:8384.
Vous pourrez voir également des ouvertures de port vers l’extérieur que nous évoquerons plus tard.
Si vous exécutez syncthing en root, vous aurez un warning vous demandant d’exécuter celui-ci depuis un compte standard. Nous lancerons donc Syncthing depuis un compte non root.
Nous devons changer l'adresse d'écoute, qui par défaut est sur localhost. Pour cela, il faudra modifier le fichier config.xml se trouvant dans ~/.config/syncthing après avoir arrêté syncthing.
Il faudra descendre un peu dans le fichier jusqu’au bloc <gui …
Nous remplacerons donc la valeur dans le bloc <address>.
Appeler Syncthing tel quel va bloquer la console. Il faudra créer un démon de façon à pouvoir gérer le démarrage et l'arrêt.
Dans un premier temps, il sera possible d'ajouter une esperluette de façon à lancer l'application en tâche de fond :
syncthing &Lors de la première connexion, vous aurez l'écran suivant :
|
|
Par défaut, il n'y a pas de mot de passe, nous en avons un avertissement :
|
|
Nous cliquons sur « Configuration » :
|
|
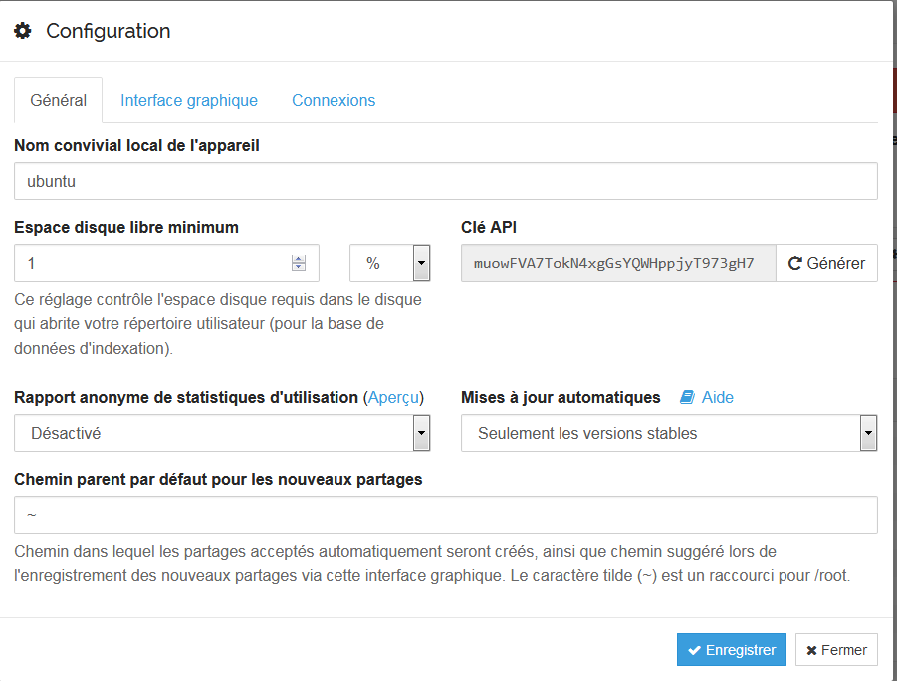
Nous pouvons renommer le serveur via le champ « Nom convivial local de l'appareil ».
Entrons dans le second écran « interface graphique » :
|
|
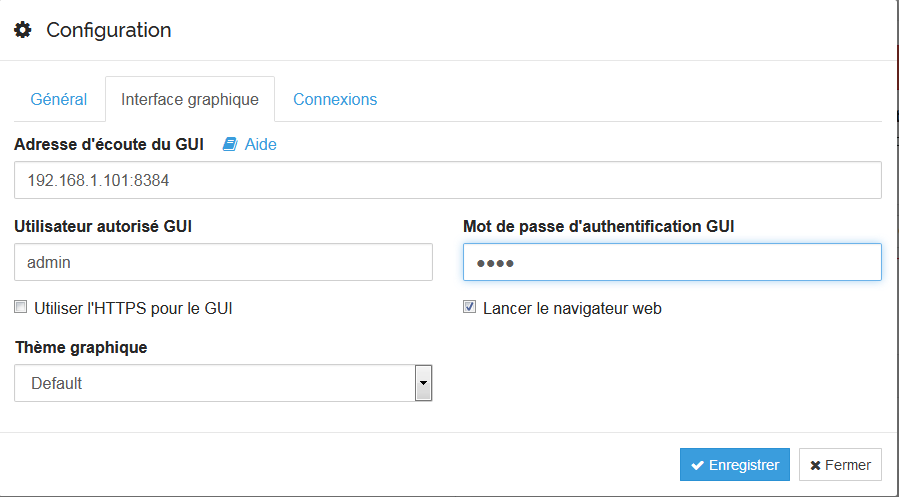
Nous pouvons également activer le support du HTTPS sur l'interface web.
Le navigateur nous retournera une alerte de sécurité, ceci à cause du certificat autosigné.
Une fois le mot de passe enregistré, nous aurons une fenêtre .htaccess d'authentification :
|
|
La modification de la configuration a posteriori se fera par le menu « Actions » en haut à droite :
|
|
Avant de gérer les partages, effectuons les réglages de connexion dans le dernier onglet de l'écran de configuration :
|
|
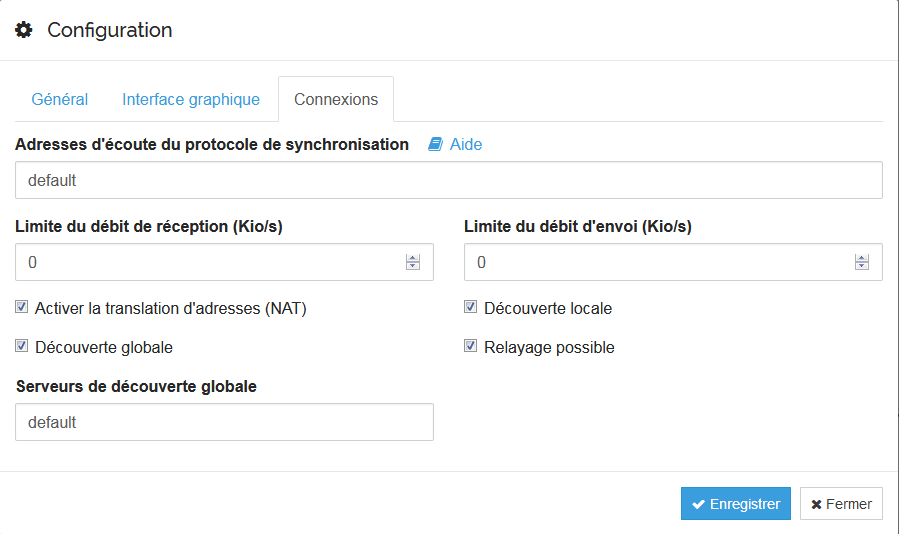
Syncthing fonctionne en mode P2P (peer to peer). Les blocs de fichiers peuvent être transférés depuis plusieurs nœuds. Chaque machine participante peut être à la fois cliente et serveur. Dans un réseau P2P, la gestion peut être centralisée ou décentralisée. Les nœuds doivent connaître les machines participantes pour pouvoir télécharger les fichiers, c'est le rôle des serveurs de découverte. Toute machine peut être serveur de découverte ou utiliser les serveurs de découvertes publics fournis par syncthing ou des serveurs mis à disposition par les membres de la communauté.
Si vous cochez la case « découverte globale », votre machine sera, par défaut, serveur global de découverte).
Pour utiliser uniquement votre serveur de découverte, vous devrez installer le paquet syncthing-discosrv. Le serveur de découverte se lancera avec la commande service stdiscosrv start.
Voir la remarque précédente sur la création d'un démon.
Si vous souhaitez utiliser votre propre serveur de découverte, il vous faudra supprimer « default » dans le champ « serveurs de découverte globale ».
Une fois l'entrée supprimée, et la configuration enregistrée, Syncthing vous informera qu'il faut redémarrer :
|
|
Au redémarrage, vous aurez l'avertissement suivant :
|
|
|
|

Syncthing ne sait pas quel serveur de découverte utiliser. Même si celui-ci est installé sur le même serveur, il faut lui renseigner son adresse IP précédée de https://.
7-2-1. Serveur de relais▲
Syncthing peut relayer des paquets entre deux machines si celles-ci ne peuvent pas communiquer en direct. Vous pouvez devenir relais et vous intégrer au pool de relais disponibles. Il vous faudra alors installer le paquet syncthing-relaysrv. Dans le cadre de ce tutoriel, nous n'utiliserons pas cette fonctionnalité et nous décocherons donc l'option « relayage possible ».
7-2-2. Création/modification des partages▲
Nous pouvons voir un « default folder » non partagé par défaut. En cliquant dessus, nous obtenons le détail :
|
|
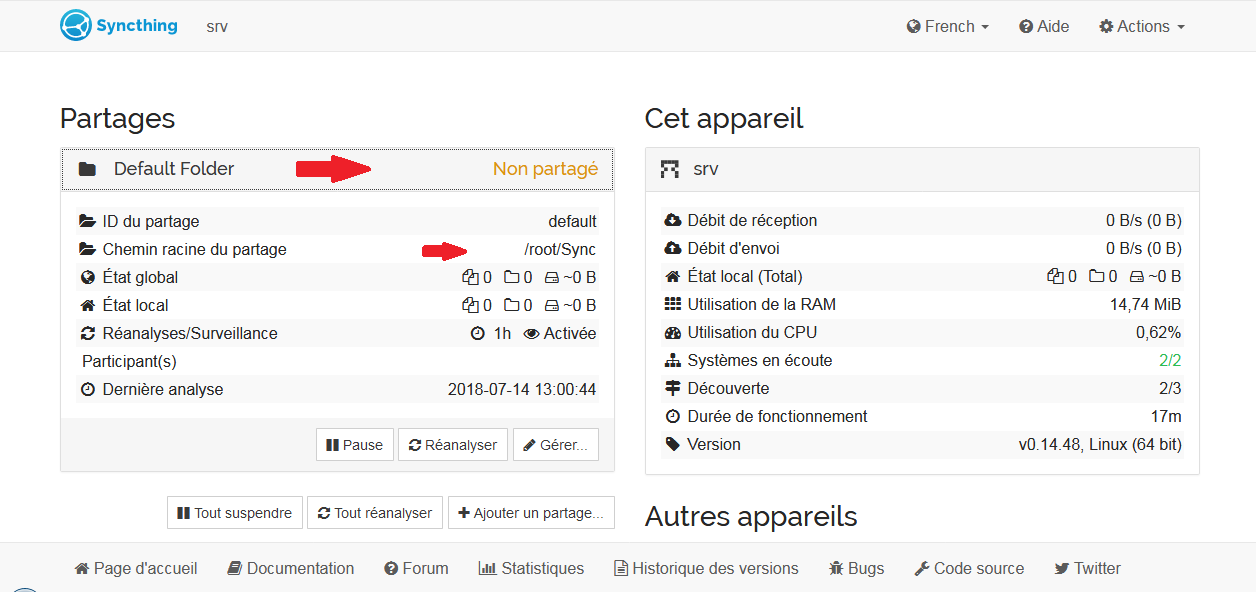
Nous pouvons voir que par défaut, le dossier partagé est ~/sync.
Vous pouvez l'activer, ou le supprimer et en créer d'autres (via les boutons ajouter, supprimer, gérer).
Les informations pertinentes seront :
- le nom du partage (onglet général) ;
- le dossier vers lequel celui-ci pointe (onglet général).
Le type de rétention du fichier dans l'onglet « Méthode de préservation des fichiers » avec :
- pas de poubelle ;
- style poubelle : les fichiers sont déplacés dans le dossier .stversion quand ils sont modifiés ou supprimés, il faudra indiquer le nombre de jours de conservation avant effacement définitif ;
- suivi simplifié de version : les fichiers modifiés/supprimés sont déplacés dans .stversion avec horodatage. Il faut indiquer le nombre de versions à conserver ;
- version échelonnée : un peu plus complète que le choix précédent, avec création d'un chemin relatif identique à l'emplacement d'origine. Pendant l'heure en cours, les versions sont conservées toutes les 30 secondes, au bout d'une journée, une version par heure est gardée, au bout de 30 jours, une version par jour est gardée, jusqu'à l'âge maximum (par défaut un an), une version est conservée par semaine ;
- gestion externe : gérée par une commande externe à syncthing, commande à renseigner.
Options avancées :
- intervalle d'analyse : impacte la fréquence de synchronisation et donc la bande passante utilisée ;
- type de partage : lecture seule (appelée envoi) ou lecture écriture (appelée envoi/réception).
Je vous laisse tester ou consulter la documentation concernant les autres options.
7-2-3. Utilisation du client Windows▲
Après récupération du fichier .zip Windows sur la page de téléchargement, nous le plaçons sur le disque C (choix arbitraire).
L'exécutable est en ligne de commande (sans interface graphique). Il y a un outil annexe nommé syncthing-gtk pour pouvoir travailler depuis l'interface graphique.
Nous téléchargeons et installons ensuite syncthing-gtk et obtenons l'écran suivant :
|
|
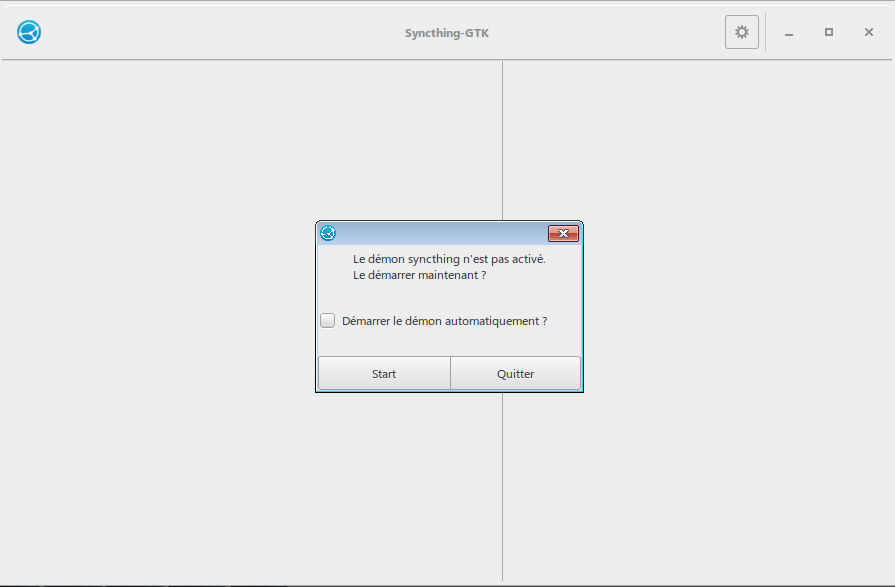
Nous activons le démon automatiquement.
Celui-ci va nous demander le chemin du démon que nous avons placé sur le disque C (à adapter si vous avez choisi un autre chemin) :
|
|
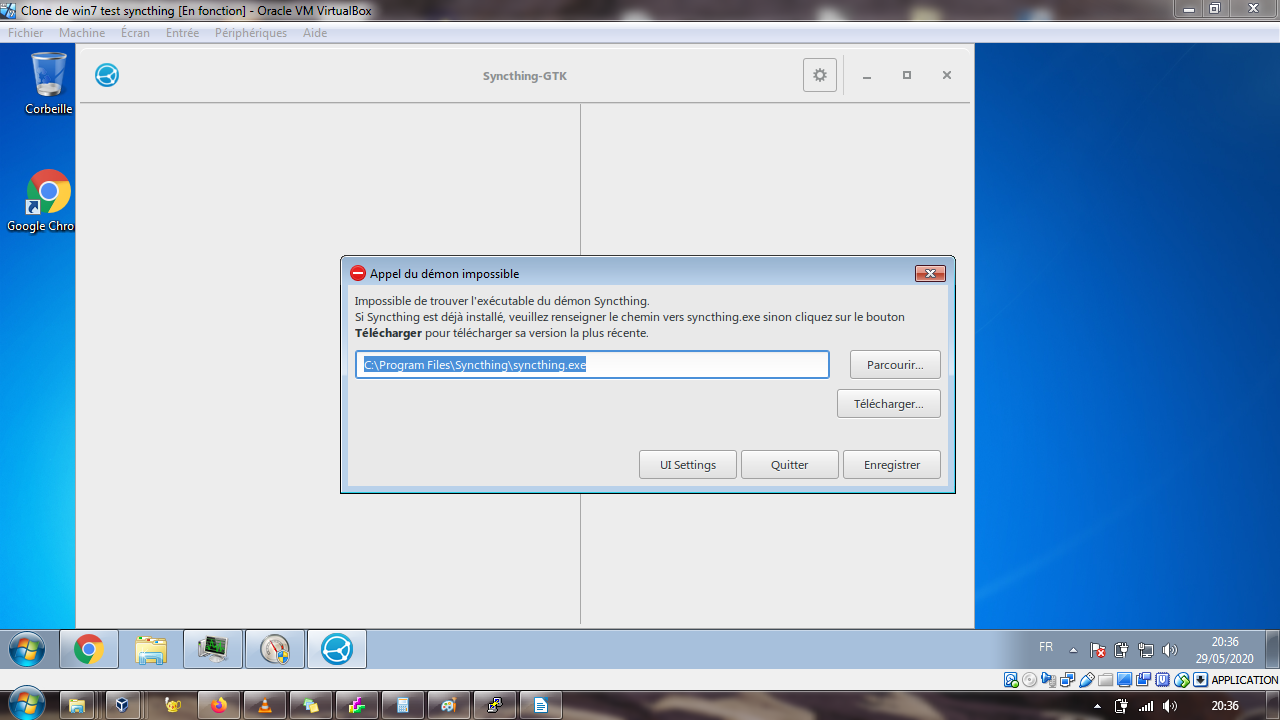
Après autorisation de l’accès au pare-feu Windows, nous obtiendrons l’écran suivant, similaire à celui de l’interface web précédemment vue :
|
|
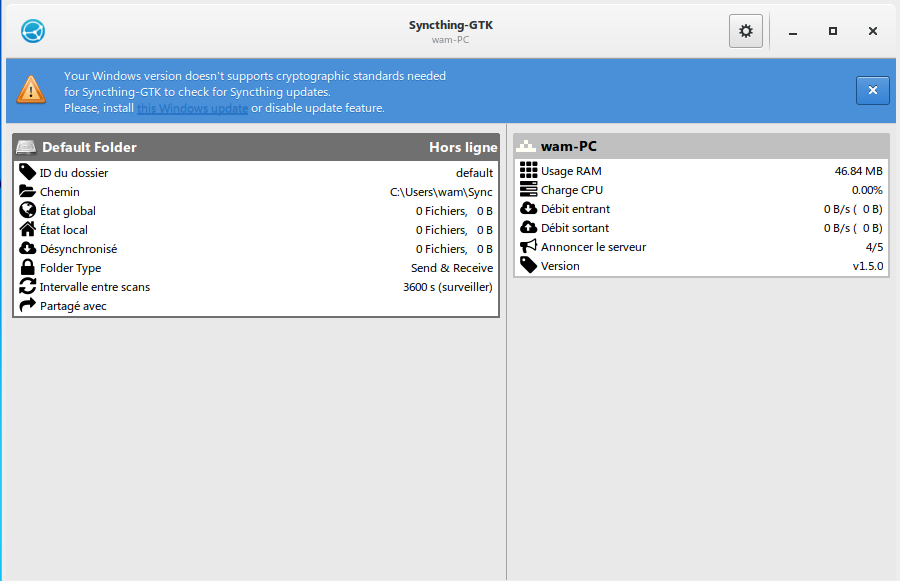
Depuis le navigateur, à l’adresse http://127.0.0.1:8384, nous obtenons la même interface, interface que nous avons déjà vue sur la machine faisant office de serveur.
Nous allons maintenant jumeler notre client Windows avec la machine Linux, pour cela, nous récupérons l'id du Linux depuis le menu Actions :
|
|
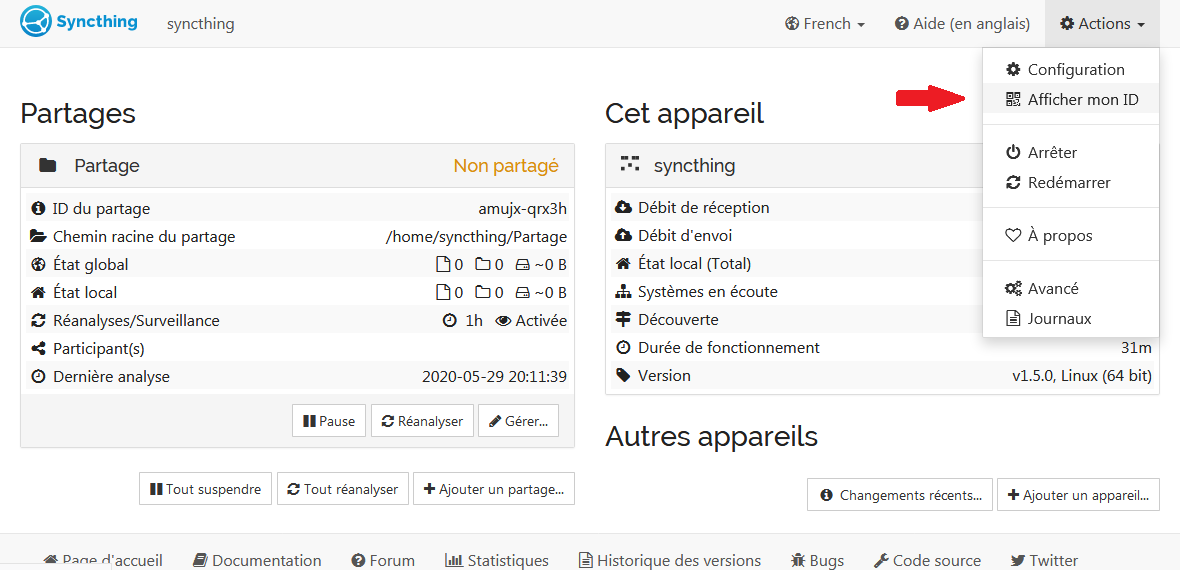
Celui-ci va nous donner un identifiant ainsi qu’un QR-Code :
|
|
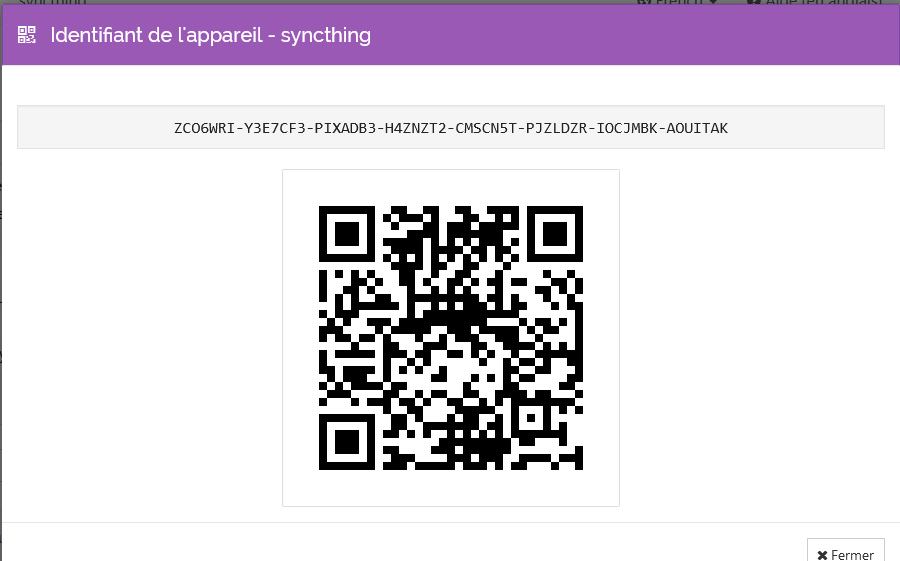
Dans le menu syncthing-gtk, nous ajoutons l'appareil :
|
|
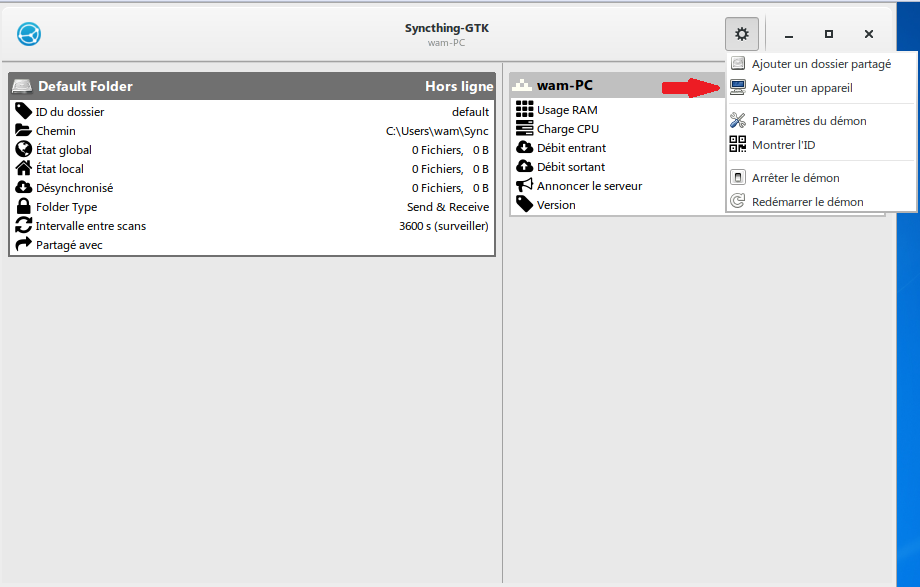
Nous cliquons « Ajouter un appareil » et renseignons les champs et surtout l’identifiant du serveur :
|
|
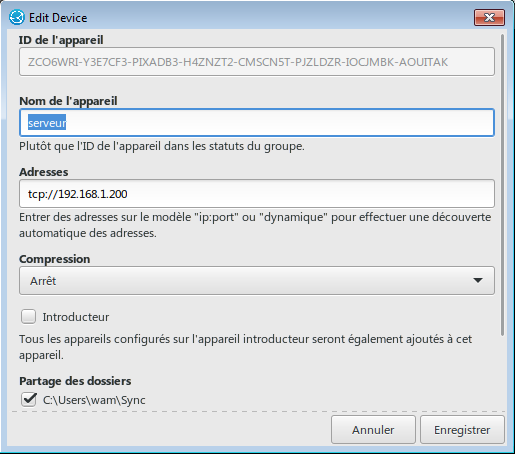
Les tests étant effectués en local, j'ai forcé l'utilisation de la machine Linux pour la découverte des machines.
Au niveau du serveur, nous avons le message suivant :
|
|
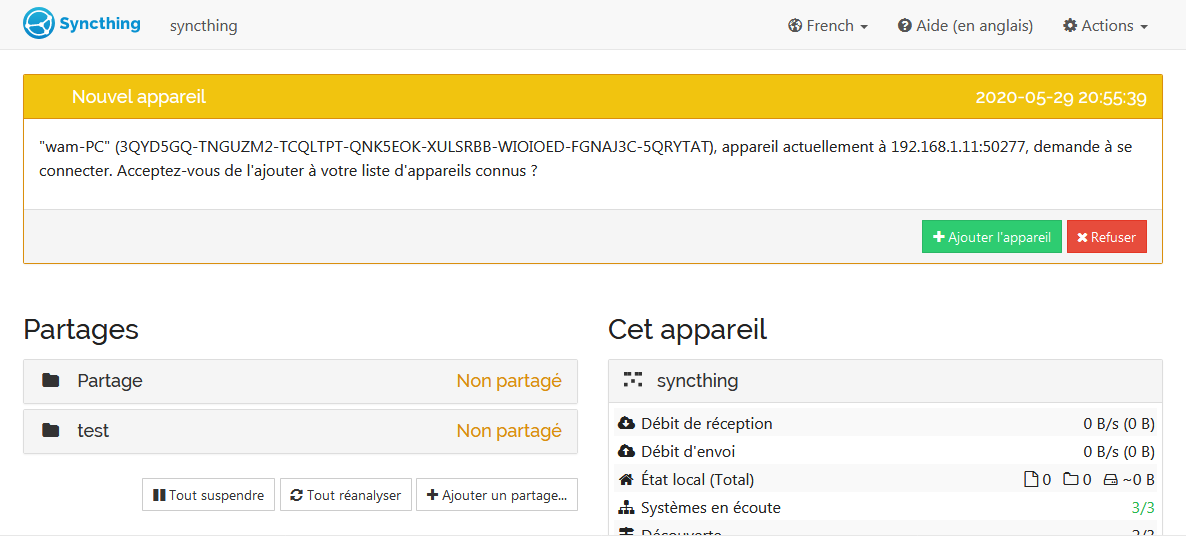
Une fois le bouton « Ajouter l'appareil » cliqué, les deux postes seront jumelés.
Nous avons ensuite le partage par défaut du Windows de test qui demande à être intégré :
|
|
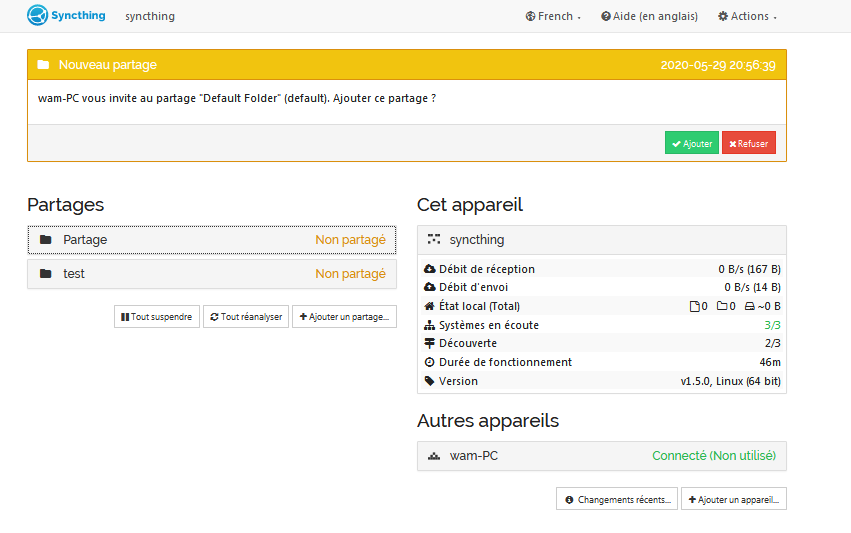
Dans le bas de l’écran, nous voyons que l’ordinateur wam-PC (le poste de test) est connecté.
Le dossier en provenance de wam-PC que nous nommons Commun va apparaître dans la liste des partages :
|
|
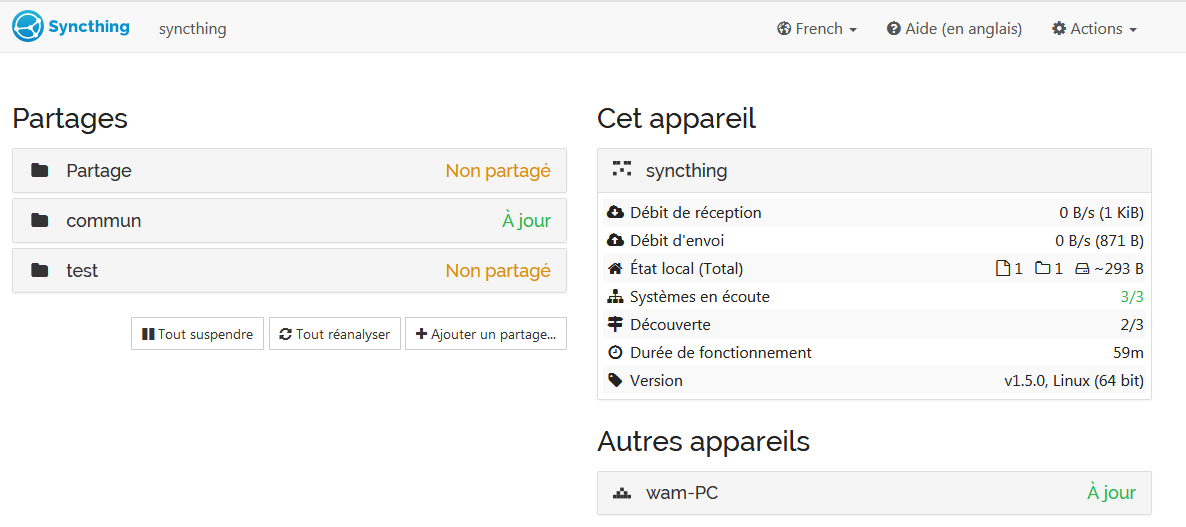
À ce stade, les fichiers stockés dans le dossier partagé du Windows (%userprofile%\Sync) vont apparaître dans le dossier /home/[compte Syncthing]/commun et vice-versa, la synchronisation est opérationnelle.
7-2-4. Bilan▲
Ce système ne nécessite aucun serveur en interne. Il a par contre l'inconvénient de pouvoir poser des difficultés pour passer les pare-feu par son utilisation P2P. Il faut aussi accepter l'utilisation de serveurs tiers pour la découverte à moins d'en mettre en service en interne et d'en interdire (ou autoriser) l'accès aux utilisateurs tiers.
7-3. Sparkleshare▲
SparkleShare s'appuie sur Git pour synchroniser les données. Le fait d'utiliser Git permet d'avoir facilement une gestion des versions. Les données sont transmises cryptées (par le biais de SSH).
SparkleShare est téléchargeable directement depuis le site web. Pour la version Linux, que nous utiliserons en serveur, SparkleShare recommande l'utilisation de Flatpak, un système de conteneur/paquets.
Nous commençons par installer flatpak :
apt-get install flatpak ca-certificatesLe paquet ca-certificate est un prérequis
et indique la méthode d'installation :
flatpak remote-add flathub https://flathub.org/repo/flathub.flatpakrepo
flatpak install flathub org.sparkleshare.SparkleShareLa commande renvoie :
Required runtime for org.sparkleshare.SparkleShare/x86_64/stable (org.gnome.Platform/x86_64/3.28) is not installed, searching...
Found in remote flathub, do you want to install it? [y/n]: y
Installing: org.gnome.Platform/x86_64/3.28 from flathub
Receiving delta parts: 0/10 13,8 MB/s 27,6 MB/268,4 MB 17 seconds remaining
10 delta parts, 81 loose fetched; 262039 KiB transferred in 315 seconds
Installing: org.freedesktop.Platform.ffmpeg/x86_64/1.6 from flathub
1 delta parts, 3 loose fetched; 2650 KiB transferred in 0 seconds
Installing: org.gnome.Platform.Locale/x86_64/3.28 from flathub
21 metadata, 82 content objects fetched; 2925 KiB transferred in 1 seconds
Installing: org.sparkleshare.SparkleShare/x86_64/stable from flathub
3 delta parts, 63 loose fetched; 93373 KiB transferred in 35 seconds
Installing: org.sparkleshare.SparkleShare.Locale/x86_64/stable from flathub
5 metadata, 1 content objects fetched; 2 KiB transferred in 0 seconds
root@Debian:~#Pour installer SparkleShare, il faudra télécharger le script suivant :
wget https://raw.githubusercontent.com/hbons/Dazzle/master/dazzle.sh --no-check-certificateUne fois le script rendu exécutable (chmod u+x), nous lancerons la commande :
./dazzle.sh setupCeci installera les dépendances, et finira par le message :
Setup complete!
To create a new project, run "dazzle create PROJECT_NAME".Nous créons ensuite un partage, nommé « PROJECT » dans la nomenclature SparkleShare.
Puis nous créons le projet « TEST » :
./dazzle.sh create TESTCeci va créer un dépôt git nommé TEST dans le dossier /home/storage/TEST.
~# ./dazzle.sh create TEST
Creating project "TEST"...
-> /usr/bin/git init --bare /home/storage/TEST
-> /usr/bin/git config --file /home/storage/TEST/config receive.denyNonFastForwards true
-> echo "*.DMG -delta" >> /home/storage/TEST/info/attributes
-> chown --recursive storage:storage /home/storage
-> chmod --recursive o-rwx /home/storage/TEST
Project "TEST" was successfully created.
To link up a SparkleShare client, enter the following
details into the "Add Hosted Project..." dialog:
Address: ssh://storage@192.168.1.15:
Remote Path: /home/storage/TEST
To link up (more) computers, use the "dazzle link" command.
~#Il est possible de créer plusieurs dépôts/projets sur la même machine.
7-3-1. Installation du client sous Windows▲
Nous lançons l'installation du client depuis le site officiel.
Il vous sera demandé votre adresse mail, car il est possible d'utiliser des dépôts GitHub ou Gitorious comme espace de stockage.
|
|
Un message indique la création d'un dossier de synchronisation, et propose un tutoriel :
|
|
Une fois l'installation effectuée, votre ID client sera affiché. Il sera possible de le réobtenir ultérieurement.
|
|
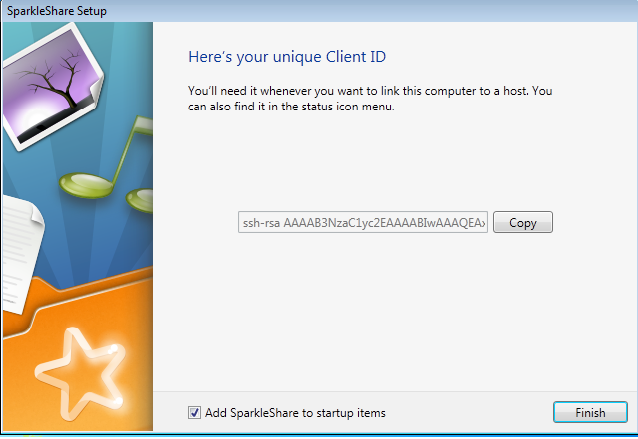
L'installation est ensuite terminée, reste à créer le connecteur.
La première chose à faire est d'enregistrer le client auprès du serveur :
~# ./dazzle.sh link
Paste your Client ID (found in the status icon menu) below and press <ENTER>.
Client ID: ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAxP/ZXGZ9v3TBK2R3RVR/FeJhsLdZeYtFT62EQ5qKdVCZayZ
ewZRMMoSMUphxyuJlPP88mTvfNiTHczED0fuzhnSDE9MMgDVpm3LXdF/8To5KSB010XQjX2A88AI8lkRIkrEXOAbZEiJfTt8TPXlDWd/pOisqiEpxQ4T+NrkEf4TEc5EpsBH5qxWGc5kMjgd8+1moItJ8BUpqVXcXDtJg1Aj3tzhr1SiuOO
dQmny5pA2+yFlT0qJ3sTCaCy8gD6OUeUYLhMvAU8kpyL2dwvbGVUVfKHIMjl6waCRMGhHQmRhF2
ADifBSd2CcqFO7LO8N7sUnLICoZ9ROaMKZ6ptUBfw== wam-PC
The client with this ID can now access projects.
Repeat this step to give access to more clients.
~#Il faut ensuite aller dans le menu contextuel de SparkleShare pour créer le connecteur et sélectionner « add hosted project » :
|
|
Nous sélectionnons ensuite « On my own server » et renseignons les données précédemment communiquées par le serveur (Address et Remote Path)
|
|
..
|
|
|
|
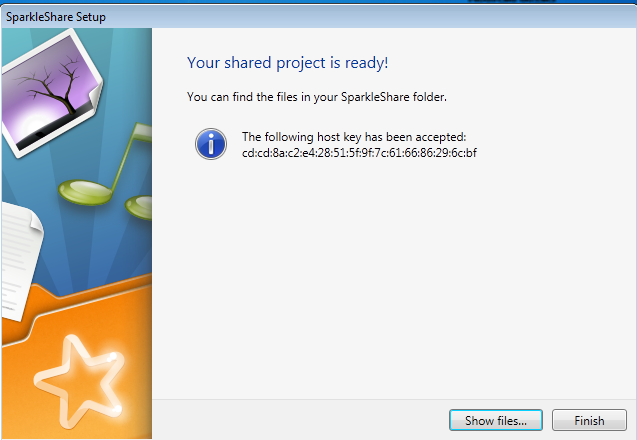
Sous Windows, le dépôt est copié en local dans le dossier %userprofile%\SparkleShare\<nom du projet>. Toute modification de ces fichiers est répercutée sur le serveur.
Il n'est pas possible de sélectionner le dossier à synchroniser dans le dépôt, ou d'en ajouter d'autres.
7-3-2. Suivi de version▲
Il est possible d'accéder à l'historique de version depuis le menu déroulant SparkleShare. Il faudra sélectionner « Recent changes » :
|
|
En cliquant sur les documents (au niveau de l'heure), il est possible d'accéder aux différentes révisions :
|
|
Cliquer sur « restore » va alors ouvrir une boite de dialogue demandant où enregistrer le fichier. Le nom de fichier par défaut est complémenté par la date et l'heure.
Il n'y a pas de fonction de nettoyage des versions ni de durée de rétention, la rétention est illimitée.
Vous pouvez nettoyer le dépôt avec les commandes suivantes depuis le dossier du dépôt (/home/storage/TEST dans notre exemple) :
git gc --prune=now --aggressivegit repack -a -d -lCette manipulation va effacer l'ensemble de l’historique dans le dépôt pour ne garder que les versions les plus récentes.
Cette manipulation a été faite suite à une recherche Internet, sans maîtrise de Git, cela peut peut-être avoir des conséquences.
7-4. Pydio▲
Pydio, acronyme de « Put Your Data In Orbit », a été créée par une startup française. Pydio (anciennement AjaXplorer) est fourni sous deux versions, une version communautaire et une version entreprise avec support et les fonctions supplémentaires suivantes :
- meilleure personnalisation de l'interface (couleurs, logo…) ;
- interface simplifiée de partage « easy transfer » similaire à WeTransfer ;
- possibilité de désactiver l'option de chat dans les Cells ;
- applications mobiles gratuites préconfigurées ;
- possibilité de faire des règles de sécurité autour des métadonnées ;
- politique d'autorisation dans le carnet d'adresses : partage des utilisateurs et des équipes avec d'autres utilisateurs ;
- politique d’historique de version plus poussée ;
- Dynamic Nodes Programming (pour des grosses volumétries) ;
- journaux d'usage séparés des journaux techniques ;
- possibilité de couper des sessions suspectes ;
- Role bases ACL (filtrage par IP, terminaux, géographie…..) ;
- les connecteurs aux annuaires depuis Pydio Cells ne sont plus dans la version gratuite (les connexions Pydio 8 étaient des contributions communautaires).
Il est disponible pour Windows, MacOS X, Linux (64 bits), IOS, et Android.
La version entreprise est disponible pour Linux et Mac OS Server. Des images OVF (Open Virtual machine Format) sont disponibles. Pydio est également disponible dans Docker.
Pydio fonctionnait précédemment en PHP, il a été complètement réécrit en Go. La nouvelle version se nomme Pydio Cells. Le terme Pydio utilisé ci-dessous désigne Pydio Cells.
Pydio nécessite MySQL 5.7 minimum (ou MariaDB >10.3).
Nomenclature Pydio
Pydio utilise les termes suivants dans sa nomenclature :
- Workspaces : contrôles d'accès principaux gérés par les administrateurs ;
- Cell : espace de travail dynamique géré par les utilisateurs.
7-4-1. Installation▲
7-4-1-1. Installation des prérequis▲
Nous installons MariaDB (sur Debian 9, mysql-server pointe vers MariaDB) :
apt-get install mysql-serverNous lançons ensuite le script mysql_secure_installation.
Nous créons ensuite une base de données :
~# Mysql -u root -p
MariaDB [(none)]> CREATE USER 'pydio'@'localhost' IDENTIFIED BY '<mot de passe>';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> CREATE DATABASE cells;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> GRANT ALL PRIVILEGES ON cells.* TO 'pydio'@'localhost';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> MaFLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> exit
Bye
~#7-4-1-2. Installation et configuration de Pydio▲
Nous commençons par créer l'utilisateur pydio :
adduser pydioNous nous loguons sous le compte Pydio, téléchargeons le .zip depuis le site et le décompressons.
~$ wget https://download.pydio.com/latest/cells/release/{latest}/linux-amd64/pydio-cells-{latest}-linux-amd64.zip –no-check-certificateUne fois le .zip décompressé, nous nous retrouvons avec un exécutable nommé cells (ou cells-enterprise pour la version entreprise) que nous lançons :
./cellsCelui-ci affichera un résumé de la documentation (équivalent à l’option –-help) dont voici la sortie :
Thank you for using Pydio Cells.
Comprehensive sync & share solution for your collaborators. Open-source software deployed on-premise or in a private cloud.
### Installation
For the very first run, use './cells install' to load browser-based or command-line based installation wizard. Services
will start at the end of the installation.
### Run
Run './cells start' to load all services.
### Logs level
By default, logs are outputted in console format at the Info level. You can set the --log flag or set the PYDIO_LOGS_LEVEL environment
variable to one of the following values:
- debug, info, error : logs are written in console format with the according level
- production : logs are written in json format, for usage with a log aggregator tool.
### Services Discovery
Micro services need a registry mechanism to discover each other. You don't need to install any dependency.
Cells currently only supports NATS (nats.io) implementation. If a gnatsd service is already running, it will be detected.
### Cells working directories
By default, application data is stored under the standard OS application dir :
- Linux: ${USER_HOME}/.config/pydio/cells
- Darwin: ${USER_HOME}/Library/Application Support/Pydio/cells
- Windows: ${USER_HOME}/ApplicationData/Roaming/Pydio/cells
You can customize the various storage locations with the following ENV variables :
- CELLS_WORKING_DIR : replace the whole standard application dir
- CELLS_DATA_DIR : replace the location for storing default datasources (default CELLS_WORKING_DIR/data)
- CELLS_LOG_DIR : replace the location for storing logs (default CELLS_WORKING_DIR/logs)
- CELLS_SERVICES_DIR : replace location for services-specific data (default CELLS_WORKING_DIR/services)
Usage:
./cells [flags]
./cells [command]
Available Commands:
acl Manage access control lists
completion Add auto-completion helper to Cells
config Configuration manager
data Directly interact with a datasource
doc Manage documentation about Cells and this CLI tool
help Help about any command
install Launch the installation process
meta Directly manage metadata on the nodes
ps List all available services and their statuses
start Start Cells services
stop Stop one or more services
update Check for available updates and apply them
user Manage users
version Show Pydio Cells version information
Flags:
--broker string Pub/sub service for events between services (currently nats only) (default "nats")
--broker_address string Broker port (default ":4222")
--enable_metrics Instrument code to expose internal metrics
--enable_pprof Enable pprof remote debugging
--fork Used internally by application when forking processes
--grpc_cert string Certificates used for communication via grpc
--grpc_external string External port exposed for gRPC (may be fixed if no SSL is configured or a reverse proxy is used)
--grpc_key string Certificates used for communication via grpc
-h, --help help for ./cells
--log string Sets the log level mode (default "info")
--registry string Registry used to manage services (currently nats only) (default "nats")
--registry_address string Registry connection address (default ":4222")
--registry_cluster_address string Registry cluster address (default ":5222")
--registry_cluster_routes string Registry cluster routes
--transport string Transport protocol for RPC (default "grpc")
--transport_address string Transport protocol port (default ":4222")
Use "./cells [command] --help" for more information about a command.Nous procédons comme indiqué à l'installation :
./cells installNous obtenons le résultat suivant :
[Configs] Upgrading: setting default config services/pydio.web.oauth/secret to WRESXzxulWGn9-gK8.kKeqcwB4xBfVHM
[Configs] successfully saved config after upgrade - Reloading from source
WARNING: File descriptor limit 1024 is too low for running Pydio Cells Home Edition in production. At least 8192 is recommended. Fix with "ulimit -n 8192".
Welcome to Pydio Cells Home Edition installation
Pydio Cells Home Edition will be configured to run on this machine. Make sure to prepare the following data
- IPs and ports for binding the webserver to outside world
- MySQL 5.6+ (or MariaDB equivalent) server access
Pick your installation mode when you are ready.
Cannot find vaultKeyPath, creating new one /home/pydio/.config/pydio/cells/cells-vault-key
**************************************************************
Warning! A keyring is not found on this machine,
A Master Key has been created for cyphering secrets
It has been stored in /home/pydio/.config/pydio/cells/cells-vault-key
Please make sure to secure this file and update the configs
with its new location, under the defaults/keyPath key.
***************************************************************
Use the arrow keys to navigate: ↓ ↑ → ←
? Installation mode:
▸ Browser-based (requires a browser access)
Command line (performed in this terminal)Nous choisissons l'installation via le navigateur (Browser-based). L'installeur va nous proposer l'adresse utilisable correspondant à l'adresse IP de la machine sur le port 8080, que nous sélectionnons :
- Browser-based (requires a browser access)
Use the arrow keys to navigate:
Use the arrow keys to navigate:
Binding Host (ip:port or yourdomain.tld that the webserver will listen. If internal and external urls differ, use internal here):
+ Other
- 192.168.1.200:8080
localhost:8080- Browser-based (requires a browser access)
Use the arrow keys to navigate:
- 192.168.1.200:8080
- External Host (used to access this machine from outside world if it differs from Bind Host): 192.168.1.200:8080Nous validons par un retour chariot.
L'étape suivante consiste à régler SSL, il nous est proposé :
- d'entrer le chemin des certificats ;
- d'utiliser un certificat Let's Encrypt ;
- de générer un certificat autosigné.
Use the arrow keys to navigate: ↓ ↑ → ←
? Choose TLS activation mode. Please note that you should enable SSL even behind a reverse proxy, as HTTP2 'TLS => Clear' is generally not supported:
Provide paths to certificate/key files
▸ Use Let's Encrypt to automagically generate certificate during installation processerate your own locally trusted certificate (for staging env or if you are Generate your own locally trusted certificate (for staging env or if you areL'installeur depuis la ligne de commande se met ensuite en écoute sur le port web Pydio (8080). Voici l'écran de l'interface d'installation web :
|
|
En version Entreprise, vous aurez un écran supplémentaire vous demandant d'entrer votre clé de licence :
|
|
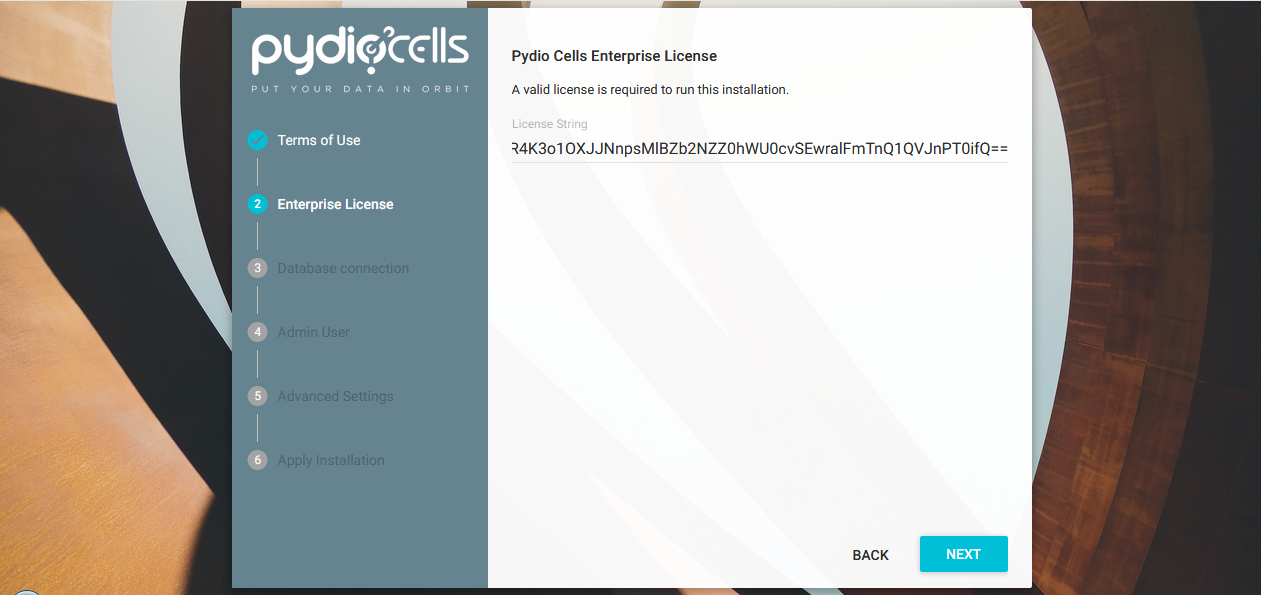
Une fois les conditions acceptées, nous nous retrouvons dans l'écran de paramétrage de la base de données :
|
|
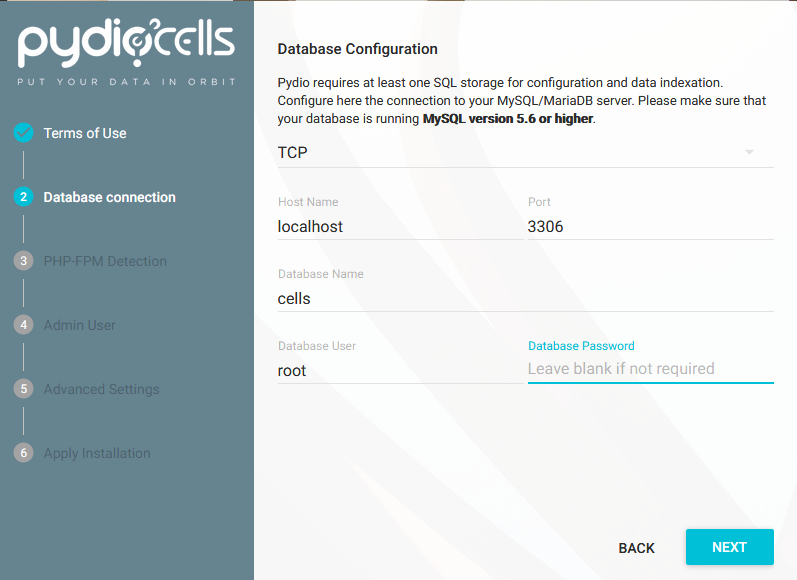
Nous arrivons ensuite à l'écran nous demandant :
- le nom de l'application ;
- la langue par défaut ;
- le login et mot de passe d'administration.
|
|
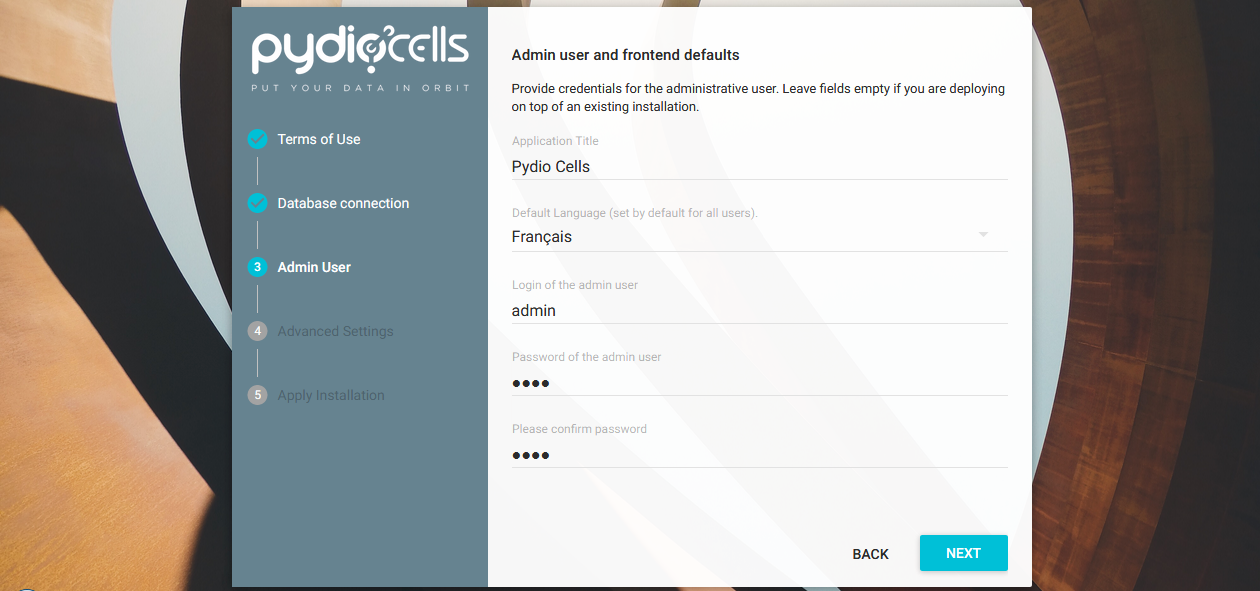
Un dernier écran de confirmation avant installation permettant d'afficher un résumé des réglages (détail affiché via l'appui du bouton à cet usage) :
|
|
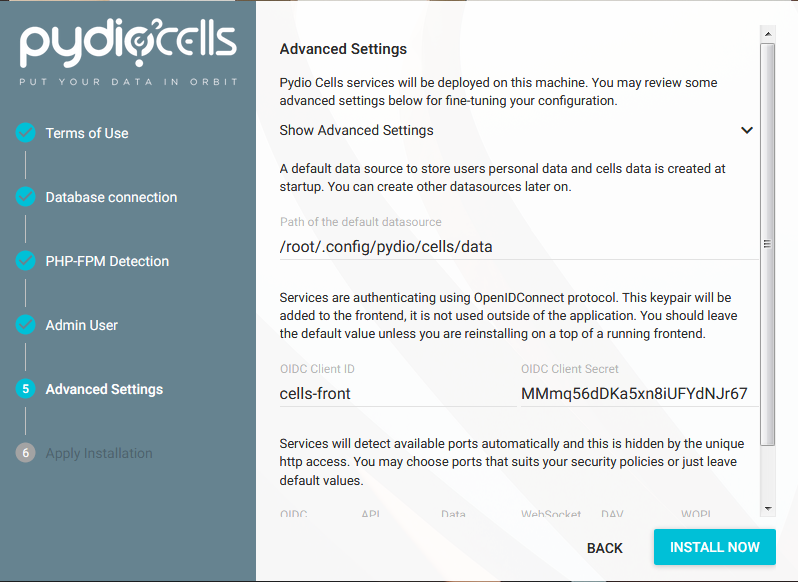
Vous aurez ensuite le message « install successful » indiquant que la fenêtre sera rechargée une fois les services activés :
|
|
Nous nous retrouvons ensuite devant l’écran de connexion :
|
|
Une fois l'installation terminée, il faudra redémarrer cells avec l'option start comme ceci :
$ ./cells startRestera ensuite à automatiser le démarrage (par la création d'une Unit systemd).
7-4-2. Découverte de l'interface▲
Une fois connectés, nous nous trouverons devant une interface assez simple d'utilisation. Dans la partie gauche (1), vous avez les différentes « Cells », pouvant être vues comme une bibliothèque ou unité de partage. Vous avez aussi votre répertoire par défaut (« Personal files »).
Dans la barre en haut, vous avez les fonctions afférentes aux fichiers (2), puis en dessous les fichiers présents (3). Et enfin, dans la partie droite, le détail sur les fichiers (4).
|
|
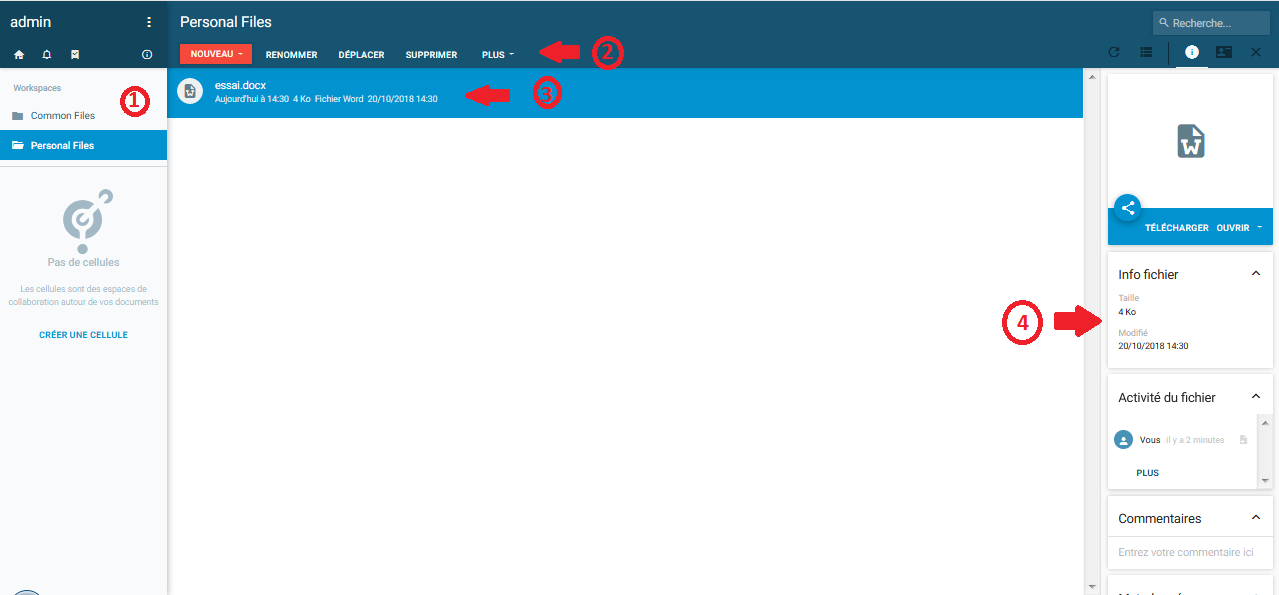
Il est également possible de faire les manipulations sur les fichiers en cliquant dessus avec le bouton droit de la souris pour obtenir le menu contextuel :
|
|
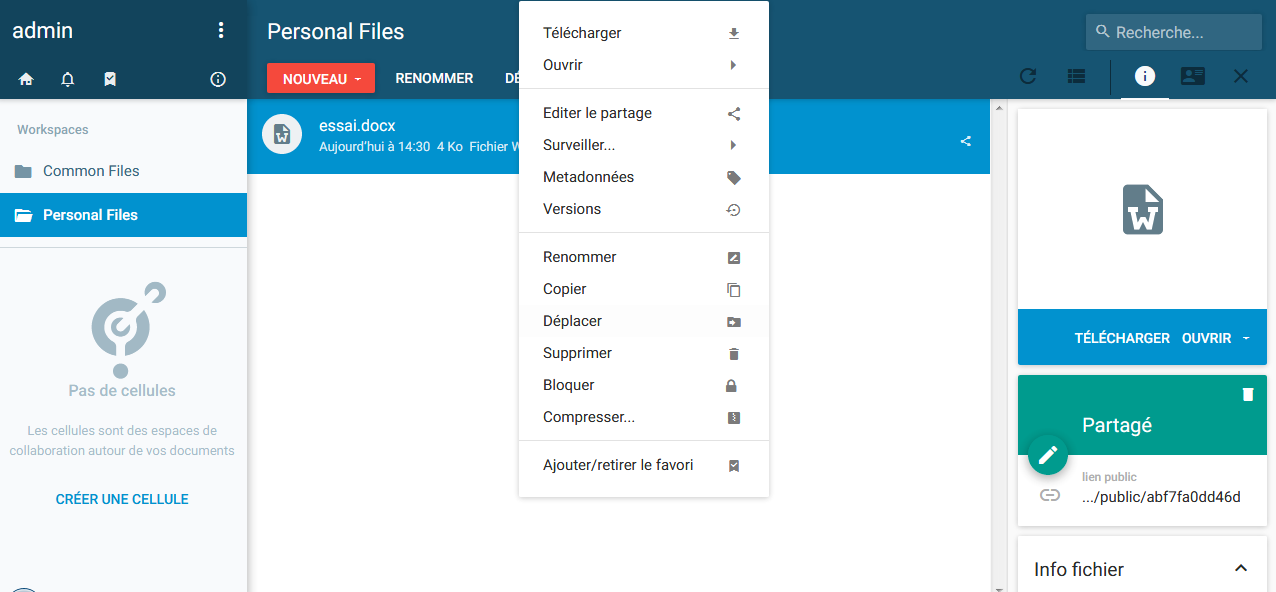
7-4-2-1. Partage▲
Pour partager un fichier, vous avez deux possibilités :
- créer un lien de partage public ;
- mettre le document dans un Cell pour le partager.
Pour activer le lien public, il faut cliquer sur le bouton droit pour activer le lien public :
|
|

Le lien sera ensuite affiché :
|
|
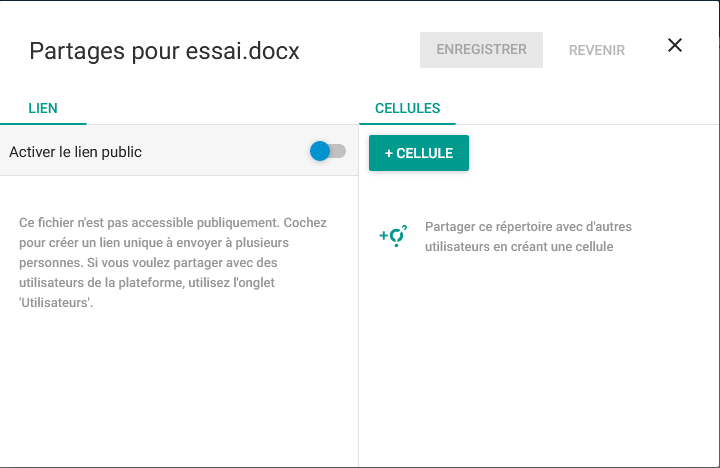
En cliquant sur Accès, vous pourrez :
- mettre un mot de passe restreignant l'accès :
- mettre une date d'expiration :
- limiter le nombre de fois que le fichier peut être téléchargé.
|
|
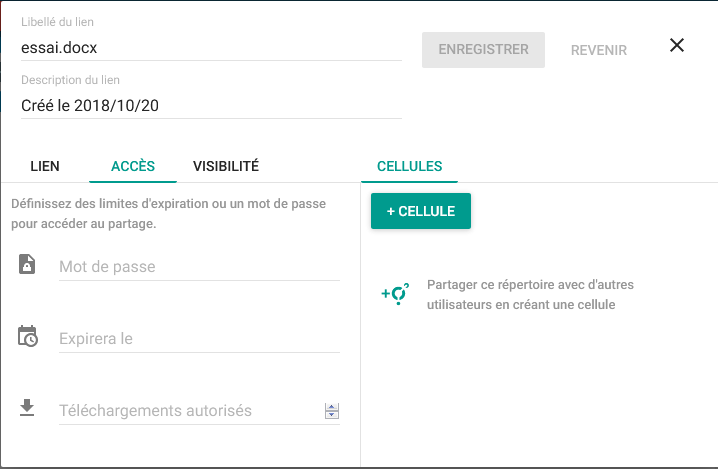
Écran correspondant à un lien de partage :
|
|

En cas de téléchargement expiré ou de nombre maximum atteint, vous aurez ce type de message :
This link as expired (number of maximum downloads has been reached).Pour partager avec un utilisateur Pydio, il faudra sélectionner celui-ci dans la partie droite en cliquant sous le nom du fichier, ce qui fera apparaître un menu déroulant avec les utilisateurs. Vous pourrez choisir les droits (lecture ou lecture/écriture) :
|
|
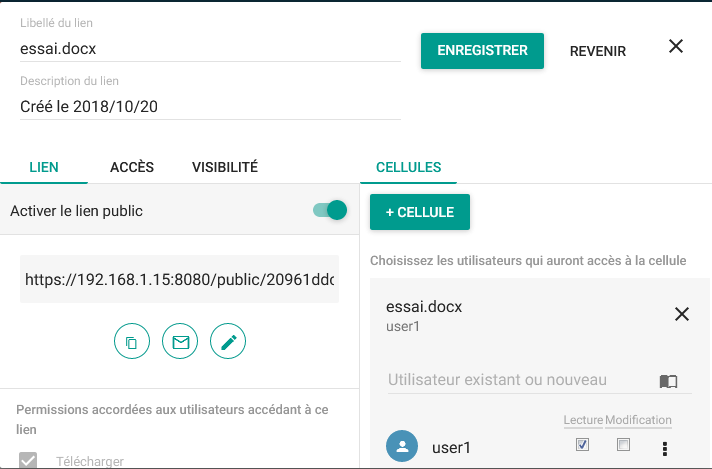
Une fois le partage créé, l'entrée du menu contextuel change de « Partager » à « Éditer le partage ».
7-4-3. Administration▲
Seules les options les plus pertinentes sont détaillées ci-dessous.
L'accès à l'interface d'administration se fait en cliquant sur les trois points en haut à gauche, depuis le compte administrateur :
|
|
|
|
Le retour à l'interface standard se fait en cliquant sur l’icône dossier en haut à droite.
Voici l'interface d'administration pour la version communautaire :
|
|
Pour avoir accès à toutes les fonctionnalités, il faudra cliquer sur l’icône ![]() en haut à droite.
en haut à droite.
Une fois dans l’écran d'administration, vous aurez sur la gauche cinq catégories :
- Gestion des identités ;
- Gestion des données ;
- Logs & autres données ;
- Configurations globales ;
- Ressources développeurs.
7-4-3-1. Gestion des identités▲
La section « Gestion des identités » permet de gérer les utilisateurs et leurs droits.
Pour gérer les utilisateurs, il faut cliquer sur « Utilisateurs » :
|
|
En cliquant sur le crayon à côté du nom d'un utilisateur, nous avons accès au détail de son compte avec notamment la langue (effectif après reconnexion), les Cells auxquels il a accès :
|
|
En cliquant sur les trois petits traits en haut à droite de la fenêtre de l'utilisateur, vous pourrez changer le mot de passe, avec une option forçant le changement immédiatement, et « Exclure » celui-ci. Exclure un utilisateur signifie suspendre son compte (qu'il sera possible de réactiver).
Supprimer un utilisateur n'effacera pas son dossier personnel dans les données de Pydio.
Vous aurez aussi accès à la gestion des droits des dépôts (workspaces) accessibles :
|
|
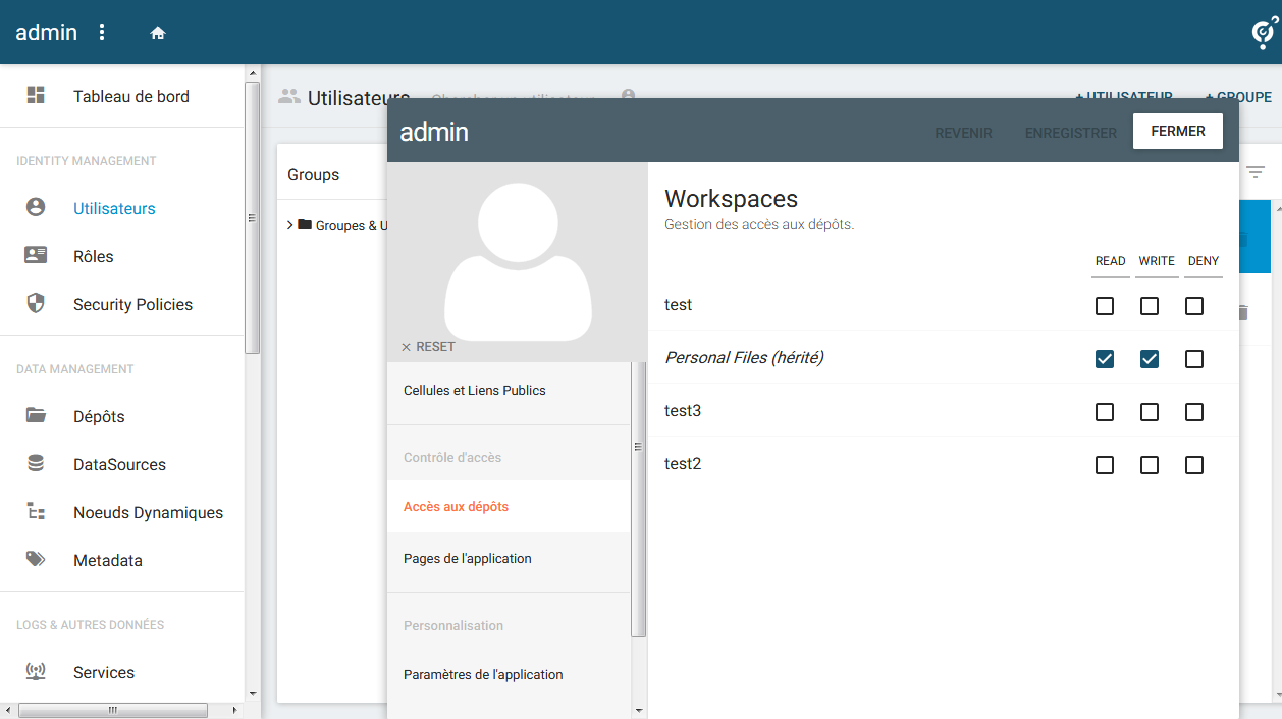
La gestion des rôles permet de créer des règles par défaut pour un groupe d'utilisateurs (accès à certains dépôts, langue par défaut, etc.).
7-4-3-2. Gestion des données▲
La partie dépôts vous permettra d'ajouter de nouveaux workplaces pointant sur un sous-dossier du disque (pour créer un nouveau dossier, il faudra taper son nom).
Il est précisé dans l'interface que la synchronisation est expérimentale.
La partie Datasources permet de gérer les volumes accessibles à Pydio, avec par défaut le volume local. Vous pouvez également utiliser un volume Amazon S3. C'est à ce niveau que se gère le versioning. C'est à cet endroit également que vous pourrez activer le chiffrement.
Le système de gestion des versions propose :
- tout garder (keep all) ;
- maximum 30 jours : garde trois versions et efface celles supérieures à 30 jours ;
- Suppressions régulières : rétention jusqu'à 10 versions avec espacement 10 min, puis 3 h, puis 1 jour, etc. (voir détail en cliquant sur la fonction).
7-4-3-3. Configurations globales▲
Dans la partie options principales, vous retrouverez le titre de l'application ainsi que la langue par défaut. Ce sont les éléments qui ont été demandés lors de l'installation.
Dans la partie envoi de courriels, vous pourrez positionner les réglages permettant à Pydio d’envoyer des mails.
Dans la partie Authentification, vous pourrez régler la longueur minimale du mot de passe.
Dans la partie extensions, vous pourrez activer/désactiver des fonctionnalités optionnelles comme le visualiseur PDF, l'aperçu d'images, le visualiseur OpenDocument, l'accès à Collabora Online.
7-4-4. Utilisation du client▲
Le client Pydiosync est disponible pour Windows, Mac OS X, et Linux, mais uniquement pour l'ancienne version Pydio 8.
Pas de client PydioSync pour Pydio Cell pour le moment.
Une fois le client Pydiosync installé, la première chose à faire sera de créer une synchronisation :
|
|

Nous entrons ensuite les éléments nécessaires à la connexion (ne pas oublier de préciser le port : 8080 par défaut) :
|
|
7-4-4-1. Stockage des fichiers sur le disque▲
Les fichiers que vous stockez dans Pydio sont retrouvables dans le compte utilisateur utilisé pour faire fonctionner Pydio dans le dossier ~/.config/pydio/cells/data/ soit dans le sous-dossier cellsdata/[nom d'utilisateur] soit dans personal/[nom d'utilisateur]. Le dossier versions va contenir les différentes versions des fichiers sous forme de nom de fichier UUID.
La sauvegarde de la totalité du dossier .config/pydio/cells permet de conserver les données et la configuration. Il ne faudra pas oublier d'y associer un dump de la base de données.
7-4-5. Version commerciale▲
La première différence visible concerne le tableau de bord, avec des informations globales pour l'administrateur :
|
|
Contrairement à celui de la version communautaire :
|
|
La différence suivante est l'apparition d'une entrée supplémentaire « External Directories » servant à créer un connecteur LDAP ou Active directory :
|
|
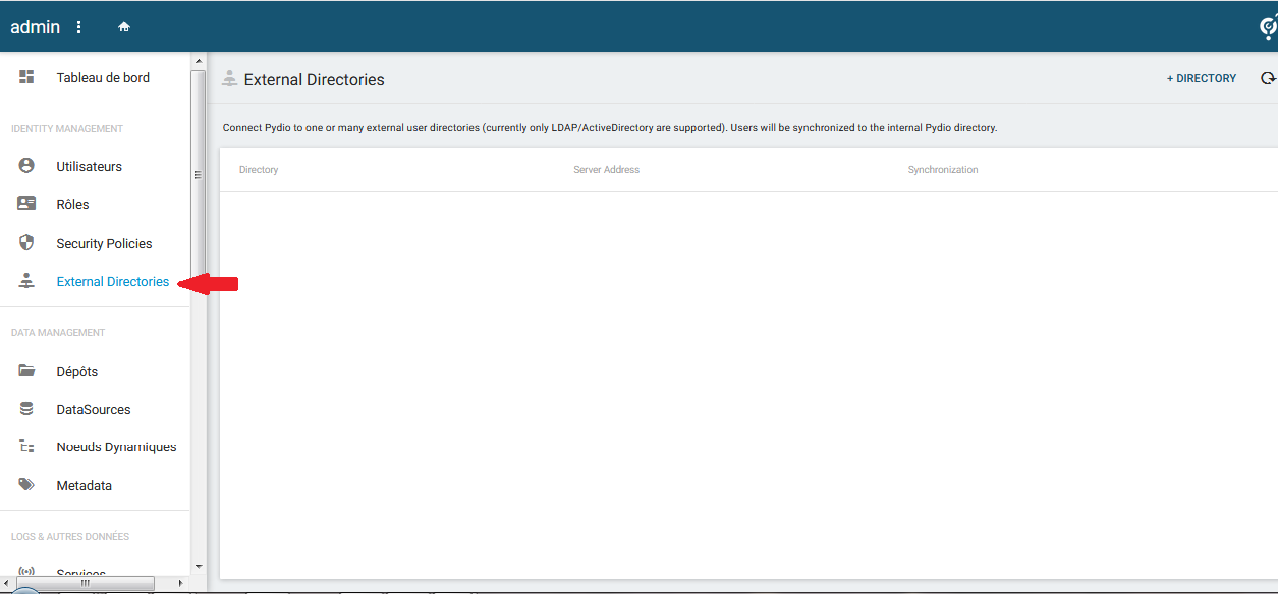
Voici l'écran de réglages :
|
|
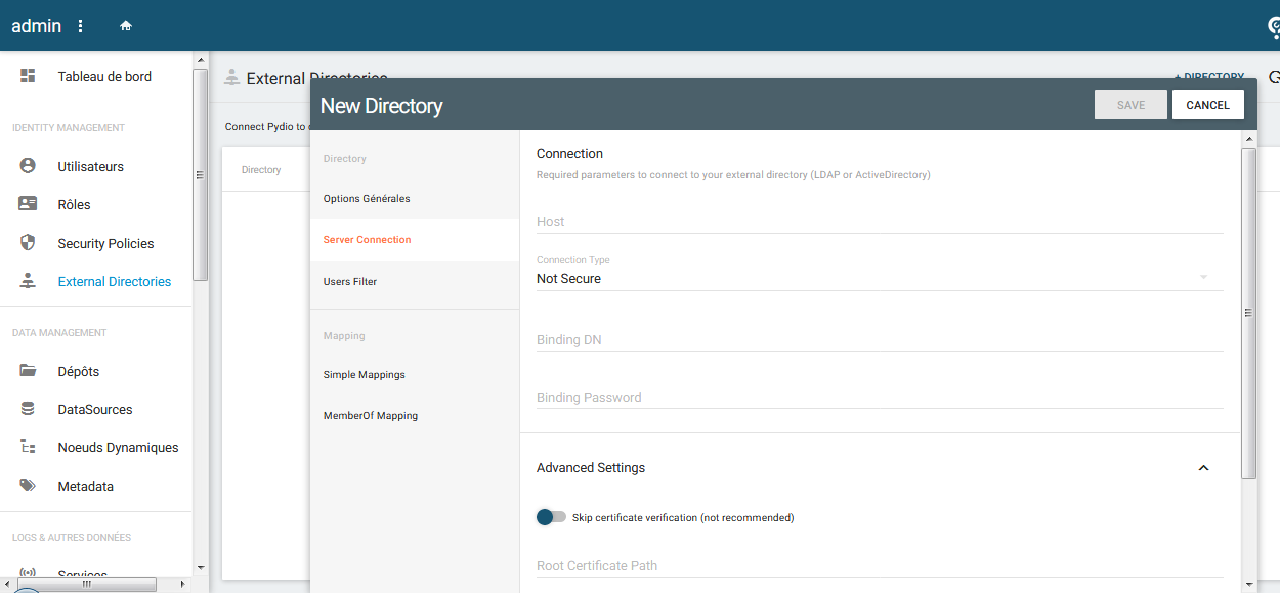
Pour plus d'informations, vous pouvez consulter la documentation officielle.
Autre menu supplémentaire : « Appearance ». À cet endroit, vous pourrez mettre votre logo et vos images de fond, fonction non disponible dans la version Community.
|
|
Ici, la page web a été dézoomée (50 %) pour permettre de voir le détail des réglages. La page web s'adapte à l’affichage (responsive).
7-4-6. Bilan▲
L'ancienne version Pydio 8.2.1 était plus souple et plus facile à installer que son successeur Pydio Cells, car écrit en PHP et s'appuyant sur des plugins faisant référence (tels que SabreDAV). Pydio Cells a un prérequis plus important.
Pas de fonction de connexion à un annuaire LDAP ou Active Directory dans la version Community, contrairement à Pydio 8.2.1. Pour ce type de connexion, il est nécessaire d'utiliser la version commerciale.
Pas de client de synchronisation pour le moment, celui-ci étant en cours de réécriture pour Cells, le client présenté précédemment correspond à celui de Pydio 8, la future version devrait lui ressembler.
La réussite de l'installation semble hasardeuse, celle-ci bloquant à la phase d'installation (peut-être dû au non-respect des prérequis minimums sur ma VM de test).
7-5. Solution maison▲
L'idée sera ici de synchroniser un dossier local avec un dossier distant avec une solution créée par moi-même.
Ceci sera implémenté par deux fonctionnalités différentes :
- la synchronisation d'une source avec une destination (bidirectionnelle ou non) ;
- le déclenchement de cette synchronisation lors d'une modification dans la source.
7-5-1. Linux▲
Pour synchroniser deux dossiers, la solution la plus simple sera d’utiliser rsync. L'utilisation de rsync sera faisable via une connexion SSH vers la destination. rsync permettant la synchronisation de deux dossiers « locaux », il sera possible de synchroniser vers n'importe quel type de partage tant que celui-ci peut être monté dans sur un point de montage de « / » et qu'il respecte les accès fichier POSIX.
Rappel : rsync fait une synchronisation en sens unique. Si vous avez besoin d'une synchronisation bi-directionnelle, vous pouvez utiliser Unison.
Nous pourrons ensuite surveiller les événements se passant sur le dossier source avec incron (Inotify cron).
Incron reprend le principe de fonctionnement de cron en reposant sur un fichier incrontab.
Voici un exemple d'entrée de surveillance pour le dossier /home/test :
/home/test/ IN_CREATE|IN_MODIFY rsync -avz [source] [destination]L'entrée précédente va par exemple déclencher rsync à chaque création ou modification de document.
7-5-2. Windows▲
Il existe une multitude d'applications permettant la synchronisation entre une source et une destination. Robocopy est une commande système puissante (sans interface graphique) avec beaucoup d'options. En l’utilisant de façon intelligente, notamment dans un script, vous pourrez effectuer des sauvegardes.
Exemple :
Robocopy.exe "c:\source" "d:\destination" /MIR /z /dcopy:T /XD "toto" /LOG+:"C:\MonRepertoireSource_2020-07-22.txt"Le dossier c:\source sera synchronisé avec le dossier destination. Explications des options :
- /MIR : équivalent à /e (copie des sous-répertoires) et /purge (supprime de la destination les fichiers et dossiers n'existant plus dans la source) ;
- /z : copie en mode redémarrable ;
- /dcopy : attributs de copie D=données,A=attributs, T=timestamp (DA par défaut) ;
- /xd : exclusion de dossier (/xf pour exclure un fichier) ;
- /log+ : nom du fichier de log (le + permet le mode ajout, sinon le fichier est remplacé s’il existe).
plus d'informations sur robocopy ici.
WinSCP permet de synchroniser un dossier local avec un dossier distant via SSH, et ceci de façon automatisée si vous le souhaitez. WinSCP est fourni avec une application en ligne de commande.
Il faudra à cela ajouter un système de contrôle des modifications dans le dossier source, par exemple Watch For Folder, un outil très léger et simple d'utilisation le fera très bien pour vous.
Ci-dessous une copie d'écran :
|
|
Une fois le profil créé, il ne faudra pas oublier de le démarrer en appuyant sur « Start », dans l’écran listant les profils. Écran que l’on obtient après avoir appuyé sur « Apply » :
|
|
Pour un aficionado de PowerShell, il ne devrait pas être compliqué de faire un équivalent simple (sans interface graphique par exemple) en quelques lignes de code.
Il existe des portages de la commande rsync sous Windows, comme deltacopy. Mais autant utiliser une commande native comme robocopy si vous n'avez pas besoin d'interface graphique.
7-5-3. Mac OS X▲
Mac OS X inclus rsync. Il existe, comme sur Windows (et quelques fois les mêmes que sous Windows), une multitude de logiciels de synchronisation.
Avec Automator, et une action dossiers, vous pourrez déclencher un événement lors de l'ajout d'un élément, mais Automator ne permet pas d'intercepter une modification ou une suppression de fichier.
Apple fournit une API « File System Event » permettant à une application d'être notifiée d'un changement dans un dossier. Cet API peut être utilisée avec fswatch, un outil cross-platform en ligne de commande (installable sous Mac OS X avec homebrew).
Tri-Backup, logiciel de sauvegarde faisant référence et payant, comporte une option de surveillance de dossier permettant de déclencher une action. Le but premier de tri-backup reste la sauvegarde incrémentale et le clonage de disque.
Hazel est un utilitaire payant permettant d'appliquer des critères à un dossier selon une règle définie, celui-ci n'a pas été testé.
8. Systèmes de fichiers distribués▲
Un système de fichiers distribué est un système ou le poste client accède à un espace de stockage virtuel unique. Les données peuvent être réparties/dupliqués sur plusieurs machines de façon transparente pour celui-ci. C'est le moteur du système de fichiers distribué qui a la charge de répartir les données et de les dispatcher au client.
Les systèmes de fichier distribués les plus répandus sont :
- CephCeph ;
- GlusterFSGlusterFS ;
- Hadoop Distributed File System (HDFS) ;
- Lustre (utilisé par les super-calculateurs) ;
- NFSNFS - Network File System.
Sur les tests effectués, il ressort deux approches :
- une approche en blocs (chunks) répartis sur plusieurs machines et pour lesquels les métadonnées peuvent être centralisées ou distribuées et permettent de reconstruire les fichiers ;
- une approche reposant sur la notion de fichiers et utilisant ou non des métadonnées. Certains nécessitent d'avoir une ou plusieurs machines dédiées aux métadonnées, d'autres permettant d'intégrer les métadonnées sur les machines stockant les données, ou éventuellement sur des machines autonomes.
Ceci a un impact sur le minimum de machines requis pour créer le système de fichiers distribués, sur la souplesse de retrait et d’ajout de machine, sur les performances, la maintenance et la sauvegarde.
Ce tutoriel couvre les systèmes de fichiers suivants :
- GlusterFS ;
- OCFS2 couplé à DRBD ;
- Ceph ;
- Minio.
En réalité, OCFS2 (Oracle Cluster File System) n'est pas un système de fichiers distribué, mais un système de fichiers gérant la concurrence d'accès aux fichiers entre plusieurs machines. Cela permet de gérer les accès concurrentiels, la répartition de charge sur plusieurs machines (deux dans notre cas) sera à gérer à part. C'est une approche intéressante pour un petit cloud.
Ceph, à son niveau le plus bas, va stocker des objets (des couples de clé/valeur). Un cache d'abstraction nommée RBD (Rados Block Device) fournira un accès en mode bloc. Par-dessus cela, CephFS fournira une abstraction permettant l'accès en mode fichier.
8-1. NFS▲
NFS n'est pas en lui-même un système de fichiers répartis. Du point de vue utilisateur, vous pouvez le comparer à SMB : c'est un point d'exposition d'un système plus bas niveau pouvant lui être réparti. Pourquoi en parler ici alors ? Car certains systèmes de fichiers répartis comme GlusterFS – que nous allons voir dans le prochain chapitre – implémentent directement un accès NFS.
NFS (Network file System) est un protocole historique de partage réseau sous Unix. Les anciennes versions n'étaient pas sécurisées.
Sur les anciennes versions de NFS, avec un serveur NFS installé, pour partager un dossier, il suffisait d'ajouter une entrée dans le fichier /,etc/exports comme ceci :
/dossier_partage 192.168.1.0/24(rw)pour permettre à toutes les machines du réseau 192.168.1.0 de se connecter au partage en lecture/écriture.
NFS fait un contrôle d'accès au niveau de l'hôte, pas du nom d'utilisateur.
L'accès client se fera soit par la commande mount, soit par une entrée dans le fichier /,etc/fstab comme ceci :
adresse_ip:/partage /point_de_montage nfs user,noauto 0 0La version 4 a créé une réelle rupture permettant :
- la sécurisation et le chiffrement des communications (support de Kerberos) ;
- délégation de la gestion d'un document en local pour un client ;
- Migration possible d'une machine à l'autre du serveur de façon transparent pour le client.
Les systèmes Linux, Mac OS, Windows (seulement la version Pro, pour les versions home, il faut utiliser un logiciel externe) intègrent nativement un client NFS.
Mac OS, Linux, la plupart des NAS intègrent un serveur NFS (bien qu'en général on va plutôt utiliser un partage SMB). Windows Server intègre également un rôle serveur NFS.
VMWare permet de stocker ses machines virtuelles dans un partage NFS, ce sera par contre moins efficace qu'avec le filesystem VMFS natif, mais permettra par contre de facilement créer un stockage partagé.
Un volume GlusterFS, que nous verrons dans le prochain chapitre peut être monté en NFS.
8-2. GlusterFS▲
GlusterFS est un système de fichiers distribué relativement souple. Il vient se greffer sur le système de fichiers local existant. Il permet de facilement « concaténer » plusieurs volumes locaux de plusieurs machines en un seul volume. Il possède plusieurs modes (distribués ou non) de fonctionnement. Certains d’entre eux permettent la redondance. C'est un système relativement simple à mettre en place et efficace. Voici une explication des modes de fonctionnement.
Mode répliqué
Ce mode de fonctionnement réplique les fichiers sur les différents nœuds du volume. Il s'agit là uniquement de l'aspect redondance, les fichiers ne sont pas répartis sur les différentes machines, ils sont répliqués.
|
|
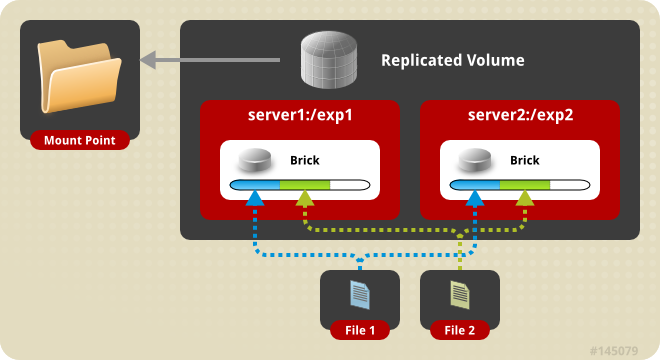
Mode distribué
Dans ce mode, les fichiers sont répartis entre les différentes machines du volume. Il n'y a pas de redondance. Vous devez donc vous assurer de la sauvegarde des données.
|
|
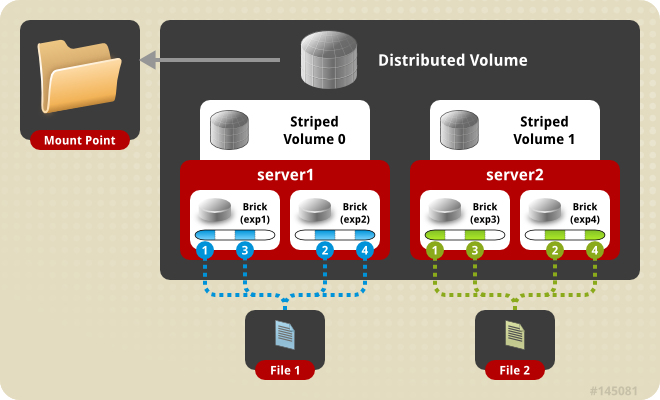
Mode distribué-répliqué
Ce mode cumule la répartition et la redondance. Chaque nœud du volume distribué est redondé sur une autre machine. Il vous faut donc au minimum X machines multiplié par 2 pour un volume consistant, X représentant le nombre de nœuds répartis.
Autres modes possibles
Volumes strippés : les fichiers sont éclatés en plusieurs morceaux, ceux-ci étant répartis sur les machines membres du volume. Ce mode pourrait être comparé à du RAID 0 via le réseau.
|
|
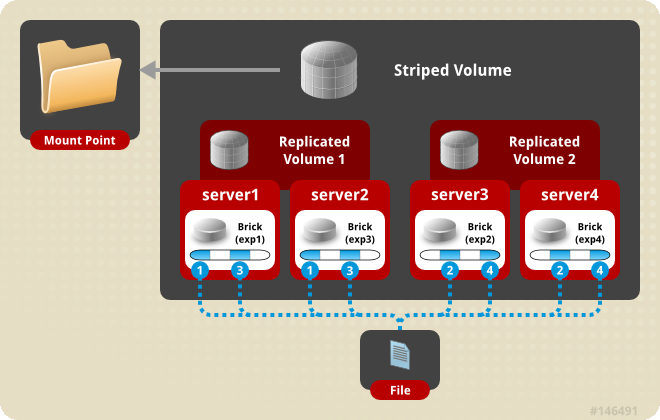
Volumes strippés distribués : les fichiers sont éclatés en plusieurs morceaux comme pour les volumes strippés, mais sont répliqués sur plusieurs machines. Ce mode peut être comparé à du RAID 0+1 (encapsulation de RAID 0 dans un RAID 1) via le réseau.
|
|
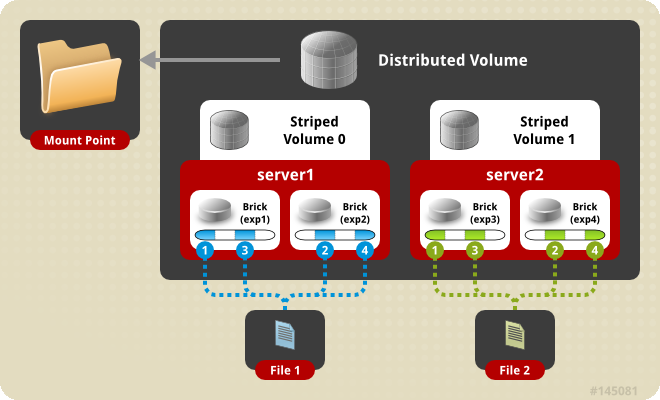
Volumes dispersés : les fichiers sont morcelés sur plusieurs machines avec des fragments supplémentaires permettant la reconstruction de fichiers suite à une perte de fragments présents sur une machine en panne. Ce fonctionnement est comparable à du RAID 5 via le réseau.
Volumes dispersés distribués : il s'agit de volumes distribués répliqués utilisant des sous-volumes dispersés plutôt que répliqués.
GlusterFS utilise la nomenclature suivante :
- pool de machines : machines qui sont appairées pour gérer un ou plusieurs volumes en commun ;
- brique : une brique est un point de stockage sur une machine d'un pool. Plusieurs briques font un volume.
8-2-1. Installation de GlusterFS▲
Pour créer un volume GlusterFS, il faut installer les paquets glusterfs-server et attr :
apt-get install glusterfs-server attrVotre système de fichiers doit supporter les attributs étendus. C'est le cas pour ext4.
8-2-2. Installation mode répliqué▲
Une fois les paquets GlusterFS installés sur srv1, nous créons un dossier à la racine que nous nommons srv1_data et qui accueillera le point de partage.
Nous créons ensuite le volume que nous nommerons VOL :
gluster volume create VOL srv1:/data_srv1 forceLa commande retourne l’indication suivante :
volume create: VOL: success: please start the volume to access dataOption force : GlusterFS exige ce paramètre au cas où le point de montage utilisé pour le volume est dans la partition principale (ce que GlusterFS ne recommande pas).
La commande gluster volume list permet l'affichage des volumes visibles sur le système :
root@srv1:~# gluster volume list
VOL
root@srv1:~#Nous pouvons voir l'état du volume avec la commande gluster volume info :
gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3fa199d1-7e7f-4ec5-985f-abf0f1f18ed4
Status: Created
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Options Reconfigured:
transport.address-family: inet
performance.readdir-ahead: on
nfs.disable: onNous pouvons voir que le volume est en mode distribué (distribute), avec une seule brique.
Une fois le volume créé, il nous faut l'activer :
root@srv1:~# gluster volume start VOL
volume start: VOL: success.À ce stade, le volume est montable, mais nous verrons cela dans le prochain chapitre.
Une fois les paquets installés sur srv2 et le dossier du point de montage créé, nous commençons par effectuer le jumelage GlusterFS de srv2 à srv1 depuis srv1 .
root@srv1:~# gluster peer probe srv2
peer probe : successLa commande suivante permet de voir les machines membres du pool :
root@srv1:~# gluster pool listEt qui donnera un résultat comme ceci :
root@srv1:~# gluster pool list
UUID Hostname State
bca2bdf3-ec7e-4e26-8d5e-01584b09d604 srv2 Connected
ffaa8716-0a58-4cea-b01d-70f49bcbe998 localhost ConnectedLes fichiers /,etc/hosts de chaque machine doivent contenir les noms des nœuds participant aux volumes GlusterFS.
La même commande exécutée sur la seconde machine donnera le même résultat, les deux lignes seront juste interverties.
Nous ajoutons ensuite la brique de srv2 au volume :
gluster volume add-brick VOL replica 2 srv2:/data_srv2 force
volume add-brick: successNous affichons les informations du volume :
gluster volume info
Volume Name: VOL
Type: Replicate
Volume ID: 3fa199d1-7e7f-4ec5-985f-abf0f1f18ed4
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv2:/data_srv2
Options Reconfigured:
nfs.disable: on
performance.readdir-ahead: on
transport.address-family: inetNous pouvons voir les deux briques et pouvons voir que le type de réplication est maintenant « replicate ».
Nous aurions pu également créer le volume comme ceci à partir du moment où Gluster était installé sur les deux postes et les deux machines jumelées :
root@srv1:~# gluster create volume VOL replica 2 srv1:/data_srv1 srv2:/data_srv1 force
volume create: VOL; success: please start volume to access dataVoici le détail des paramètres passés à la commande gluster create volume :
- VOL : nom du volume créé ;
- replica : nombre de machines nécessaires au volume répliqué (deux minimum) ;
- srv1:/data_srv1 : srv1 correspond au nom de la machine, /data_srv1 correspond au point de montage/dossier contenant les données du volume. Le nom de la machine et le chemin sont séparés par le caractère : ;
- srv2:/data_srv2: srv2 correspond au nom de la machine, /data_srv2 correspond au point de montage/dossier contenant les données du volume. Le nom de la machine et le chemin sont séparés par le caractère :.
Pour que la réplication fonctionne, il ne faut pas accéder au contenu directement depuis les dossiers /data_srv1 ou /data_srv2 dans notre exemple, mais depuis un point de montage GlusterFS.
8-2-2-1. Montage d'un volume gluster▲
Pour monter un volume gluster, vous aurez besoin du paquet glusterfs-client. Si vous souhaitez monter un volume gluster sur une machine faisant office de serveur gluster, vous n'en aurez pas besoin, le paquet glusterfs-client étant installé en même temps que glusterfs-server.
Le montage s’effectue de la même façon que pour tout autre type de volume :
# mount -t glusterfs [nom d'hôte ou adresse IP]:/[nom du volume] [point de montage]Ou dans le /etc/fstab sur srv1 par exemple :
srv1:/VOL /mnt glusterfs defaults,_netdev 0 0Il est possible de monter un volume gluster via NFS. Cela n'est pas recommandé, car la sécurité de NFS, notamment en troisième version est rudimentaire.
8-2-2-2. Ajout d'une machine supplémentaire au pool▲
Dans notre exemple, le serveur supplémentaire sera nommé srv3.
Lors de l’ajout d’une machine au pool, il ne faut pas oublier d’ajouter la nouvelle machine au fichier /,etc/hosts des machines déjà existantes ou s'assurer que l'entrée soit présente dans les DNS utilisés.
La commande suivante ajoute srv3 au pool :
root@srv1:~#gluster peer probe srv3Nous ajoutons ensuite la nouvelle machine :
gluster volume add-brick VOL replica 3 srv3:/data_srv3 forceIl faut passer le bon nombre de machines à l'option replica.
Si nous appelons la commande gluster volume info, nous pouvons constater que le nombre de briques est passé de 1 x 2 = 2 à 1 x 3 = 3.
8-2-2-2-1. Mise à jour de srv3▲
Une fois la brique intégrée, aucune donnée n'est automatiquement répliquée dessus. À ce stade, si nous ajoutons un nouveau fichier au volume, une copie sera bien présente dans srv3, mais les anciens fichiers ne le seront pas. Pour pallier ceci, il faut lancer la commande suivante :
gluster volume heal VOL full8-2-2-3. Retrait d'une brique▲
Dans notre cas, nous allons retirer srv2 avec la commande suivante :
gluster volume remove-brick VOL replica 2 srv2:/data_srv2 forceLa commande demande confirmation avant de procéder au retrait.
replica doit être égal au nombre final de briques après opération.
Dans notre cas où les volumes sont répliqués, il est possible de diminuer le nombre de volumes jusqu’à n’en garder plus qu’un. Le volume dans ce cas passera en mode distribué.
Le retrait de la brique du volume ne supprime pas les données de celle-ci, mais il n'y a plus aucun lien entre celles-ci et le volume. Il ne sera pas possible de réintégrer la brique telle quelle.
Si vous souhaitez retirer la machine du pool :
gluster peer detach srv28-2-3. Test de mise en panne, simulation perte de srv1▲
L'arrêt de srv1 ne provoque aucune erreur. Comme nous avons appairé srv2 à srv1, nous pouvons voir l'état de la connexion (et donc sa perte) avec la commande :
root@srv1:~# gluster peer status
Number of Peers: 1
Hostname: srv1
Uuid: c0c487b3-1135-41c7-b160-b8a061c10e9d
State: Peer in Cluster (Disconnected)Si vous souhaitez garder l'adresse IP de la machine perdue, la reconnexion est plus complexe.
8-2-3-1. Remplacement avec une nouvelle adresse IP▲
Nous appairons le nouveau serveur :
root@srv2:~# gluster peer probe srv1Nous remplaçons ensuite la brique :
root@srv2:~# gluster volume replace-brick VOL srv1:/data_srv1 [nouvelle ip/hote]/data commit forcePour que les machines se synchronisent, il faut ensuite lancer la commande :
gluster volume heal VOL full8-2-3-2. Remplacement en gardant la même adresse IP▲
Il faut d'abord retirer la brique défectueuse :
root@srv2:~# gluster volume remove-brick VOL srv1:/data_srv1 force
Removing brick(s) can result in data loss. Do you want to continue ? (y/n) y
volume remove brick commit force:successPuis :
root@srv2:~# gluster peer detach srv1
peer detach: successÀ ce stade, et comme déjà vu, le volume ne contenant plus qu'une seule brique, passe en mode distribué.
Une fois le nouveau serveur préparé, nous le réappairons :
root@srv2:~# gluster peer probe srv1Nous ajoutons la nouvelle brique :
root@srv2:~# gluster volume add-brick VOL replica2 srv1:/data_srv1 forceNous resynchronisons le volume :
gluster volume heal VOL full
Launching heal operation to perform full self heal on volume VOL has been successful
Use heal info commands to check statusComme indiqué, nous pouvons voir le résultat avec la commande :
gluster volume heal infoSi vous rencontrez des difficultés, consultez le chapitre 8.3.5.1Ajout d’une troisième machine pour la sauvegarde.
8-2-4. Installation en mode distribué▲
Certaines notions sont identiques ou de simples variantes du mode répliqué. Il est important pour la suite d'avoir lu le chapitre précédent.
Nous préparons une machine srv1 qui contiendra le fichier fichier1.txt dans /data_srv1.
Nous y créons un volume avec une brique unique.
gluster volume create VOL srv1:/data_srv1 force
volume create: VOL: success: please start volume to access dataNous pouvons voir l'état du volume avec la commande gluster volume info :
root@srv1:~# gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3f0a379a-921a-4c63-a5cc-7a62c3c39d19
Status: Created
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1Nous pouvons constater que le volume est en mode distribué (distribute)
Démarrons ensuite le volume :
root@srv1:~# gluster volume start VOLNous préparons ensuite un serveur srv2 avec le fichier /data_srv2/fichier2.txt. Il nous faut appairer la nouvelle machine :
root@srv1:~# gluster peer probe srv2Puis ajouter la nouvelle brique :
root@srv1:~# gluster volume add-brick VOL srv2:/data_srv2
volume add-brick: successNous pouvons voir le nouvel état du volume :
root@srv1:~# gluster volume info
Volume Name: VOL
Type: Distribute
Volume ID: 3f0a379a-921a-4c63-a5cc-7a62c3c39d19
Status: Started
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv2:/data_srv2Si nous montons le volume, nous pourrons voir les deux fichiers fichier1.txt et fichier2.txt. L'arrêt d'une des deux machines fera disparaître les fichiers présents dans le nœud coupé. Le premier accès sera lent, gluster cherchant la machine manquante. Le volume continue de fonctionner, il reste possible d'ajouter des fichiers. Le redémarrage de la machine manquante fera instantanément réapparaître les fichiers inaccessibles.
Créez quelques fichiers pour tester le comportement. J'ai créé plusieurs fichiers nommés fichier3.txt, fichier4.txt, etc. Tous restant dans /data-srv1.
Gluster gère cela lui-même et du point de vue extérieur, cela n'a pas d'importance pour l'accès. Lisez cette partie de la documentation pour plus d'informations.
Il est possible de changer la répartition avec la commande rebalance :
gluster volume rebalance VOL startSelon le volume de données à traiter, la répartition peut prendre du temps. Il est possible de voir l'état de celle-ci via la commande :
gluster volume rebalance VOL statusJ'ai pu constater que certains fichiers apparaissent en doublon dans les dossiers contenant les briques, ceux-ci restant uniques dans le point de montage GlusterFS. Je présume que gluster est suffisamment intelligent pour les conserver tant qu'il y a de la place.
Rappel : si vous insérez un fichier dans un dossier faisant partie d'un volume gluster sans passer par le point de montage gluster, celui-ci n’apparaîtra pas dans le volume et ne sera ni répliqué, ni distribué.
8-2-5. Test du mode distribué-répliqué▲
Pour ce mode, je vais repartir sur la configuration précédente : deux machines en mode distribué que je vais passer en mode distribué-répliqué.
Je vais rajouter deux machines supplémentaires aux deux machines déjà présentes de façon à ce que chacune soit répliquée.
Une fois les deux serveurs supplémentaires préparés et appairés, je les intègre au volume :
gluster peer probe srv3
gluster peer probe srv4gluster volume add-brick VOL replica 2 srv3:/data_srv3 srv4:/data_srv4 forceNous obtenons le résultat suivant :
Volume Name: VOL
Type: Distributed-Replicate
Volume ID: 8f4d1305-7f28-41eb-bc76-85132c009c51
Status: Started
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: srv1:/data_srv1
Brick2: srv3:/data_srv3
Brick3: srv2:/data_srv2
Brick4: srv4:/data_srv4L'ajout d'un fichier dans le point de montage du volume GlusterFS, point de montage depuis srv1 et donc création du fichier depuis srv1 va générer l'ajout de celui-ci dans /data_srv2 et /data_srv4. Nous avons donc bien la réplication ainsi que la distribution répartie.
Seuls les nouveaux fichiers ou fichiers modifiés après l'ajout des briques bénéficieront de la réplication.
Pour que tous les fichiers soient répliqués, il faudra exécuter la commande rebalance comme vu précédemment.
gluster volume rebalance VOL startLa répartition devient donc :
- srv1 : fichier1.txt, fichier2.txt ;
- srv2 : fichier2.txt, fichier3.txt ;
- srv3 : fichier2.txt ;
- srv4 : fichier2.txt, fichier3.txt ;
Chaque fichier est donc bien répliqué.
8-2-5-1. Simulation de perte de srv2▲
La manipulation la plus simple est de préparer une nouvelle machine, de lui affecter une nouvelle adresse IP, de l'appairer et d'utiliser replace-brick comme vu précédemment.
Si vous souhaitez garder la même IP, il va falloir effectuer plusieurs opérations.
La difficulté ici est qu'un nouveau serveur n'aura pas le même UUID. Il y aura donc des manipulations supplémentaires à effectuer une fois le serveur préparé.
Il va nous falloir récupérer l'ancien UUID de srv2 :
root@srv1:~# grep -r uuid= /var/lib/glusterd/peers/* >fichier.txtUniquement valable si votre dossier ne contient qu'un seul fichier /var/lib/glusterd/peers/. Si ce n'est pas le cas, il faut identifier celui-ci et exécuter :
grep uuid= /var/lib/glusterd/peers/[nom du fichier contenant hostname=srv1] >fichier.txt
Nous transférerons ensuite cet UUID sur le nouvel srv2. Nous insérons ensuite cet UUID dans /var/lib/glusterd/glustered :
cat fichier.txt >>/var/lib/glusterd/glusterd.infoNous éditons le fichier afin de fixer l'UUID, puis redémarrons le service :
/etc/init.d/glusterfs-server restartNous appairons ensuite le serveur :
root@srv2:~# gluster peer probe srv1Nous redémarrons le service en appelant la commande gluster pool list, vous verrez les deux machines connectées.
Il faut ensuite synchroniser les volumes.
Depuis srv2, la commande gluster volume status vous retournera :
No volumes presentNous synchronisons les volumes avec la commande ;
root@srv1:~# gluster volume sync srv2 all
sync volume may data inaccessible while the sync is in progress. Do you want to continue ? (y/n)
volume sync success.À ce stade, les données ne sont pas encore synchronisées.
Mises à jour des métadonnées
Il va nous falloir mettre à jour les métadonnées sur le nouveau serveur depuis un serveur actif.
root@srv1:~# getfattr -n trusted.glusterfs.volume-id /data_srv1
getfattr:suppression des « / »en tête des chemins absolus
# file: data_srv2/
trusted.glusterfs.volume-id=0s8VVsv3xRTa6G41mE+5E1dA==Il va falloir appliquer le volume id sur srv2 avec la commande :
setfattr -n trusted.glusterfs.volume-id -v '0s8VVsv3xRTa6G41mE+5E1dA==' /data_srv2Nous redémarrons ensuite le service et depuis srv1, nous exécutons :
gluster volume heal VOL full8-2-6. Sauvegarder/restaurer▲
Il me parait indispensable d'avoir une sauvegarde hors ligne même en cas de système répliqué, ceci afin de se protéger de cryptolocker ou d’un effacement involontaire de fichiers. L'idéal sera une sauvegarde en ligne sur la même infrastructure, afin d'avoir une sauvegarde/restauration régulière rapide, doublé par une sauvegarde hors ligne moins fréquente.
8-2-7. Sécurité▲
Les serveurs faisant partie d'un pool gluster, ils se reconnaissent via leur UUID. Pour qu'un serveur fasse partie d'un pool, il doit être intégré par un serveur du pool (c'est la commande gluster peer probe que nous avons déjà vue).
Par défaut, n'importe quel client peut se connecter à un volume gluster. Il est possible de restreindre l'accès à certaines IP via la commande :
gluster volume set VOL auth.allow [adresse IP 1],[adresse IP 2]Par défaut, le dialogue s'effectue en clair. Il est possible d'établir un dialogue SSL/TLS (documentation ici), celui-ci gérant l'authentification et le cryptage, mais pas l'autorisation. La sécurisation peut bien sûr se faire via un tunnel VPN, l'authentification et le cryptage étant alors délégué au tunnel VPN.
Comme il n'y a pas de login/mot de passe, il ne faut pas exposer directement un point de montage gluster aux utilisateurs. Par exemple, ce point de montage peut-être partagé en SMB. C'est le serveur SMB (point d'entrée exposé) qui s’occupera alors des autorisations d'accès.
8-3. DRBD/OCFS2▲
Nous allons ici cumuler l'utilisation de DRBD avec OCFS, DRBD s'occupant de la réplication, OCFS de l'accès concurrentiel.
8-3-1. DRBD▲
8-3-1-1. Qu'est-ce que DRBD ?▲
DRBD : Distributed Replicated Block Device permet la réplication de périphériques bloc entre serveurs via le réseau. Il peut être assimilé à du RAID 1 over IP.
|
|
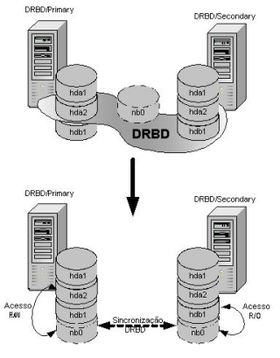
Par défaut, DRBD utilise la notion de primaire/secondaire. Un système de fichiers ne peut être monté que depuis une machine primaire. La machine primaire transmet les modifications à la machine secondaire. Une machine en mode secondaire ne peut pas être utilisée de façon à garder la cohérence du cache.
Nous utiliserons un mode permettant d'avoir deux machines primaires et donc pouvoir faire des lectures/écritures depuis les deux nœuds.
8-3-2. Installation de DRBD▲
La version utilisée ici sera la version 8.
L'installation se fait simplement par :
apt-get install drbd-utilsIl va falloir effectuer la configuration du nœud primaire et du nœud secondaire. Nous devons donc préparer un fichier de configuration en conséquence.
DRBD va utiliser une partition en tant que périphérique bloc sur chaque nœud.
Une partition doit être mise à disposition. Utiliser une partition avec DRBD va écraser son contenu.
Le fichier de configuration suivant, nommé r0.res et placé dans /,etc/drbd.d permet d’utiliser les nœuds accessibles en 192.168.8.1 et 192.168.8.2. Sur chacun d'eux, nous utiliserons la partition /dev/sdb1. Ce fichier sera à adapter à votre cas.
resource r0 {
syncer {
rate 100M;
}
on srv1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.1:7789;
meta-disk internal;
}
on srv2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.2:7789;
meta-disk internal;
}
}Un fichier de définition de ressource DRBD doit avoir l'extension .res
Les noms de machines utilisés avec la directive « on »
doivent correspondre aux noms des machines retournés par la commande hostname.
Ce fichier devra être recopié sur le second nœud.
Le fichier est relativement simple à comprendre. Nous créons un volume DRBD accessible depuis /dev/drbd0 sur chaque nœud.
Nous créons ensuite le volume sur le nœud primaire :
# drbdadm create-md r0
initialising activiy log
NOT initialializing bitrmap
Writing meta data …
New dbrd meta data block successfully created.Nous activons ensuite celui-ci :
# drbdadm up r0Nous pouvons observer le résultat avec la commande drbd-overview :
# drbd-overview
0:r0/0 WFConnexion Secondary/Unknown Inconsistent/DUnknownIl faut effectuer ces commandes sur les deux nœuds. Pour le second nœud, la commande drbd-overview donne :
0:r0/0 Connected Secondary/Primary Inconsistent/ InconsistentNous voyons que la connexion est effectuée, mais que le « RAID » DRBD est inconsistant.
Nous lançons ensuite la synchronisation uniquement depuis le poste maitre (192.168.8.1 ou srv1), nous passons également le nœud en primaire :
drbdadm -- --overwrite-data-of-peer primary r0Nous pouvons voir l'évolution de la synchronisation depuis le fichier /proc/drbd ou depuis la commande drbd-overview :
version: 8.4.3 (api:1/proto:86-101)
srcversion: 6681A7B41C129CD2CE0624F
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:417288 nr:0 dw:0 dr:418200 al:0 bm:25 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:7970004
[>...................] sync'ed: 5.1% (7780/8188)Mfinish: 0:05:05 speed: 26,080 (26,080) K/secUne fois la synchronisation terminée, nous allons passer le second nœud en primaire. Pour cela, nous ajoutons les lignes suivantes dans le bloc ressources du fichier de configuration r0 :
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
}
startup {
become-primary-on both;
}Le fichier devient :
resource r0 {
syncer {
rate 100M;
}
net {
allow-two-primaries yes;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
}
startup {
become-primary-on both;
}
on srv1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.1:7789:
meta-disk internal;
}
on srv2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.8.2:7789:
meta-disk internal;
}
}En détails, voici les nouvelles fonctions utilisées :
- allow-two-primaries : permet d'utiliser deux nœuds en mode primaire ;
- after-sb-0pri discard-zero-changes : en cas de split-brain, et que les deux nœuds sont considérés comme primaires, DRBD va prendre les modifications les plus récentes et les appliquer à l'autre nœud ;
- after-sb-1pri discard-secondary : en cas de split-brain avec un nœud primaire et un secondaire, le primaire écrasera les modifications sur le secondaire ;
- after-sb-2pri disconnect (non utilisé) : en cas de split-brain, DRBD déconnecte les volumes et le réglage du problème (et la décision du nœud où il faut sacrifier les différences) doit être fait manuellement.
Pensez à faire une copie du fichier de configuration avant modification pour pouvoir revenir à la situation initiale en cas de problème.
Nous recopions le fichier sur le second nœud et redémarrons le service DRBD sur les deux machines.
Nous pouvons vérifier l'état sur les deux serveurs avec :
# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
srcversion: 1A9F77B1CA5FF92235C2213
0: cs:Connected ro:Primary/Primary ds:UpToDate/Diskless C r-----
ns:912 nr:0 dw:0 dr:1824 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:8387292Rappel : Il n'est pas possible de monter un système de fichiers dans un volume DRBD en mode secondaire.
8-3-2-1. Sécurité de DRBD▲
Il est possible de sécuriser les dialogues DRBD en ajoutant les éléments suivant dans le fichier de configuration :
net {
cram-hmac-alg "sha1";
secret "le mot de passe";
}Un transfert via une connexion sécurisée entre les nœuds hors DRBD peut aussi être utilisé. (interconnexion via cartes réseau dédiées hors réseau normal, VPN).
8-3-2-2. Surveillance des volumes DRBD▲
DRBD est fourni avec un système de handlers et des scripts pour gérer les problèmes. Par exemple, la mise en place d’une notification par mail lors d’un split-brain s’effectue en ajoutant ce qui suit dans la section resources :
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh <adresse>";
...
}Je vous invite à regarder les différents scripts à disposition dans /usr/lib/drbd.
8-3-2-3. Tests▲
Une fois la synchronisation effectuée, nous créons ensuite un système de fichiers sur /dev/drbd0 :
mkfs.ext4 /dev/drbd0Quelle que soit la machine, le système de fichiers sera présent sur l'autre, le volume DRBD étant répliqué.
Nous y créons un fichier de test fichier1.txt après montage du volume DRBD dans un point de montage.
Nous montons ensuite /dev/drbd0 sur la seconde machine (srv2), nous voyons bien le fichier fichier1.txt.
Nous ajoutons un fichier fichier2.txt depuis srv2, celui-ci n’apparaît pas sur srv1.
Nous démontons et remontons le volume sur srv1, Après remontage, nous voyons bien le second fichier.
Explications
DRBD travaille au niveau bloc et non au niveau du système de fichiers. Nous pouvons l'utiliser tel quel en tant que sauvegarde, mais pas pour un double montage. Le monter simultanément risque de provoquer une inconsistance au niveau du système de fichiers.
Pour pallier ceci, nous allons utiliser OCFS2, un système de fichiers permettant les accès concurrents.
8-3-3. OCFS2▲
8-3-3-1. Qu'est-ce qu'OCFS2 ?▲
OCFS2 (Oracle Cluster File System) est un système de fichiers sous licence GPL qui permet l'accès concurrent à des fichiers, c'est-à-dire un accès simultané possible en lecture/écriture à un fichier sans risque d’inconsistance. Ceci nous permettra de résoudre le problème vu dans le chapitre précédent.
8-3-3-2. Installation et paramétrage d'OCFS2▲
Pour installer OCFS2, il faut installer le paquet comme ci-dessous :
apt-get install ocfs2-toolsNous créons le système de fichiers ocfs sur le volume DRBD :
mkfs -t ocfs2 -L MYCLOUD /dev/drbd0Avec en options :
- -L : le nom du volume OCFS2.
La configuration s'effectue via les commandes suivantes.
Création du cluster que nous nommerons « MYCLOUD » :
o2cb add-cluster MYCLOUDAjout des nœuds :
o2cb add-node MYCLOUD --ip 192.168.8.1 --port 7777 --number 0 srv1
o2cb add-node MYCLOUD --ip 192.168.8.2 --port 7777 --number 1 srv2Ce qui nous donnera La configuration suivante dans le fichier /etc/ocfs2/cluster.conf :
cluster:
heartbeat_mode = local
node_count = 2
name = MYCLOUD
node:
number = 0
cluster = MYCLOUD
ip_port = 7777
ip_address = 192.168.8.1
name = srv1
node:
number = 1
cluster = MYCLOUD
ip_port = 7777
ip_address = 192.168.8.2
name = srv2Afin de modifier la configuration au démarrage, nous lançons :
dpkg-reconfigure ocfs2-tools|
|
|
|
Après un redémarrage de la machine, ou plus simplement des services o2cb et ocfs2, il suffit de monter le volume :
mount -t ocfs2 /dev/drbd0 /dataou grâce au fichier fstab :
/dev/drbd0 /data ocfs2 _netdev 0 0Pour avoir accès aux données sur la seconde machine, il faudra effectuer les mêmes opérations après voir copié le fichier de configuration /etc/ocfs2/cluster.conf.
Les tests depuis les deux postes sont fonctionnels. Le fichier fichier1.txt créé depuis srv1 est visible sur srv2, et le fichier fichier2.txt créé depuis srv2 est visible dans le dossier /data de srv1.
Le montage automatique au redémarrage ne semble pas fonctionnel. Peut-être un problème de configuration.
8-3-4. Couplage DRBD/OCFS2 : Simulation de panne▲
Pour simuler notre panne, nous allons arrêter srv2. Après quelques secondes, l’erreur suivante apparaît sur la console de srv1 :
drbd r0: PingAck did not arrive in timeDe plus, la commande drbd-overview retournera un message similaire à :
0:r0/0 WFConnection Primary/Unknown UpToDate/DUnknown /data ocfs2 8.0G 151M 7.9G 2%Le premier accès à la commande drbd-overview va être long.
L'arrêt de srv2 ne perturbe pas le volume /data dans srv1, sauf si celui-ci est redémarré.
Au redémarrage de srv2, j'ai le message suivant dans la console :
A start job is running for dev-drbd0.device (36s/1mn 30s)Comme nous l'avons déjà vu, nous ne pouvons pas monter un volume DRBD en mode Secondary. Le volume OCFS2 n'est pas montable. Une tentative de montage avec mount -a donnera le message suivant :
mount.ocfs2: Device name specified was not found while opening device /dev/drbd0Une fois le système démarré, le volume n'est pas disponible. En exécutant la commande drbd-overview, nous pouvons voir :
0:r0/0 Unconfigured . .La commande :
drbdadm up r0Nous retournera :
Marked additional 12 MB as out-of-sync based on AL.Et le rappel de drbd-overview nous donnera :
0:r0/0 Connected Secondary/Primary UpToDate/UpToDateJe redémarre DRBD sur les deux postes avec la commande service drbd restart.
Les deux postes repassent en mode Primary.
Il est alors possible de remonter le volume OCFS2 sur srv2 avec la commande mount -a (et sur srv1).
Nous avons donc une méthode pour redémarrer en mode dégradé.
8-3-5. Couplage DRBD/OCFS2 : redémarrage des deux serveurs▲
Le redémarrage des deux serveurs simultanément nous donnera une situation de split-brain. La commande drbd-overview nous donnera « Unconfigured » sur les deux postes.
Pour avoir accès au volume sur un des postes, il faudra lancer les commandes suivantes :
- drbdadm up r0 ;
- drbdadm primary r0 ;
- mount -a.
Sur le second poste : - drbdadm up r0.
À ce stade, le volume DRBD sera consistant avec le mode Primary sur le premier poste, et le mode Secondary sur le second. Un mount -a sur le second nœud réactivera le volume OCFS2.
En cas de perte complète d'un nœud (et non plus un simple arrêt), le volume sera indisponible sur le second nœud tant que la synchronisation n'a pas été refaite. Une fois celle-ci refaite, il sera possible de passer le nœud en Primary et ensuite de monter le volume OCFS2.
8-3-5-1. Ajout d’une troisième machine pour la sauvegarde▲
La version 9 de DRBD permet d’avoir jusqu'à 16 machines. Ce chapitre repose sur la version 8.4 et permet d'empiler deux volumes DRBD. Ce système est appelé stacked et correspond à cette architecture :
|
|
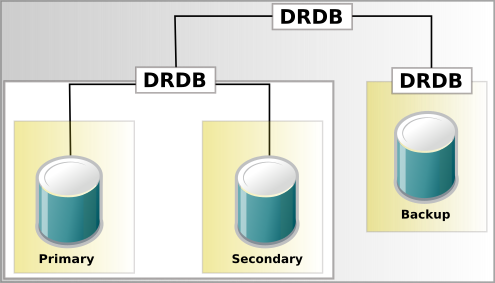
Nous allons donc mettre en place un serveur srv3 comme serveur de sauvegarde.
Nous ajoutons la nouvelle ressource imbriquée dans /etc/drbd.d/r0.res à la suite de r0 :
resource r1 {
stacked-on-top-of r0 {
device /dev/drbd10;
address 192.168.8.4:7788;
}
on srv3 {
device /dev/drbd10;
disk /dev/sdb1;
address 192.168.1.3:7788;
meta-disk internal;
}
}Vous remarquerez que nous utilisons un port différent, chaque ressource dialoguant sur son propre port.
Nous démontons ensuite le volume sur les deux machines. La commande drbd-overview vous permet de voir si le volume est monté :
0:0/r0 Connected Primary/Primary UpToDate/ UpToDate /data ocfs2 63M 13m 51m 20%
10:r1/0 ^^0 Unconfigured .Voici le retour lorsque le volume est démonté :
0:0/r0 Connected Primary/Primary UpToDate/ UpToDate 11-dev of: 10 r1/0
10:r1/0 ^^0 Unconfigured .Nous pouvons voir que le volume r1 n'est pas configuré.
Pour cela il nous faut exécuter les commandes :
drbdadm --stacked create-md r1
md_offset 66015232
al_offset 65982464
bm_offset 65978368
Found some data
==> This might destroy existing data! <==
Do you want to proceeed?
[need to type 'yes' to confirm]Il faudra confirmer en tapant « yes », puis vous aurez un message de ce type en retour :
Initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfull created.Nous tapons ensuite la commande :
drbdadm --stacked up r1À ce stade, il n'est pas possible de monter le volume.
Comme précisé par le message lors de la commande, effectuer ceci sur un volume existant peut provoquer une perte de données.
Nous copions ensuite la configuration sur srv3, puis créons le volume DRBD dessus :
root@srv3:~# drbdadm create-md r1
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.Puis :
drbdadm up r1Nous invalidons ensuite le contenu de la machine par :
drbdadm invalidate r1La synchronisation de srv3 se déclenche immédiatement.
Nous activons le mode primaire sur srv1 :
root@srv3:~# drbdadm –stacked primary r1il faut ensuite monter le volume avec /dev/drbd10 au lieu de /dev/drbd0.
/dev/drbd10 sera le nom de device utilisé pour un volume stacked.
En cas de perte d'une des machines, il faudra appliquer la méthode vue au chapitre 8.3.5.1Ajout d’une troisième machine pour la sauvegarde.
8-3-5-2. Perte de liaison entre deux machines : split-brain▲
Si les deux machines croient que l'autre ne fonctionne plus, vous vous trouverez dans une situation nommée split brain. Dans cette situation, les deux machines passeront en mode standalone avec le statut inconnu :
0:r0/0 StandAlone Primary/Unknown /data ocfs2 127M 17M 1111M 14%Pour régler ce problème, vous devrez en considérer une comme « sacrifiable » et la resynchroniser entièrement à partir de l'autre. Si la situation a perduré un moment, et qu'il y a des différences entre les deux, les différences de la machine sacrifiée seront perdues.
Nous commençons par effectuer un redémarrage des deux machines. À ce stade aucune des deux ne devrait être connectée au volume OCFS2.
Vous pouvez voir un peu plus haut que la commande drbd-overview indique des informations sur le volume monté.
Nous pouvons voir que le volume est monté dans /data. Si aucun volume n'est monté, vous ne verrez que l'information Primary/Unknown (ou Secundary/Unknown).
Nous allons basculer la machine « victime » en secondaire si nécessaire.
Avant ce redémarrage, nous commentons dans le fichier /etc/drbd.d/r0 les lignes concernant la gestion du double primaire.
Après redémarrage. Avec drbd-overview, vous devriez avoir quelque chose comme :
0:r0/0 WFConnection Secondary/Unknown UpToDate/UnknownNous allons ensuite déclarer une des machines comme obsolète, commande à effectuer sur la machine concernée :
drbdadm – --discard-my-data connect r0La resynchronisation se déclenche. Pendant celle-ci, vous pouvez basculer la machine servant de source en primaire et remonter le volume OCFS.
Une fois la synchronisation terminée, nous décommentons les lignes concernant l'utilisation de deux machines primaires et redémarrons le service sur les machines une à une.
8-3-6. DRBD 9▲
DRBD 9 permet d'utiliser LVM comme conteneur de volume. Il permet aussi d'avoir jusqu'à 16 nœuds par ressource sans devoir recourir à l'empilement comme vu avec la version 8.4. La version fournie avec Debian 9 étant la 8,4, il va falloir compiler :
- le module noyau ;
- les outils drbd (drbd-utils).
Avant de commencer, nous installerons LVM (apt-get install lvm2).
8-3-6-1. Installation du module noyau :▲
Commençons par télécharger les sources du module :
wget https://www.linbit.com/downloads/drbd/9.0/drbd-9.0.19-1.tar.gzJe n'ai pas pris la dernière version pour des questions de soucis de compilation sur Debian 9 utilisé (Debian 9 étant une ancienne version maintenant).
Les liens de téléchargements peuvent changer avec le temps et devront donc être adaptés
Décompression :
gunzip drbd-9.0.19-1.tar.gzDésarchivage :
tar -xvf drbd-9.0.19-1.tarLa compilation se fera avec la commande make dans le dossier décompressé. Les prérequis sont make bien sûr, et les en-têtes de votre noyau (installable avec la commande apt-get install linux-headers-$(uname -r)).
Une fois la compilation effectuée, l'installation se fera par :
make install8-3-6-2. Installation des outils ▲
wget https://www.linbit.com/downloads/drbd/utils/drbd-utils-9.13.1.tar.gz
gunzip drbd-utils-9.13.1.tar.gz
tar -xvf drbd-utils-9.13.1.tarLes prérequis avant compilation seront gcc, flex, xlstproc (pour la documentation). La compilation se fera ensuite par :
./configure
makeÀ la fin de la compilation, j'ai eu le message d'erreur suivant :
Makefile:108 : la recette pour la cible « doc » a échouéCela n’empêche pas le make install.
Nous faisons ensuite l'installation :
make install8-3-6-3. Préparation du volume LVM▲
Nous commençons par préparer la partition à l'usage de LVM (dans notre cas sdb1) :
pvcreate /dev/sdb1Nous créons ensuite un volume Group que nous appellerons vg01 :
vgcreate vg01 /dev/sdb1Et créons enfin le volume logique lv01 (volume de 1900 Mo sur un disque de 2 Go pour l'essai) :
lvcreate -L 1900 -n lv01 vg01Nous créons ensuite un fichier de configuration dans un premier temps avec une machine unique :
resource r0 {
protocol C;
on srv1 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.201:7789;
meta-disk internal;
node-id 0;
}
}Comme nous utilisons une version compilée de DRBD, les fichiers de configuration devront être placés dans /usr/local/,etc/drbd.d au lieu de /,etc/drbd.d.
Remarquez la présence de l'option node-id 0;. Cette option, apparue avec DRBD 9 permet de numéroter chaque nœud participant au cluster.
La procédure sera ensuite la même que pour la version 8.4.
Création des métadonnées sur le volume :
drbdadm create-md r0Activation du volume :
drbdadm up r0À ce stade, nous pouvons voir l'état du volume avec la commande drbdadm status, qui remplace drbd-overview :
~# drbdadm status
r0 role:Secondary
disk:InconsistentNous allons ensuite passer celui-ci en primaire. La syntaxe a été simplifiée par rapport aux versions précédentes :
drbdadm primary r0 --forceRésultat de drbdadm status :
# drbdadm status
r0 role:Primary
disk:UpToDateNous modifions le fichier de configuration pour intégrer la seconde machine :
resource r0 {
protocol C;
on srv1 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.201:7789;
meta-disk internal;
node-id 0;
}
on srv2 {
disk /dev/vg01/lv01;
device /dev/drbd0;
address 192.168.1.202:7789;
meta-disk internal;
node-id 1;
}
}Rappel : la valeur node-id doit être unique à chaque nœud.
Une fois le fichier mis à jour, la commande suivante permet de prendre en compte les changements :
drbdadm adjust r0La commande drbdadm status nous montre l'attente de connexion pour srv2 non encore préparé.
~# drbdadm status
r0 role:Primary
disk:UpToDate
srv2 connection:ConnectingReste à préparer srv2. La copie des dossiers source depuis srv1 permettra d'installer le module noyau DRBD avec make install sans devoir recompiler (le module .ko compilé sur srv1 étant dans le dossier des sources copié). Pour les outils, il faudra réexecuter ./configure, puis make et make install. Restera à copier le fichier de configuration.
Une fois le volume LVM créé, les métadonnées DRBD créées (avec drbdadm create-md r0), le lancement de la commande drbdadm up r0 déclenchera la synchronisation. Ci-dessous la synchronisation en cours :
~# drbdadm status
r0 role:Primary
disk:UpToDate
srv2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:43.03Une fois les volumes synchronisés, passer srv2 en primaire ne posera pas de difficultés.
8-3-6-4. Intégration troisième poste▲
Bien que cela soit possible, je n'ai pas réussi à intégrer un troisième poste sans erreur. La documentation manque de précision.
8-3-6-5. drbdmanage▲
drbdmanage est un utilitaire simplifiant la gestion de DRBD. drbdmanage est déprécié et remplacé par linstor. Celui-ci étant toujours disponible sur github, j'ai décidé d'en faire une présentation.
Nous commençons par récupérer les sources :
git clone https://github.com/LINBIT/drbdmanage.gitPrérequis : python-dbus, python-gobject.
Une fois entre dans le dossier, l'installation se fera par :
./setup.py installLa commande drbdmanage sera alors disponible.
drbdmanage attend par défaut la présence d'un volume group LVM nommé drbdpool. Si vous souhaitez définir un nom différent décommentez la ligne drbdctrl-vg dans le fichier /etc/drbdmanage.cfg et mettez-y la valeur de notre choix, dans l'exemple suivant le volume group utilisé s’appellera « drbd », créée dans la partition /dev/sdb1 comme ceci :
~# pvcreate /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
~# vgcreate drbd /dev/sdb1
Volume group "/dev/sdb1" successfully created.Avant de créer le cluster, comme drbdmanage a été installé par les sources, pour éviter un message d'erreur dbus, il faut créer le lien symbolique suivant :
ln -s /usr/local/bin/dbus-drbdmanage-service /usr/binCes opérations préliminaires seront à effectuer sur les deux machines minimales qui seront mises en place.
Nous créons une liaison SSH par clé entre les deux serveurs :
root@srv1 ~# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/cloud/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/cloud/.ssh/id_rsa.
Your public key has been saved in /home/cloud/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:RgvrHWfPnz6PiniTRaTL0AFHFoR6xWp/cRZb6Q1RJc8 cloud@Debian
The key's randomart image is:
+---[RSA 2048]----+
| .**. oo=|
| .o+ . o=.|
| ...+ + .=E|
| .+=.o o +..|
| .oS+oo + |
| . o ++oo |
| . . +o |
| .+. ..o |
| .....o=o.|
+----[SHA256]-----+
root@srv1 ~# ssh-copy-id root@192.168.1.202
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cloud/.ssh/id_rsa.pub"
The authenticity of host 'srv1 (192.168.1.201)' can't be established.
ECDSA key fingerprint is SHA256:LLALxAyQlZLXlVtPSyTrOkUaTKKC+C0UCDAQKrWTuMI.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@srv1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'cloud@srv1.local'"
and check to make sure that only the key(s) you wanted were added.Nous initialisons ensuite le cluster :
drbdmanage init 192.168.1.201Qui nous retournera :
You are going to initialize a new drbdmanage cluster.
CAUTION! Note that:
* Any previous drbdmanage cluster information may be removed
* Any remaining resources managed by a previous drbdmanage installation
that still exist on this system will no longer be managed by drbdmanage
Confirm:
yes/no: yes
Empty drbdmanage control volume initialized on '/dev/drbd0'.
Empty drbdmanage control volume initialized on '/dev/drbd1'.
Waiting for server: .
Operation completed successfullyNous pouvons voir la liste des nœuds (un seul pour le moment) avec la commande :
drbdmanage list-nodesQui nous retournera :
+------------------------------------------------------------------------------+
| Name | Pool Size | Pool Free | | State |
|------------------------------------------------------------------------------|
| srv1 | 2044 | 2036 | | ok |
+------------------------------------------------------------------------------+Nous ajoutons ensuite le second nœud :
drbdmanage add-node srv2 192.168.1.202
Operation completed successfully
Operation completed successfully
Executing join command using ssh.
IMPORTANT: The output you see comes from srv2
IMPORTANT: Your input is executed on srv2
You are going to join an existing drbdmanage cluster.
CAUTION! Note that:
* Any previous drbdmanage cluster information may be removed
* Any remaining resources managed by a previous drbdmanage installation
that still exist on this system will no longer be managed by drbdmanage
Confirm:
yes/no: yes
Waiting for server to start up (can take up to 1 min)
Waiting for server: ........
Operation completed successfully
Give leader time to contact the new node
Operation completed successfully
Operation completed successfullyLa commande drbdmanage list-nodes nous retournera ceci :
drbdmanage list-nodes
+------------------------------------------------------------------------------+
| Name | Pool Size | Pool Free | | State |
|------------------------------------------------------------------------------|
| srv1 | 2044 | 2036 | | online/quorum vote ignored |
| srv2 | 2044 | 2036 | | offline/quorum vote ignored |
+------------------------------------------------------------------------------+Nous créons ensuite une ressource :
:~/drbdmanage# drbdmanage add-resource r0
Operation completed successfullyPuis un volume dans la ressource :
:~/drbdmanage# drbdmanage add-volume r0 1500MB
Operation completed successfullyNous pouvons ensuite voir la liste des volumes avec la commande drbdmanage list-volumes :
~# drbdmanage list-volumes
+------------------------------------------------------------------------------+
| Name | Vol ID | Size | Minor | | State |
|------------------------------------------------------------------------------|
| r0 | 0 | 1,40 GiB | 100 | | ok |
+------------------------------------------------------------------------------+Nous pouvons voir la valeur 100 au niveau du minor, ce qui signifie que le nom du device à utiliser sera /dev/drbd100.
Nous le formatons en OCFS2 comme vu au chapitre précédent :
~# mkfs -t ocfs2 -L MYCLOUD /dev/drbd100
mkfs.ocfs2 1.8.4
Cluster stack: classic o2cb
Label: MYCLOUD
Features: sparse extended-slotmap backup-super unwritten inline-data strict-journal-super xattr indexed-dirs refcount discontig-bg
Block size: 4096 (12 bits)
Cluster size: 4096 (12 bits)
Volume size: 1500000256 (366211 clusters) (366211 blocks)
Cluster groups: 12 (tail covers 11395 clusters, rest cover 32256 clusters)
Extent allocator size: 4194304 (1 groups)
Journal size: 67108864
Node slots: 2
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing backup superblock: 1 block(s)
Formatting Journals: done
Growing extent allocator: done
Formatting slot map: done
Formatting quota files: done
Writing lost+found: done
mkfs.ocfs2 successful8-3-6-6. Linstor▲
Linstor est le successeur de DRBD. Il est utilisé dans les solutions comme OpenNebula et Proxmox. Celui-ci est libre.
N'ayant pas réussi à l'installer, je n'ai pu le tester.
8-4. Ceph▲
Ceph est une plateforme libre de stockage distribué. Ceph est conçu pour être automatiquement distribué et réparable et sans point unique de défaillance.
Ceph est utilisable en mode bloc ou en mode objet (comme Amazon S3 en mode HTTP REST).
Ceph pourrait à lui tout seul faire l'objet d'un tutoriel, nous allons ici le survoler. Vous pourrez avoir une installation fonctionnelle au moins à minima en suivant ce chapitre.
8-4-1. Modules Ceph▲
Ceph est composé de plusieurs démons, répartis sur plusieurs machines. Il est possible d'avoir plusieurs types de démons sur la même machine, mais cela n'a pas d’intérêt et est même contre-productif sur un important cluster.
- Monitor (Mon) : ce sont les chefs d’orchestre du cluster Ceph. S'il n'y a pas de moniteur disponible, il n'y a pas d’accès au cluster Ceph. Pour assurer la pérennité du cluster, les moniteurs doivent être sur des machines indépendantes et en nombre impair. Un minimum de trois moniteurs est recommandé.
- OSD (Object Storage Device ou OSD) : il y a un démon OSD par device OSD. Ce démon est en charge du stockage, de la réplication et de la redistribution des données en cas de défaillance. Il fournit les informations de monitoring aux monitors. Un device OSD est l'unité bas niveau de stockage des données. Un cluster Ceph va être composé d'un ensemble d'OSD.
- Meta Data Service (MDS) : nécessaire à l’utilisation de CephFS, va stocker les métadonnées de tous les fichiers et permettre le support de POSIX.
- CephFS : système de fichiers POSIX fourni avec Ceph et s’appuyant sur le stockage Ceph (objet ou bloc). C’est la couche de plus haut niveau.
Les démons MDS et CephFS ne sont nécessaires que si vous utilisez Ceph avec son système de fichiers intégré.
Éléments un peu plus avancés
- pool : regroupement logique de stockage d’objets. Des pools par défaut suffisent à la gestion d’un petit cluster Ceph, mais pour des clusters intersites, il est important d’affiner ce type de réglage. Exemple : nombre de copies/répliquas des objets, répartition des données de type RAID5, etc.
- Placement Group (PG) : peut être vu comme des unités d’allocation et/ou index internes, ils servent à la répartition dans le cluster. Plus il y a de PG, plus on consomme de ressources (CPU/RAM).
Il est possible d’augmenter le nombre de PG d’un pool, mais pas de le réduire.
8-4-2. Fonctionnement de Ceph▲
CRUSH
CRUSH est l’algorithme de répartition des données dans le cluster. La crush map est la cartographie de la répartition des données. Les crush rules sont les règles de répartition des données.
Quand vous créez un cluster Ceph, il y a une crush map par défaut qui peut fonctionner automatiquement. Mais pour un gros cluster, il est important de la gérer. Cela permet d’affiner la répartition des données (entre deux centres de données par exemple), et de repérer facilement un OSD tombé (dans quel centre de données, quelle baie, quelle machine, etc.).
Voici les différents niveaux utilisés par les crush map :
- OSD (peut être vu comme le « device ») ;
- host ;
- chassis ;
- rack ;
- row ;
- pdu ;
- pod ;
- room ;
- datacenter ;
- region ;
- root.
Schéma tiré de la documentation officielle :
|
|
Voici le processus de lecture/écriture sur un cluster Ceph :
- Le client Ceph contacte un moniteur pour obtenir la cartographie du cluster ;
- Les données sont converties en objets (contenant un identifiant d’objet et de pool) ;
- L’algorithme CRUSH détermine le groupe où placer les données et l’OSD primaire ;
- Le client contacte l’OSD primaire pour stocker/récupérer les données ;
-
L’OSD primaire effectue une recherche CRUSH pour déterminer le groupe de placement et l’OSD secondaire.
- Dans un pool répliqué, l’OSD primaire copie l’objet vers l’OSD secondaire,
- Dans un pool avec erasure coding, l’OSD primaire découpe l’objet en segments, génère les segments contenant les calculs de parité et distribue l’ensemble de ces segments vers les OSD secondaires tout en écrivant un segment en local.
8-4-3. Installation de Ceph▲
Nous utiliserons la version Ceph Luminous (v,12).
8-4-3-1. Installation d'une première machine▲
8-4-3-1-1. Préparations▲
Nous allons commencer par les prérequis.
Nous fixons le nom de notre hôte dans le fichier /,etc/hosts :
192.168.1.200 srv1Nous spécifions le hostname dans le fichier /,etc/hostname en y mettant le nom « srv1 ».
Nous lançons la commande hostname :
hostname srv1Nous fermons et rouvrons la session pour prendre en compte le nouveau nom.
Nous installons ensuite le serveur de temps, indispensable à la synchronisation correcte entre différentes machines :
apt-get install ntp ntpdateEnsuite, nous configurons SSH afin de permettre une connexion par clé. D’abord, nous générons une clé avec la commande ssh-keygen :
root@srv1:~# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? ^C
root@srv1:~# rm .ssh/* -rf
root@srv1:~# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
3c:38:bc:0d:54:45:13:2c:dc:bd:61:8c:24:d9:58:06 root@srv1
The key's randomart image is:
+---[RSA 2048]----+
| .E%O= |
| .=o=.= |
| . . . o |
| o o . |
| = S |
| = . |
| . . |
| |
| |
+-----------------+
root@srv1:~#Ensuite, nous copions la clé avec ssh-copy-id :
ssh-copy-id root@srv1
The authenticity of host 'srv1 (192.168.1.200)' can't be established.
ECDSA key fingerprint is 92:27:9f:61:14:19:63:85:28:d2:1b:88:4e:86:d6:08.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@srv1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@srv1'"
and check to make sure that only the key(s) you wanted were added.Toutes les commandes Ceph passent par SSH et le nom d'hôte, il faut donc créer une clé SSH même pour une communication locale.
Grâce à cela, la commande ssh root@srv1 devrait ouvrir un Shell, sans nécessité de mot de passe, ce qui nous sera nécessaire pour les commandes suivantes.
8-4-3-1-2. Installation de ceph-deploy▲
Une fois les prérequis effectués, nous allons installer et utiliser la commande ceph-deploy qui nous permettra de préparer et déployer notre cluster.
Nous commençons par télécharger le fichier de signature de dépôt :
wget download.ceph.com/keys/release.ascNous installons celui-ci :
apt-key add release.ascNous ajoutons le dépôt dans /etc/apt/sources.list :
deb https://download.ceph.com/debian-luminous/ stretch mainPuis effectuons l'installation :
apt-get update
apt-get install ceph-deploy8-4-3-1-3. Configuration▲
Nous créons un dossier qui contiendra les fichiers de configuration du cluster :
mkdir cephdeploy
cd cephdeployNous créons notre cluster :
ceph-deploy new srv1La console nous retournera les informations suivantes :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy new srv1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f2db686dc68>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] mon : ['srv1']
[ceph_deploy.cli][INFO ] func : <function new at 0x7f2db6843cf8>
[ceph_deploy.cli][INFO ] public_network : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster_network : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] fsid : None
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /bin/ip link show
[srv1][INFO ] Running command: /bin/ip addr show
[srv1][DEBUG ] IP addresses found: [u'192.168.1.200']
[ceph_deploy.new][DEBUG ] Resolving host srv1
[ceph_deploy.new][DEBUG ] Monitor srv1 at 192.168.1.200
[ceph_deploy.new][DEBUG ] Monitor initial members are ['srv1']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['192.168.1.200']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
root@srv1:~/cephdeploy#Ceci va créer les fichiers :
- ceph.conf ;
- ceph-deploy-ceph.log ;
- ceph.mon.keyring.
le fichier ceph.conf contient :
[global]
fsid = 85967fe2-3f08-4e0b-9f3c-ca6647776383
mon_initial_members = srv1
mon_host = 192.168.1.200
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephxDans lequel on ajoute :
osd pool default size = 2
osd pool default min size = 1
public_network = 192.168.1.0/24
cluster_network = 192.168.1.0/24C'est ce fichier qui contiendra la configuration complète du cluster. À ce stade, il n'y a qu'une machine avec les réglages minimums nécessaires au démarrage. Ce fichier sera complété au fur et à mesure de l'avancée dans le chapitre et de l'ajout des modules/machines.
Ceci va nous permettre de créer un pool OSD à deux disques et permettre l'utilisation avec un seul nœud (en mode dégradé).
Les lignes public_network/cluster_network permettent de gérer les réseaux autorisés pour le dialogue entre les entités Ceph. Dans notre cas, il n'y a aucune séparation ce qui n'est pas recommandé en production.
Nous installons ceph-deploy sur notre premier nœud :
ceph-deploy install srv1Lire les logs peut permettre de comprendre les opérations déclenchées. Cela pourra vous être utile si vous comptez utiliser le service. Si vous ne lisez ce chapitre qu'à titre de découverte ou de veille technologique, vous pouvez passer directement à la suite.
Voici un exemple des logs affichés :
Debian GNU/Linux 8
srv1 login: root
Password:
Last login: Fri Nov 16 18:45:59 CET 2018 from srv1 on pts/1
Linux srv1 3.16.0-4-amd64 #1 SMP Debian 3.16.51-3 (2017-12-13) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
root@srv1:~# apt-get install ca-certificates apt-transport-https
Lecture des listes de paquets... Fait
Construction de l'arbre des dépendances
Lecture des informations d'état... Fait
apt-transport-https est déjà la plus récente version disponible.
ca-certificates est déjà la plus récente version disponible.
0 mis à jour, 0 nouvellement installés, 0 à enlever et 24 non mis à jour.
root@srv1:~# ceph-deploy install srv1
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy install srv1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] testing : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fd903c207a0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] dev_commit : None
[ceph_deploy.cli][INFO ] install_mds : False
[ceph_deploy.cli][INFO ] stable : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] adjust_repos : True
[ceph_deploy.cli][INFO ] func : <function install at 0x7fd904063410>
[ceph_deploy.cli][INFO ] install_mgr : False
[ceph_deploy.cli][INFO ] install_all : False
[ceph_deploy.cli][INFO ] repo : False
[ceph_deploy.cli][INFO ] host : ['srv1']
[ceph_deploy.cli][INFO ] install_rgw : False
[ceph_deploy.cli][INFO ] install_tests : False
[ceph_deploy.cli][INFO ] repo_url : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] install_osd : False
[ceph_deploy.cli][INFO ] version_kind : stable
[ceph_deploy.cli][INFO ] install_common : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] dev : master
[ceph_deploy.cli][INFO ] nogpgcheck : False
[ceph_deploy.cli][INFO ] local_mirror : None
[ceph_deploy.cli][INFO ] release : None
[ceph_deploy.cli][INFO ] install_mon : False
[ceph_deploy.cli][INFO ] gpg_url : None
[ceph_deploy.install][DEBUG ] Installing stable version jewel on cluster ceph hosts srv1
[ceph_deploy.install][DEBUG ] Detecting platform for host srv1 ...
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[ceph_deploy.install][INFO ] Distro info: debian 8.10 jessie
[srv1][INFO ] installing Ceph on srv1
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q --no-install-recommends install ca-certificates apt-transport-https
[srv1][DEBUG ] Lecture des listes de paquets…
[srv1][DEBUG ] Construction de l'arbre des dépendances…
[srv1][DEBUG ] Lecture des informations d'état…
[srv1][DEBUG ] apt-transport-https est déjà la plus récente version disponible.
[srv1][DEBUG ] ca-certificates est déjà la plus récente version disponible.
[srv1][DEBUG ] 0 mis à jour, 0 nouvellement installés, 0 à enlever et 24 non mis à jour.
[srv1][INFO ] Running command: wget -O release.asc https://download.ceph.com/keys/release.asc
[srv1][WARNIN] --2018-11-16 19:30:22-- https://download.ceph.com/keys/release.asc
[srv1][WARNIN] Résolution de download.ceph.com (download.ceph.com)… 158.69.68.124, 2607:5300:201:2000::3:58a1
[srv1][WARNIN] Connexion à download.ceph.com (download.ceph.com)|158.69.68.124|:443… connecté.
[srv1][WARNIN] requête HTTP transmise, en attente de la réponse… 200 OK
[srv1][WARNIN] Taille : 1645 (1,6K) [application/octet-stream]
[srv1][WARNIN] Sauvegarde en : « release.asc »
[srv1][WARNIN]
[srv1][WARNIN] 0K . 100% 27,7M=0s
[srv1][WARNIN]
[srv1][WARNIN] 2018-11-16 19:30:23 (27,7 MB/s) — « release.asc » sauvegardé [1645/1645]
[srv1][WARNIN]
[srv1][INFO ] Running command: apt-key add release.asc
[srv1][DEBUG ] OK
[srv1][DEBUG ] add deb repo to /etc/apt/sources.list.d/
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q update
[srv1][DEBUG ] Ign http://ftp.fr.debian.org jessie InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie-updates InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie Release.gpg
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie Release
[srv1][DEBUG ] Réception de : 1 http://ftp.fr.debian.org jessie-updates/main amd64 Packages/DiffIndex [11,8 kB]
[srv1][DEBUG ] Réception de : 2 http://ftp.fr.debian.org jessie-updates/main Translation-en/DiffIndex [3 688 B]
[srv1][DEBUG ] Atteint https://download.ceph.com jessie InRelease
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates/main amd64 Packages
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/updates/main Translation-en
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main amd64 Packages
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main Translation-fr
[srv1][DEBUG ] Réception de : 3 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Atteint http://ftp.fr.debian.org jessie/main Translation-en
[srv1][DEBUG ] Réception de : 4 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Réception de : 5 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Atteint https://download.ceph.com jessie/main amd64 Packages
[srv1][DEBUG ] Réception de : 6 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Réception de : 7 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Réception de : 8 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Réception de : 9 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Réception de : 10 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Réception de : 11 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Réception de : 12 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Réception de : 13 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Réception de : 14 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Réception de : 15 https://download.ceph.com jessie/main Translation-fr_FR [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-fr_FR
[srv1][DEBUG ] Réception de : 16 https://download.ceph.com jessie/main Translation-fr [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-fr
[srv1][DEBUG ] Réception de : 17 https://download.ceph.com jessie/main Translation-en [178 B]
[srv1][DEBUG ] Ign https://download.ceph.com jessie/main Translation-en
[srv1][DEBUG ] 15,5 ko réceptionnés en 5s (3 032 o/s)
[srv1][DEBUG ] Lecture des listes de paquets…
[srv1][WARNIN] W: Duplicate sources.list entry https://download.ceph.com/debian-jewel/ jessie/main amd64 Packages (/var/lib/apt/lists/download.ceph.com_debian-jewel_dists_jessie_main_binary-amd64_Packages)
[srv1][WARNIN] W: Vous pouvez lancer « apt-get update » pour corriger ces problèmes.
[srv1][INFO ] Running command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q --no-install-recommends install -o Dpkg::Options::=--force-confnew ceph ceph-osd ceph-mds ceph-mon radosgw
[srv1][DEBUG ] Lecture des listes de paquets…
[srv1][DEBUG ] Construction de l'arbre des dépendances…
[srv1][DEBUG ] Lecture des informations d'état…
[srv1][DEBUG ] ceph est déjà la plus récente version disponible.
[srv1][DEBUG ] ceph-mds est déjà la plus récente version disponible.
[srv1][DEBUG ] ceph-mon est déjà la plus récente version disponible.
[srv1][DEBUG ] ceph-osd est déjà la plus récente version disponible.
[srv1][DEBUG ] radosgw est déjà la plus récente version disponible.
[srv1][DEBUG ] 0 mis à jour, 0 nouvellement installés, 0 à enlever et 24 non mis à jour.
[srv1][INFO ] Running command: ceph --version
[srv1][DEBUG ] ceph version 10.2.11 (e4b061b47f07f583c92a050d9e84b1813a35671e)
root@srv1:~#Dans les logs, nous pouvons voir ce qu'il se passe :
- connexion SSH sur srv1 ;
- téléchargement de la clé de dépôt Ceph (nous l'avons déjà fait pour l'installation de ceph-deploy, inutile ici, mais nécessaire pour le déploiement de Ceph sur une autre machine) ;
- ajout de la clé avec apt-key (déjà fait) ;
- ajout du dépôt dans /etc/apt/sources.list.d (en doublon avec ce qui a déjà été fait pour installer ceph-deploy, nous voyons un avertissement à ce sujet) ;
- installation des paquets nécessaires.
La commande se termine par l'appel de ceph –version.
La commande est prévue pour installer tout ce qu'il faut sur n'importe quelle machine via SSH.
8-4-3-1-4. Création d'un moniteur▲
Pour gérer notre cluster, nous avons besoin d’un moniteur. La création s’effectue avec la commande :
ceph-deploy mon create-initialQui retourne :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy mon create-initial
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create-initial
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7faf0fb69fc8>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mon at 0x7faf0ffd4500>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] keyrings : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mon][DEBUG ] Deploying mon, cluster ceph hosts srv1
[ceph_deploy.mon][DEBUG ] detecting platform for host srv1 ...
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[ceph_deploy.mon][INFO ] distro info: debian 8.10 jessie
[srv1][DEBUG ] determining if provided host has same hostname in remote
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] deploying mon to srv1
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] remote hostname: srv1
[srv1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[srv1][DEBUG ] create the mon path if it does not exist
[srv1][DEBUG ] checking for done path: /var/lib/ceph/mon/ceph-srv1/done
[srv1][DEBUG ] done path does not exist: /var/lib/ceph/mon/ceph-srv1/done
[srv1][INFO ] creating keyring file: /var/lib/ceph/tmp/ceph-srv1.mon.keyring
[srv1][DEBUG ] create the monitor keyring file
[srv1][INFO ] Running command: ceph-mon --cluster ceph --mkfs -i srv1 --keyring /var/lib/ceph/tmp/ceph-srv1.mon.keyring --setuser 64045 --setgroup 64045
[srv1][DEBUG ] ceph-mon: renaming mon.noname-a 192.168.1.200:6789/0 to mon.srv1
[srv1][DEBUG ] ceph-mon: set fsid to 85967fe2-3f08-4e0b-9f3c-ca6647776383
[srv1][DEBUG ] ceph-mon: created monfs at /var/lib/ceph/mon/ceph-srv1 for mon.srv1
[srv1][INFO ] unlinking keyring file /var/lib/ceph/tmp/ceph-srv1.mon.keyring
[srv1][DEBUG ] create a done file to avoid re-doing the mon deployment
[srv1][DEBUG ] create the init path if it does not exist
[srv1][INFO ] Running command: systemctl enable ceph.target
[srv1][INFO ] Running command: systemctl enable ceph-mon@srv1
[srv1][WARNIN] Created symlink from /etc/systemd/system/ceph-mon.target.wants/ceph-mon@srv1.service to /lib/systemd/system/ceph-mon@.service.
[srv1][INFO ] Running command: systemctl start ceph-mon@srv1
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[srv1][DEBUG ] ********************************************************************************
[srv1][DEBUG ] status for monitor: mon.srv1
[srv1][DEBUG ] {
[srv1][DEBUG ] "election_epoch": 3,
[srv1][DEBUG ] "extra_probe_peers": [],
[srv1][DEBUG ] "monmap": {
[srv1][DEBUG ] "created": "2018-11-16 19:53:16.240703",
[srv1][DEBUG ] "epoch": 1,
[srv1][DEBUG ] "fsid": "85967fe2-3f08-4e0b-9f3c-ca6647776383",
[srv1][DEBUG ] "modified": "2018-11-16 19:53:16.240703",
[srv1][DEBUG ] "mons": [
[srv1][DEBUG ] {
[srv1][DEBUG ] "addr": "192.168.1.200:6789/0",
[srv1][DEBUG ] "name": "srv1",
[srv1][DEBUG ] "rank": 0
[srv1][DEBUG ] }
[srv1][DEBUG ] ]
[srv1][DEBUG ] },
[srv1][DEBUG ] "name": "srv1",
[srv1][DEBUG ] "outside_quorum": [],
[srv1][DEBUG ] "quorum": [
[srv1][DEBUG ] 0
[srv1][DEBUG ] ],
[srv1][DEBUG ] "rank": 0,
[srv1][DEBUG ] "state": "leader",
[srv1][DEBUG ] "sync_provider": []
[srv1][DEBUG ] }
[srv1][DEBUG ] ********************************************************************************
[srv1][INFO ] monitor: mon.srv1 is running
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[ceph_deploy.mon][INFO ] processing monitor mon.srv1
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.srv1.asok mon_status
[ceph_deploy.mon][INFO ] mon.srv1 monitor has reached quorum!
[ceph_deploy.mon][INFO ] all initial monitors are running and have formed quorum
[ceph_deploy.mon][INFO ] Running gatherkeys...
[ceph_deploy.gatherkeys][INFO ] Storing keys in temp directory /tmp/tmpyWJn4J
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] get remote short hostname
[srv1][DEBUG ] fetch remote file
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --admin-daemon=/var/run/ceph/ceph-mon.srv1.asok mon_status
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.admin
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-mds
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get-or-create client.bootstrap-mds mon allow profile bootstrap-mds
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-mgr
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get-or-create client.bootstrap-mgr mon allow profile bootstrap-mgr
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-osd
[srv1][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-srv1/keyring auth get client.bootstrap-rgw
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpyWJn4J
root@srv1:~/cephdeploy#8-4-3-1-5. Ajout d'OSD▲
Nous pouvons commencer par lister les disques d'un hôte Ceph avec la commande suivante :
ceph-deploy disk list srv1Qui affichera dans mon exemple :
…
[srv1][INFO ] Running command: /usr/sbin/ceph-disk list
[srv1][DEBUG ] /dev/sda :
[srv1][DEBUG ] /dev/sda2 swap, swap
[srv1][DEBUG ] /dev/sda1 other, ext4, mounted on /
[srv1][DEBUG ] /dev/sdb other, unknown
[srv1][DEBUG ] /dev/sr0 other, unknown
root@srv1:~/cephdeploy#Nous allons procéder à la préparation de l'OSD sur le disque /dev/sdb.
Ceci effacera l'éventuel contenu sur le disque.
Voici la commande :
ceph-deploy osd prepare srv1:/dev/sdbQui retournera :
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy osd prepare srv1:/dev/sdb
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] disk : [('srv1', '/dev/sdb', None)]
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : prepare
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /,etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fc9a8963ef0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x7fc9a8dc6488>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.osd][DEBUG ] Preparing cluster ceph disks srv1:/dev/sdb:
[srv1][DEBUG ] connected to host: srv1
[srv1][DEBUG ] detect platform information from remote host
[srv1][DEBUG ] detect machine type
[srv1][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: debian 8.10 jessie
[ceph_deploy.osd][DEBUG ] Deploying osd to srv1
[srv1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.osd][DEBUG ] Preparing host srv1 disk /dev/sdb journal None activate False
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /usr/sbin/ceph-disk -v prepare --cluster ceph --fs-type xfs -- /dev/sdb
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=fsid
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-allows-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-wants-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-needs-journal -i 0 --log-file $run_dir/$cluster-osd-check.log --cluster ceph --setuser ceph --setgroup ceph
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] set_type: Will colocate journal with data on /dev/sdb
[srv1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=osd_journal_size
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_mkfs_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_fs_mkfs_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_mount_options_xfs
[srv1][WARNIN] command: Running command: /usr/bin/ceph-conf --cluster=ceph --name=osd. --lookup osd_fs_mount_options_xfs
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] ptype_tobe_for_name: name = journal
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] create_partition: Creating journal partition num 2 size 5120 on /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --new=2:0:+5120M --change-name=2:ceph journal --partition-guid=2:74a9b3f0-08b8-48db-a3ec-e6e36451d0d9 --typecode=2:45b0969e-9b03-4f30-b4c6-b4b80ceff106 --mbrtogpt -- /dev/sdb
[srv1][DEBUG ] Creating new GPT entries.
[srv1][DEBUG ] Setting name!
[srv1][DEBUG ] partNum is 1
[srv1][DEBUG ] REALLY setting name!
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on created device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb2 uuid path is /sys/dev/block/8:18/dm/uuid
[srv1][WARNIN] prepare_device: Journal is GPT partition /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] prepare_device: Journal is GPT partition /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] set_data_partition: Creating osd partition on /dev/sdb
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] ptype_tobe_for_name: name = data
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] create_partition: Creating data partition num 1 size 0 on /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --largest-new=1 --change-name=1:ceph data --partition-guid=1:720e149a-ebb7-4d44-9b89-d1c017481c18 --typecode=1:89c57f98-2fe5-4dc0-89c1-f3ad0ceff2be --mbrtogpt -- /dev/sdb
[srv1][DEBUG ] Setting name!
[srv1][DEBUG ] partNum is 0
[srv1][DEBUG ] REALLY setting name!
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on created device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb1 uuid path is /sys/dev/block/8:17/dm/uuid
[srv1][WARNIN] populate_data_path_device: Creating xfs fs on /dev/sdb1
[srv1][WARNIN] command_check_call: Running command: /sbin/mkfs -t xfs -f -i size=2048 -- /dev/sdb1
[srv1][DEBUG ] meta-data=/dev/sdb1 isize=2048 agcount=4, agsize=196543 blks
[srv1][DEBUG ] = sectsz=512 attr=2, projid32bit=1
[srv1][DEBUG ] = crc=0 finobt=0
[srv1][DEBUG ] data = bsize=4096 blocks=786171, imaxpct=25
[srv1][DEBUG ] = sunit=0 swidth=0 blks
[srv1][DEBUG ] naming =version 2 bsize=4096 ascii-ci=0 ftype=0
[srv1][DEBUG ] log =internal log bsize=4096 blocks=2560, version=2
[srv1][DEBUG ] = sectsz=512 sunit=0 blks, lazy-count=1
[srv1][DEBUG ] realtime =none extsz=4096 blocks=0, rtextents=0
[srv1][WARNIN] mount: Mounting /dev/sdb1 on /var/lib/ceph/tmp/mnt.zWKFv6 with options noatime,inode64
[srv1][WARNIN] command_check_call: Running command: /bin/mount -t xfs -o noatime,inode64 -- /dev/sdb1 /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] populate_data_path: Preparing osd data dir /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/ceph_fsid.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/fsid.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/magic.4952.tmp
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6/journal_uuid.4952.tmp
[srv1][WARNIN] adjust_symlink: Creating symlink /var/lib/ceph/tmp/mnt.zWKFv6/journal -> /dev/disk/by-partuuid/74a9b3f0-08b8-48db-a3ec-e6e36451d0d9
[srv1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] unmount: Unmounting /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] command_check_call: Running command: /bin/umount -- /var/lib/ceph/tmp/mnt.zWKFv6
[srv1][WARNIN] get_dm_uuid: get_dm_uuid /dev/sdb uuid path is /sys/dev/block/8:16/dm/uuid
[srv1][WARNIN] command_check_call: Running command: /sbin/sgdisk --typecode=1:4fbd7e29-9d25-41b8-afd0-062c0ceff05d -- /dev/sdb
[srv1][DEBUG ] The operation has completed successfully.
[srv1][WARNIN] update_partition: Calling partprobe on prepared device /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command: Running command: /usr/bin/flock -s /dev/sdb /sbin/partprobe /dev/sdb
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm settle --timeout=600
[srv1][WARNIN] command_check_call: Running command: /sbin/udevadm trigger --action=add --sysname-match sdb1
[srv1][INFO ] checking OSD status...
[srv1][DEBUG ] find the location of an executable
[srv1][INFO ] Running command: /usr/bin/ceph --cluster=ceph osd stat --format=json
[srv1][WARNIN] there is 1 OSD down
[srv1][WARNIN] there is 1 OSD out
[ceph_deploy.osd][DEBUG ] Host srv1 is now ready for osd use.
root@srv1:~/cephdeploy#Nous pouvons voir la création d'une table de partitions GPT et la création de partitions XFS.
Rappelons la commande ceph-deploy disk list srv1 :
…
[srv1][INFO ] Running command: /usr/sbin/ceph-disk list
[srv1][DEBUG ] /dev/sda :
[srv1][DEBUG ] /dev/sda2 swap, swap
[srv1][DEBUG ] /dev/sda1 other, ext4, mounted on /
[srv1][DEBUG ] /dev/sdb :
[srv1][DEBUG ] /dev/sdb2 ceph journal, for /dev/sdb1
[srv1][DEBUG ] /dev/sdb1 ceph data, active, cluster ceph, osd.0, journal /dev/sdb2
[srv1][DEBUG ] /dev/sr0 other, unknown
root@srv1:~/cephdeploy#Nous pouvons voir qu'il y a en fait deux partitions : une partition pour les données de Ceph (ceph data) en /dev/sdb1 et une partition pour les journaux Ceph (ceph journal) en /dev/sdb2.
Pour des questions de performance, il est conseillé de mettre les journaux sur disques SSD).
Nous activons ensuite l'OSD :
ceph-deploy osd activate srv1:/dev/sdb1Pour lister les OSD d'un cluster Ceph, vous pouvez utiliser la commande suivante :
ceph osd treeQui retournera dans mon exemple :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
root@srv1:~#Nous pouvons voir que notre cluster ne contient qu'un seul OSD : osd.0 sur l'hôte srv1.
8-4-3-1-6. Préparation des pools▲
Nous préparation ensuite le pool pour le système de fichiers CephFS :
ceph osd pool create cephfs_metadata 128
ceph osd pool create cephfs_data 128La valeur de paramètre 128 correspond à la valeur de « placement group » appelé aussi PG.
Voici ce qui est préconisé par Ceph :
- moins de 5 OSD : 128 ;
- entre 5 et 10 OSD : 512 ;
- entre 10 et 50 OSD : 1024.
Au-delà de 50 OSD, il est recommandé d’utiliser la formule conseillée par les développeurs. Vous pouvez la retrouver avec l’outil en ligne pgcal.
Les « placement group » permettent d'agréger les objets en pools, permettant le suivi de ceux-ci de façon plus efficace, surtout dans des infrastructures importantes.
Listage des pool
Pour lister les pool d'un cluster Ceph, on utilisera la commande :
ceph osd lspoolsQui nous retournera :
0 rbd,1 cephfs_metadata,2 cephfs_data,
root@srv1:~#Le pool rbd est un pool de base, qui ne nous servira pas, nous pouvons le supprimer avec la commande :
ceph osd pool delete rbdVous aurez un message vous expliquant qu'il faut saisir deux fois le nom du rbd suivi de –yes-i-really-really-mean-it.
8-4-3-1-7. Création d'un démon MDS▲
La création d’un démon MDS s’effectue avec la commande suivante :
ceph-deploy mds create srv1Celui-ci sera nécessaire pour gérer les métadonnées du système de fichier CephFS.
8-4-3-1-8. Création du système de fichiers CephFS▲
La création de notre système de fichiers se fait via la commande :
root@srv1:~/cephdeploy# ceph fs new mon_fs cephfs_metadata cephfs_data
new fs with metadata pool 1 and data pool 2
root@srv1:~/cephdeploy#mon_fs étant le nom donné au système de fichiers.
État du cluster
Nous pouvons voir l'état du cluster Ceph avec la commande :
ceph -sRésultat :
cluster fba9a869-5b18-4feb-bd9c-5374808af689
health HEALTH_WARN
192 pgs degraded
64 pgs stuck unclean
192 pgs undersized
recovery 20/40 objects degraded (50.000%)
monmap e1: 1 mons at {srv1=192.168.1.200:6789/0}
election epoch 3, quorum 0 srv1
fsmap e5: 1/1/1 up {0=srv1=up:active}
osdmap e10: 1 osds: 1 up, 1 in
flags sortbitwise,require_jewel_osds
pgmap v22: 192 pgs, 3 pools, 2068 bytes data, 20 objects
108 MB used, 2952 MB / 3060 MB avail
20/40 objects degraded (50.000%)
192 active+undersized+degraded
root@srv1:~#8-4-3-1-9. Montage du volume CephFS▲
Nous commençons par déployer les fichiers de configuration avec la commande :
ceph-deploy admin srv1Ceci va copier les fichiers suivants dans /,etc/ceph :
- ceph.client.admin.keyring ;
- ceph.conf ;
- rbdmap.
Il nous faut créer un fichier ceph.client.admin.keyring contenant la clé codée en Base64.
Le fichier a le format suivant :
[client.test]
key = AQDR1O9bDuaFMBAAwlLxUpWYzVTtNaAAawYygA==Nous dupliquons le fichier client.ceph.admin.keyring dans le dossier /,etc/ceph. Nous nommons la copie client.admin.
Le fichier ne devra contenir que la clé Base64 :
AQDR1O9bDuaFMBAAwlLxUpWYzVTtNaAAawYygA==Exemple de commande de génération d'une clé pour un utilisateur précis :
root@srv1:~/cephdeploy# ceph auth get-or-create client.test mds 'allow' osd 'allow *' mon 'allow *' > fichier_de_keyringNous aurons besoin du paquet ceph-fs-common que ceph-deploy n'a pas installé :
apt-get install ceph-fs-commonNous pourrons ensuite monter le volume avec la commande mount à laquelle nous lui aurons donné en option le nom d'utilisateur ainsi que le fichier de clé :
mount.ceph srv1:/ /mnt -o name=admin,secretfile=/etc/ceph/client.adminVoici la ligne à ajouter dans /,etc/fstab pour un montage automatique lors du démarrage de la machine :
srv1:/ /mnt ceph name=admin,secretfile=/etc/ceph/admin.clientIl faudra garder les fichiers du dossier de configuration ceph-deploy et s'assurer d'en avoir une sauvegarde.
8-4-3-2. Ajout d'une seconde machine▲
Il faudra qu’OpenSSH, un serveur de temps et Python soit installé sur l’hôte.
Il faudra procéder à la configuration de SSH de façon à ce que srv1 puisse le contacter sans authentification. Tout cela comme pour la préparation du premier serveurPréparations.
Nous installons ensuite Ceph sur le nouveau serveur srv2 depuis srv1 :
ceph-deploy install srv2Nous créons ensuite un OSD sur la machine srv2 de la même façon que pour srv1 :
ceph-deploy osd prepare srv2:/dev/sdb
ceph-deploy osd activate srv2:/dev/sdb1Nous pourrons voir les deux OSD sur les deux hôtes avec la commande ceph osd tree :
root@srv1:~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 up 1.00000 1.00000Nous pouvons voir l'état du cluster avec la commande ceph -s. Vous pourrez voir son état de reconstruction. Une fois la mise à jour des blocs sur le nouvel OSD, nous pourrons voir le cluster en mode HEALTH_OK :
root@srv1:~# ceph -s
cluster fba9a869-5b18-4feb-bd9c-5374808af689
health HEALTH_OK
monmap e1: 1 mons at {srv1=192.168.1.200:6789/0}
election epoch 4, quorum 0 srv1
fsmap e11: 1/1/1 up {0=srv1=up:active}
osdmap e21: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v140: 192 pgs, 3 pools, 6186 kB data, 34 objects
231 MB used, 5890 MB / 6121 MB avail
192 active+clean
root@srv1:~#Nous pouvons ensuite ajouter srv2 en tant que moniteur :
ceph-deploy mon add srv2Résultat :
…
[srv2][INFO ] monitor: mon.srv2 is currently at the state of probingPour rappel, le nombre de moniteurs doit être impair, et il est recommandé de mettre un moniteur sur une machine autonome hors OSD.
Sur le même principe, nous pouvons ajouter un serveur de métadonnées sur srv2 :
ceph-deploy mds create srv2Nous modifions le fichier ceph.conf en y ajoutant l'adresse IP du second moniteur dans la ligne mon_host, puis nous mettons ensuite à jour les configurations :
ceph-deploy --overwrite-conf admin srv1 srv2L'option -–overwite-conf étant nécessaire pour écraser une ancienne configuration (celle de srv1 dans notre cas, la commande ayant déjà été lancée dessus).
8-4-3-3. Test de panne : arrêt de srv1▲
La perte de srv1 (ou de srv2) ne provoque pas l’indisponibilité du cluster en cas de présence d'un troisième serveur hébergeant un moniteur. Dans le cas contraire, le point de montage est indisponible après quelques secondes et la commande ceph -s bloque la console.
Le redémarrage de la machine arrêtée permettra de récupérer le cluster après réparation automatique.
8-4-3-4. Procédure de réparation d'un nœud▲
Nous commençons par voir l'état de Ceph :
~# ceph -sQui nous affichera :
cluster 6e3c0267-1480-4671-9382-9686be7e2663
health HEALTH_WARN
200 pgs degraded
200 pgs stuck degraded
200 pgs stuck unclean
200 pgs stuck undersized
200 pgs undersized
recovery 21/63 objects degraded (33.333%)
1 mons down, quorum 0,2 srv1,srv3
monmap e3: 3 mons at {srv1=192.168.1.200:6789/0,srv2=192.168.1.201:6789/0,srv3=192.168.1.202:6789/0}
election epoch 16, quorum 0,2 srv1,srv3
fsmap e9: 1/1/1 up {0=srv1=up:active}
osdmap e45: 3 osds: 2 up, 2 in; 200 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v189: 200 pgs, 2 pools, 23070 bytes data, 21 objects
218 MB used, 5903 MB / 6121 MB avail
21/63 objects degraded (33.333%)
200 active+undersized+degradedPour voir ce qu’il en est des OSD :
~# ceph osd treeQui nous retournera :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00870 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 down 0 1.00000
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Nous voyons que l’OSD.1 sur l'hôte srv2 est « down ». Nous le supprimons :
~# ceph osd rm osd.1
removed osd.1Nous rappelons la commande ceph osd tree :
~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00870 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0.00290 host srv2
1 0.00290 osd.1 DNE 0
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Nous voyons l’OSD 1 toujours présent en mode DNE (pour Do Not Exist).
Nous supprimons celui-ci définitivement avec la commande suivante :
~# ceph osd crush rm osd.1
removed item id 1 name 'osd.1' from crush mapNous supprimons ensuite les autorisations :
~# ceph auth del osd.1
updatedSi nous rappelons la commande ceph osd tree, l'OSD n'est plus présent, mais nous voyons toujours le nœud (sans OSD) :
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.00580 root default
-2 0.00290 host srv1
0 0.00290 osd.0 up 1.00000 1.00000
-3 0 host srv2
-4 0.00290 host srv3
2 0.00290 osd.2 up 1.00000 1.00000Pour supprimer celui-ci, nous allons l'enlever de la crush map.
Nous commençons par exporter celle-ci avec la commande getcrushmap.
~# ceph osd getcrushmap -o crush_map
got crush map from osdmap epoch 79Il va falloir convertir ce fichier en mode texte :
~# crushtool -d crush_map -o crush_map.txtVoici un exemple du contenu de ce fichier texte :
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable straw_calc_version 1
# devices
device 0 osd.0
device 1 device1
device 2 osd.2
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host srv1 {
id -2 # do not change unnecessarily
# weight 0.003
alg straw
hash 0 # rjenkins1
item osd.0 weight 0.003
}
host srv3 {
id -4 # do not change unnecessarily
# weight 0.003
alg straw
hash 0 # rjenkins1
item osd.2 weight 0.003
}
host srv2 {
id -3 # do not change unnecessarily
# weight 0.000
alg straw
hash 0 # rjenkins1
}
root default {
id -1 # do not change unnecessarily
# weight 0.006
alg straw
hash 0 # rjenkins1
item srv1 weight 0.003
item srv3 weight 0.003
item srv2 weight 0.000
}
# rules
rule replicated_ruleset {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush mapModifier la crush map va permettre d'optimiser la gestion du cluster Ceph notamment dans le cas de nœuds importants (gestion de régions, rack, pds, etc.)
Je retire les références à srv2 (le bloc srv2 entre crochets, et la ligne item srv2...)
Pour appliquer les modifications, je recompile le fichier texte :
~# crushtool -c crush_map.txt -o crush_mapPuis applique celui-ci :
~# ceph osd setcrushmap -i crush_map
set crush mapToute trace de srv2 dans les OSD est alors supprimée.
Nous préparons ensuite un serveur de base avec les prérequis (adresse IP de srv2, nom de machine srv2, fichier hosts renseigné avec les autres serveurs, paquets ntp, openssh-server, et python installé).
Nous recopions ensuite la clé SSH de srv1 vers srv2 :
~# ssh-copy-id root@srv2Nous allons avoir un message d'erreur :
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!@
ERROR: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ERROR: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
ERROR: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
ERROR: It is also possible that a host key has just been changed.
ERROR: The fingerprint for the ECDSA key sent by the remote host is
ERROR: SHA256:GXC4wVDCLG3a+KXA3Tb95ULTZGm2REM0pmOBBCZ371A.
ERROR: Please contact your system administrator.
ERROR: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
ERROR: Offending ECDSA key in /root/.ssh/known_hosts:5
ERROR: remove with:
ERROR: ssh-keygen -f "/root/.ssh/known_hosts" -R srv2
ERROR: ECDSA host key for srv2 has changed and you have requested strict checking.
ERROR: Host key verification failed.Nous utilisons la commande ssh-keygen :
~# ssh-keygen -f "/root/.ssh/known_hosts" -R srv2
# Host srv2 found: line 5
/root/.ssh/known_hosts updated.
Original contents retained as /root/.ssh/known_hosts.oldNous refaisons une tentative de connexion :
ssh root@srv2
The authenticity of host 'srv2 (192.168.1.201)' can't be established.
ECDSA key fingerprint is SHA256:GXC4wVDCLG3a+KXA3Tb95ULTZGm2REM0pmOBBCZ371A.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'srv2' (ECDSA) to the list of known hosts.
Warning: the ECDSA host key for 'srv2' differs from the key for the IP address '192.168.1.201'
Offending key for IP in /root/.ssh/known_hosts:5
Are you sure you want to continue connecting (yes/no)? yes
root@srv2's password:Nous entrons le mot de passe. La prochaine connexion donnera :
Offending key for IP in /root/.ssh/known_hosts:5
Matching host key in /root/.ssh/known_hosts:6
Are you sure you want to continue connecting (yes/no)? yesNous supprimons la ligne concernée :
~# sed -i '5d' ~/.ssh/known_hostsLa commande ssd-copy-id pourra ensuite s’exécuter sans erreur, et une connexion via ssh root@srv2 sans demande de mot de passe sera possible.
Nous réinstallons ensuite Ceph :
~# ceph-deploy install srv2Nous recréons ensuite les OSD comme vu précédemmentAjout d'OSD.
Nous réinstallons le moniteur sur srv2 :
ceph mon add srv2Nous lançons la commande ceph health. Une fois la réparation terminée, la commande ceph -s nous donnera un statut de HEALTH_OK.
8-5. min.io▲
min.io est un système de stockage cloud open source, crée par un ancien de l’équipe Gluster. Il peut être utilisé avec une configuration de 2 à 32 serveurs et stocker des objets jusqu’à 5 To. Il ne possède pas de limite sur le nombre de buckets (notion que nous verrons plus tard) ou d’objets par bucket.
Il peut se comporter comme le service S3 d’Amazon ou faire passerelle avec le service S3 Amazon. Il peut également faire passerelle NFS .
Il est prévu d’origine pour fonctionner dans Docker.
8-5-1. Les différents modes de fonctionnement▲
Default mode : c'est le mode par défaut de fonctionnement de min.io quand utilisé avec une seule machine et un seul disque.
Erasure coded mode : mode permettant la reconstruction des données en cas de perte de ressource. Cet algorithme est basé sur l'algorithme Reed-Solomon. Ce mode nécessite un minimum de quatre disques.
Distributed mode : le serveur min.io en mode distribué vous permet de mettre en pool plusieurs lecteurs (même sur différentes machines) sur un serveur de stockage d'objet unique. Les disques étant répartis sur plusieurs nœuds, min.io distribué peut supporter plusieurs défaillances tout en assurant une protection complète des données.
8-5-2. Installation de min.io▲
min.io est un simple exécutable. Il est récupérable sur le site officiel à l'adresse https://min.io/download ou comme ceci :
wget https://dl.min.io/server/minio/release/linux-amd64/minioil faudra ensuite mettre les droits d’exécution :
chmod +x minioNous déplacerons ensuite le fichier dans /usr/local/bin.
Il est également possible d’installer min.io au travers de brew pour Mac OS X.
Il suffira ensuite de taper la commande minio pour obtenir de l’aide.
8-5-3. Test en mode simple instance▲
Nous allons lancer min.io en fournissant le dossier /data1/minio1 en paramètre :
minio server /data1/minio1Ce qui donne :
Endpoint: http://192.168.1.200:9000 http://127.0.0.1:9000
AccessKey: minioadmin
SecretKey: minioadmin
Browser Access:
http://192.168.1.200:9000 http://127.0.0.1:9000
Command-line Access: https://docs.min.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.200:9000 minioadmin minioadmin
Object API (Amazon S3 compatible):
Go: https://docs.min.io/docs/golang-client-quickstart-guide
Java: https://docs.min.io/docs/java-client-quickstart-guide
Python: https://docs.min.io/docs/python-client-quickstart-guide
JavaScript: https://docs.min.io/docs/javascript-client-quickstart-guide
.NET: https://docs.min.io/docs/dotnet-client-quickstart-guide
Detected default credentials 'minioadmin:minioadmin', please change the credentals immediately using 'MINIO_ACCESS_KEY' and 'MINIO_SECRET_KEY'Le retour de la commande nous donne toutes les méthodes d'accès possibles.
Nous pouvons notamment voir que l’accès peut se faire depuis le web via le port 9000. Il est possible de changer le port par défaut en le précisant dans la ligne d'appel sous la forme http://192.168.1.200:9000.
Il est également précisé que l’identifiant et mot de passe par défaut est « minioadmin ». Il faudra bien sûr le changer.
Pour cela il suffit d'exporter les variables MINIO_ACCESS_KEY et MINIO_SECRET_KEY.
MINIO_SECRET_KEY doit faire minium huit caractères.
~# export MINIO_ACCESS_KEY=admin
~# export MINIO_SECRET_KEY=rootroot
~# ./minio server /data1
Attempting encryption of all config, IAM users and policies on MinIO backend
Endpoint: http://192.168.1.200:9000 http://127.0.0.1:9000
AccessKey: admin
SecretKey: rootroot
Browser Access:
http://192.168.1.200:9000 http://127.0.0.1:9000
Command-line Access: https://docs.min.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.200:9000 admin rootroot
Object API (Amazon S3 compatible):
Go: https://docs.min.io/docs/golang-client-quickstart-guide
Java: https://docs.min.io/docs/java-client-quickstart-guide
Python: https://docs.min.io/docs/python-client-quickstart-guide
JavaScript: https://docs.min.io/docs/javascript-client-quickstart-guide
.NET: https://docs.min.io/docs/dotnet-client-quickstart-guide8-5-3-1. Accès via le web▲
|
|
Le login et le mot de passe correspondent à l’accessKey et la SecretKey retourné par l’appel de min.io .
8-5-3-2. Gestion de fichiers depuis l'interface web▲
Une fois logué, vous obtiendrez l’écran suivant :
|
|
Il va nous falloir créer au moins un Bucket, entité de stockage de min.io, qui peut être considéré comme un dossier, ceci en cliquant sur le ![]() , puis « create Bucket » :
, puis « create Bucket » :
|
|
Après création, les Buckets apparaîtront sur la gauche (dans notre cas bucket1, puis bucket2) :
|
|
Lors de la création des Buckets, ceux-ci ne sont affichés dans l’ordre alphabétique qu’après rafraîchissement par clic sur l’adresse en bas à gauche.
La création d'un Bucket va créer un dossier du même nom dans le système de fichiers (dans le dossier /data1 dans notre cas). La création d'un dossier hors de l'interface va être vue comme un Bucket dans l'interface web.
Un sous-dossier créé en ligne de commande sera exploitable depuis l'interface web :
|
|
Il sera possible d'entrer dans le dossier, d'y uploader des fichiers. Par contre, il n’y a pas d'option dans l'interface web pour créer un sous-dossier.
La suppression d'un Bucket (un dossier) se fera en se mettant sur celui-ci et en cliquant sur les traits :
|
|
La suppression d'un Bucket va supprimer son contenu.
8-5-3-2-1. Upload de fichier▲
Pour uploader un fichier, il faut cliquer sur le ![]() , puis sur l’icône upload file
, puis sur l’icône upload file ![]()
Les fichiers apparaîtront sur le disque tels quels. Si vous ajoutez un fichier manuellement dans le dossier/Bucket, celui-ci sera disponible dans l'interface.
8-5-3-2-2. Accès aux fichiers▲
|
|
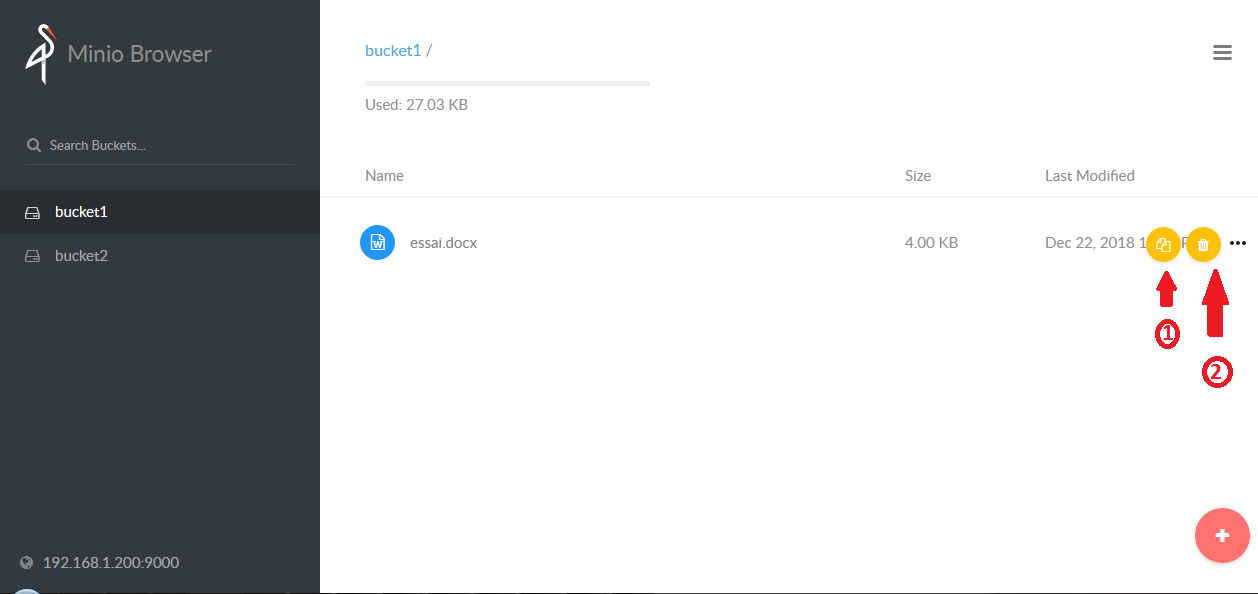
L’icône en 1 permet de créer un lien de partage dont la validité peut s’étendre jusqu’à sept jours. Il n’y a pas de possibilité de créer un lien permanent. L’icône 2 permet la suppression du document. Il n’y a pas de système de versionnage. Même si on peut utiliser un accès web, il s’agit d’un espace de stockage, pas d’un service de synchronisation de fichiers comme ceux déjà vus.
Il ne semble pas possible de renommer un fichier.
Il est possible de télécharger le fichier en cliquant sur le rond à gauche du nom. Une barre apparaîtra en haut de l’écran permettant le téléchargement (ainsi que la suppression comme avec l’icône vue sur l’écran précédent) :
|
|
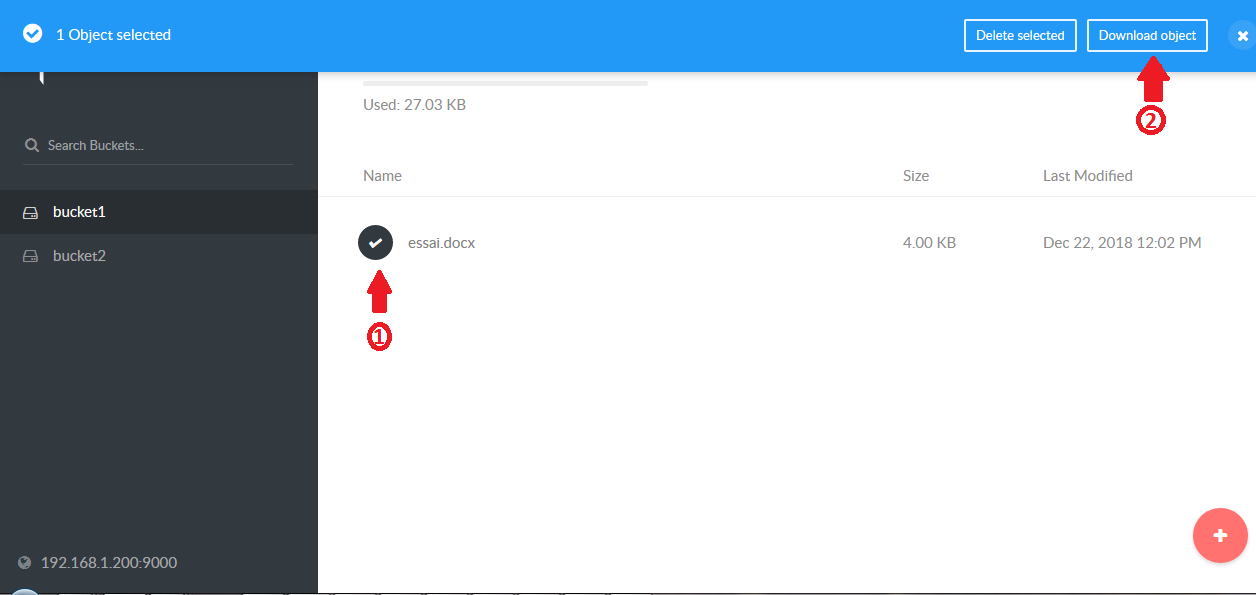
8-5-3-2-3. Utilisation de https▲
La clé privée (qui doit se nommer private.key) et la clé publique (qui doit se nommer public.crt) doivent être placées dans le dossier de configuration par défaut : .minio/certs (créé dans le dossier à partir duquel vous avez lancé min.io). Il est possible de préciser le chemin d'emplacement des clés avec l'option --cert.
La sécurisation de la connexion au serveur web de min.io est détaillée dans cette page de documentation : https://docs.min.io/docs/how-to-secure-access-to-minio-server-with-tls.html.
8-5-4. Test en mode distribué▲
Le mode distribué nécessite la déclaration d’au minimum quatre sources dont au moins deux accessibles. Il est possible de déclarer plusieurs sources sur le même nœud. Cela n'aura un sens qu'en cas de sources sur différents disques (un peu comme du RAID).
L’erasure code est un mécanisme permettant la redondance des données. Celui-ci utilise l’algorithme de Reed Salomon et permet de gérer l’espace utilisé pour la redondance. Par exemple : avec douze disques, vous pourrez utiliser six disques de données et six de parité ; ou bien dix disques de données et deux de parité. Plus vous avez de disques de parité, plus vous pourrez supporter de pertes de disques simultanés.
Pour créer un cluster distribué, nous préparons deux volumes data1 et data2 (sur deux disques différents) sur un même nœud.
Minio refusera de démarrer si les volumes déclarés sont sur le disque de démarrage.
Nous stockons l’AccessKey et la SecretKey dans les variables d’environnement (reprise des clés précédemment utilisées) :
export MINIO_ACCESS_KEY=XLI1NFFBHMAR5LFTTXD8
export MINIO_SECRET_KEY=+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzPuis appelons la commande :
./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4Qui retourne :
root@ubuntu:~# ./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4
Waiting for a minimum of 2 disks to come online (elapsed 3s)
Waiting for a minimum of 2 disks to come online (elapsed 6s)
Waiting for a minimum of 2 disks to come online (elapsed 9s)Il n'est pas possible de passer un volume précédemment démarré en mode unique sans effacer les métadonnées contenues dans le dossier .minio.sys présent dans le volume précédemment créé.
En mode distribué, l'utilisation de clés d'accès est obligatoire.
Nous voyons que le cluster attend la disponibilité d’au minimum deux disques pour démarrer.
Installons un second hôte.
Le second serveur devra être accessible en SSH sans demande de mot de passe.
Une fois l’exécutable minio copié, les volumes data1 et data2 préparés, puis les variables MINIO_ACCESS_KEY et MINIO_SECRET_KEY positionnées, au 1er lancement sur le second hôte, nous verrons :
root@ubuntu:~# ./minio server http://192.168.1.200/data1 http://192.168.1.200/data2 http://192.168.1.201/data3 http://192.168.1.201/data4
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Waiting for the first server to format the disks.
Status: 4 Online, 0 Offline.
Endpoint: http://192.168.1.201:9000 http://127.0.0.1:9000
AccessKey: XLI1NFFBHMAR5LFTTXD8
SecretKey: +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Browser Access:
http://192.168.1.201:9000 http://127.0.0.1:9000
Command-line Access: https://docs.minio.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://192.168.1.201:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Object API (Amazon S3 compatible):
Go: https://docs.minio.io/docs/golang-client-quickstart-guide
Java: https://docs.minio.io/docs/java-client-quickstart-guide
Python: https://docs.minio.io/docs/python-client-quickstart-guide
JavaScript: https://docs.minio.io/docs/javascript-client-quickstart-guide
.NET: https://docs.minio.io/docs/dotnet-client-quickstart-guideLa commande minio doit donc être lancée sur les deux machines.
8-5-4-1. Tests▲
Depuis l’interface web, nous créons ensuite deux buckets et uploadons quelques fichiers dans chaque bucket.
Nous pouvons ensuite observer la présence d’un dossier par bucket dans /data1 et dans /data2, sur les deux hôtes. La réplication s’effectue entre les deux disques locaux et sur les deux hôtes. Nous avons donc quatre exemplaires visibles, répartis sur deux hôtes.
Nous pouvons également observer que chaque fichier uploadé se présente sous forme d'un dossier portant le nom du fichier et contenant un fichier part.1 (ou, selon la taille, plusieurs fichiers part.x) dans un dossier avec un nom représentant un UUID, et un fichier xl.meta. Le fichier part.1 n’est pas exploitable. L’accès aux fichiers n’est donc pas possible sans passer par l’interface web.
8-5-4-2. Passage en mode démon▲
Nous allons installer minio en mode démon. Nous commençons par fixer les variables dans le fichier /,etc/default/minio :
MINIO_VOLUMES=https://192.168.1.200/data1 https://192.168.1.201/data1 https://192.168.1.202/data1 https://192.168.1.203/data1
MINIO_ACCESS_KEY=XLI1NFFBHMAR5LFTTXD8
MINIO_SECRET_KEY=+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzNous allons ensuite utiliser le script de laudukang :
[Unit]
Description=Minio
Documentation=https://docs.minio.io
Wants=network-online.target
After=network-online.target
AssertFileIsExecutable=/usr/local/bin/minio
[Service]
WorkingDirectory=/usr/local
User=root
Group=root
PermissionsStartOnly=true
EnvironmentFile=-/etc/default/minio
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_VOLUMES}\" ]; then echo \"Variable MINIO_VOLUMES not set in /etc/default/minio\"; exit 1; fi"
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_ACCESS_KEY}\" ]; then echo \"Variable MINIO_ACCESS_KEY not set in /etc/default/minio\"; exit 1; fi"
ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_SECRET_KEY}\" ]; then echo \"Variable MINIO_SECRET_KEY not set in /etc/default/minio\"; exit 1; fi"
ExecStart=/usr/local/bin/minio server $MINIO_OPTS $MINIO_VOLUMES
# Let systemd restart this service only if it has ended with the clean exit code or signal.
Restart=on-success
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop Minio
KillSignal=SIGTERM
SendSIGKILL=no
SuccessExitStatus=0
[Install]
WantedBy=multi-user.target
# Built for ${project.name}-${project.version} (${project.name})Nous pouvons voir que le démon attend la commande minio dans /usr/local/bin et en utilisateur root, ce que vous pouvez changer si vous le souhaitez. Nous pouvons également voir que le script récupère les variables dans /,etc/default/minio.
Nous plaçons donc le script dans le fichier /etc/systemd/system/minio.service avec les droits 755.
Nous enregistrons ensuite le service :
systemctl daemon-reload
systemctl enable minioCe qui renvoie :
Created symlink from /etc/systemd/system/multi-user.target.wants/minio.service to /etc/systemd/system/minio.service.
root@ubuntu:~#Nous arrêtons ensuite min.io sur les deux machines et lançons le service sur les deux hôtes, après avoir effectué la copie des fichiers de configuration d'une machine à l'autre.
Pour utiliser le mode https, il faudra ajouter la ligne suivante :
MINIO_OPTS= "-C /,etc/minio"puis copier les clés .key et .crt dans le dossier /,etc/minio/certs.
8-5-5. Client min.io▲
Pour accéder aux buckets min.io depuis la ligne de commande, nous pouvons utiliser le client min.io nommé mc (ne pas confondre avec Midnight Commander) téléchargeable à l’adresse :
https://dl.min.io/client/mc/release/linux-amd64/mc
Un simple appel sans paramètres donnera la liste des options :
~# ./mc
mc: Configuration written to `/root/.mc/config.json`. Please update your access credentials.
mc: Successfully created `/root/.mc/share`.
mc: Initialized share uploads `/root/.mc/share/uploads.json` file.
mc: Initialized share downloads `/root/.mc/share/downloads.json` file.
NAME:
mc - Minio Client for cloud storage and filesystems.
USAGE:
mc [FLAGS] COMMAND [COMMAND FLAGS | -h] [ARGUMENTS...]
COMMANDS:
ls list buckets and objects
mb make a bucket
cat display object contents
pipe stream STDIN to an object
share generate URL for temporary access to an object
cp copy objects
mirror synchronize object(s) to a remote site
find search for objects
sql run sql queries on objects
stat show object metadata
diff list differences in object name, size, and date between two buckets
rm remove objects
event configure object notifications
watch listen for object notification events
policy manage anonymous access to buckets and objects
admin manage minio servers
session resume interrupted operations
config configure minio client
update update mc to latest release
version show version info
GLOBAL FLAGS:
--config-dir value, -C value path to configuration folder (default: "/root/.mc")
--quiet, -q disable progress bar display
--no-color disable color theme
--json enable JSON formatted output
--debug enable debug output
--insecure disable SSL certificate verification
--help, -h show help
--version, -v print the version
VERSION:
RELEASE.2018-12-27T00-37-49ZNous reconnaissons les commandes classiques du shell.
Nous commençons par créer un alias pour faciliter l’accès, et comme indiqué lors de l’appel à la commande minio server :
mc config host add minioalias http://192.168.1.200:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzCe qui retourne :
mc: Configuration written to `/root/.mc/config.json`. Please update your access credentials.
mc: Successfully created `/root/.mc/share`.
mc: Initialized share uploads `/root/.mc/share/uploads.json` file.
mc: Initialized share downloads `/root/.mc/share/downloads.json` file.
Added `minioalias` successfully.Nous pouvons consulter le contenu de l’hôte via la commande mc ls suivi du nom de l’alias :
~# ./mc ls minioalias
[2018-12-27 13:49:34 CET] 0B dossier1/
[2018-12-27 13:49:51 CET] 0B dossier2/
~#La commande cp permettra de copier des fichiers dans le cluster ou d’en récupérer depuis celui-ci.
Il n’y a pas de notion de sous-dossier avec min.io. Par contre, si vous copiez le fichier fichier.txt avec la commande suivante :
./mc cp fichier.txt minioalias/dossier1/textes/fichier.txtvous pourrez voir l’arborescence texte.
Si vous copiez plusieurs fichiers dans le chemin minioalias/dossier1/textes, vous pourrez les voir avec la commande ./mc ls minioalias/dossier1/textes.
8-5-6. Fonctionnement en mode S3▲
Pour cet usage, j’ai testé s3fs qui permet de monter un volume S3 avec FUSE.
Il va nous falloir créer un fichier /etc/passwd-s3fs pour la connexion de la forme identifiant:clé
Dans notre cas, ce sera :
XLI1NFFBHMAR5LFTTXD8:+4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmzEnsuite, le volume peut être monté avec s3fs :
s3fs <nom du bucket> /mnt -o use_path_request_style,url=http://192.168.1.200:9000À partir de ce point de montage, le Bucket est accessible comme n’importe quel autre point de montage.
8-5-7. Sauvegarde▲
Pour les sauvegardes, le plus simple est de sauvegarder depuis un point de montage s3fs.
8-5-8. Test d’arrêt d’un des serveurs▲
Lors de l’arrêt d’un des serveurs, les données restent accessibles, mais en lecture seule. Après redémarrage du serveur, la situation se débloque.
8-5-8-1. Perte définitive d’un serveur▲
La situation ne revient pas à la normale même si vous préparez un nouveau serveur en copiant les fichiers /usr/local/bin/minio, /,etc/default/minio, recréant les points de montages data1 et data2.
Je commence par créer un alias pour la commande mc pointant sur le serveur fonctionnel :
~# ./mc config host add minioalias http://192.168.1.200:9000 XLI1NFFBHMAR5LFTTXD8 +4tHexZ4EUU0Ltbo1gQVfTJ6bFcGTZGtRqYNHpmz
Added `minioalias` successfully.Je lance la réparation avec la commande ./mc admin heal minioalias :
~# ./mc admin heal minioalias
◓ dossier2
0/0 objects; 0 B in 3s
┌────────┬───┬─────────────────────┐
│ Green │ 4 │ 100.0% ████████████ │
│ Yellow │ 0 │ 0.0% │
│ Red │ 0 │ 0.0% │
│ Grey │ 0 │ 0.0% │
└────────┴───┴─────────────────────┘Ceci va recréer l’arborescence, mais ne suffira pas pour les fichiers
Il faudra ajouter la commande ./mc admin heal minioalias --recursive.
Vous verrez défiler le nom des fichiers, la console restant sur le dernier fichier synchronisé.
~# ./mc admin heal minioalias --recursive
◐ dossier2/pydio.pdf
7/7 objects; 2 MiB in 6s
┌────────┬────┬─────────────────────┐
│ Green │ 11 │ 100.0% ████████████ │
│ Yellow │ 0 │ 0.0% │
│ Red │ 0 │ 0.0% │
│ Grey │ 0 │ 0.0% │
└────────┴────┴─────────────────────┘8-5-9. Ajout de serveur▲
Pour ajouter un serveur supplémentaire, il faudra modifier le fichier /,etc/default/minio sur les deux serveurs existants (ajout dans la ligne MINIO_VOLUMES= du fichier /,etc/default/minio).
8-6. Bilan▲
GlusterFS est une solution souple et relativement simple. Je n'utiliserais pas la méthode DRBD/OCFS, car la désynchronisation est trop facile, et la nouvelle version, paraissant plus souple, m'a posé des difficultés (mais il s'agit ici d'un point de vue personnel).
La solution Ceph est complexe, mais offre l’avantage de s'autoréparer en cas de problème. Ceph est adapté aux solutions à grande échelle et est utilisé par OpenStack, OpenNebula. Elle reste complexe à mettre en place, mais fait référence.
8-7. Quid de Windows ?▲
Il est possible de gérer un système de fichiers distribués avec Windows via un Active Directory en utilisant DFSR (Distributed FileSystem Replication).
DFS permet de faire de la répartition de données (une partie sur chaque serveur, vue à partir d’un seul point d'accès) ou de la redondance en répliquant les données d'un serveur à un autre.
Il faudra sur un Windows Server avec Active Directory fonctionnel installer le rôle « Réplication DFS », puis depuis le menu outil du gestionnaire de serveurs aller dans « Gestion du système de fichiers distribués DFS ».
Dans le gestionnaire DFS qui va s'ouvrir, il va falloir faire un clic droit sur Espace de noms→ Nouvel espace de noms.
Une fois l'espace de nom créé, il faudra ajouter les dossiers cibles de chaque serveur.
Vous pourrez sélectionner une réplication en temps réel ou planifier la fréquence.
8-8. Quid de Mac OS X ?▲
Mac OS X ou mac OS Server ne proposent aucun système de fichiers distribués. Il pourra se connecter à un DFS Active Directory.
Pour se référer à ce qui a été vu dans ce tutoriel, GlusterFS n'est actuellement pas compatible Mac OS.
Il est possible de compiler Ceph via Homebrew, mais cela me parait trop expérimental pour une utilisation en production.
9. Centralisation de la gestion des accès▲
Pour gérer la centralisation des accès, c’est-à-dire des identifiants et des mots de passe, j'ai testé NIS et LDAP.
9-1. Installation de NIS▲
Network Information Service (NIS) est aussi connu sous le nom de Yellow Pages. Le service permet de distribuer les différents fichiers de configuration tels que /,etc/hosts /,etc/password sur différentes machines via le réseau. Ceci permet la recopie automatique des mots de passe et configurations entre différents hôtes. NIS est spécifique au monde Unix/Linux.
Dans notre exemple, nous fixerons le nom de notre première machine sur srv1.
Nous installons NIS :
apt-get install nisil vous sera demandé le domaine NIS, nous utiliserons « cloudsrv ».
L'installation reste bloquée un moment sur :
Paramètrage de nis ...mais finit par aboutir.
Avant toute chose, pour sécuriser le service, nous modifions le fichier /etc/ypserv.securenets et créons un fichier /var/yp/securenets, dans lequel nous n’autorisons que notre serveur et une seconde machine 192.168.1.200 qui sera utilisée dans les prochains tests :
host 127.0.0.1
host 192.168.1.200
host 192.168.1.201Nous modifions ensuite le fichier /,etc/default/nis et remplaçons la ligne
NISSERVER=falsepar :
NISSERVER=masterNous redémarrons ensuite le serveur :
service nis restartNous initialisons ensuite la base de données :
/usr/lib/yp/ypinit -mVous devez ensuite entrer la liste des serveurs, terminée par Ctrl-D. Nous n'avons que le serveur local actuellement.
9-1-1. Ajout d'un client NIS▲
Nous installons NIS sur la machine qui nous servira de client via apt-get install nis. Nous entrons le même domaine NIS que pour la première machine : cloudsrv. Ce serveur sera appelé srv2.
Il va nous falloir ensuite modifier le fichier /etc/nssswitch.conf et ajouter « nis » à la fin des lignes passwd, group, shadow (et des autres lignes si vous le souhaitez) :
passwd: compat nis
group: compat nis
shadow: compat nisCela va permettre de rechercher les informations dans la base NIS en plus des fichiers standards.
9-1-1-1. Test de connexion à un compte de test▲
J'ai fait une tentative de connexion avec un compte de test présent sur srv1 avant installation de NIS (et non présent sur srv2, le client).
La connexion fonctionne, avec le message :
Pas de répertoire, connexion avec HOME=/Ce qui est logique, le dossier home de l'utilisateur n'existant que sur srv1. NIS recopie le fichier de mots de passe /,etc/passwd, mais ne va pas créer le dossier home sur un autre poste.
9-1-1-2. Test de changement de mot de passe▲
Je tente de modifier le mot de passe depuis srv2 avec la commande passwd.
Ceci me retourne :
passwd : Erreur de manipulation du jeton d'authentification
mot de passe non changé.Il n'est possible de modifier le mot de passe que depuis le serveur NIS.
Par contre, si vous modifiez le mot de passe sur le serveur, il faut ensuite lancer la commande :
cd /var/yp
make
make[1] : Entering directory '/var/yp/cloudsrv'
Updating passwd.byname...
Updating passwd.byuuid...
Updating netid.byname...
Updating shadow.byname... Ignored -> merged with passwd
make[1] : Leaving directory '/var/yp/cloudsrv'Pourquoi ? Car NIS ne travaille pas directement avec les fichiers, etc/passwd, /,etc/group, etc., mais avec ses propres fichiers qui sont synchronisés avec la commande /var/yp/make.
9-1-1-3. Ajout/suppression d'utilisateur▲
La règle est la même pour l'ajout et la suppression d’un utilisateur. Il faut faire l'opération avec les commandes habituelles et appeler : /var/yp/make.
9-1-2. Ajout d’un serveur secondaire▲
Nous allons transformer srv2 en serveur NIS secondaire, nommé slave.
Cela est très simple, il suffit de modifier les lignes suivantes de /,etc/default/nis :
Je vais remplacer :
NISSERVER=par :
NISSERVER=slaveet :
NISMASTER=par :
NISMASTER=srv1Ce dernier paramètre permettant de lancer ypinit à chaque démarrage de serveur (pour mettre à jour la synchronisation).
9-1-3. Conclusion▲
L'arrêt du serveur master (srv1), et le passage du serveur slave en master ne m'a pas permis de m'authentifier avec un compte créé sur srv1.
NIS n'étant pas sécurisé (il reste possible d'ajouter un serveur Kerberos avec) et en voie d’abandon, je ne suis pas allé plus loin dans mes tests.
9-2. LDAP▲
Lightweight Directory Access Protocol (LDAP) est une référence dans les services d’annuaire. Celui-ci permet à la plupart des serveurs (au sens logiciel) d'avoir une base de données centralisée incluant les utilisateurs, éventuellement leurs coordonnées, des machines, des ressources, etc. Active Directory de Windows Server s'appuie sur LDAP, la plupart des serveurs SMB, serveurs mails, serveurs d'impression, copieurs, peuvent s'authentifier à travers LDAP. Il est possible de s'authentifier sous Linux via LDAP également (ce que nous allons voir).
Sur une base LDAP vient se greffer des schémas. Ceux-ci vont définir des objets et des attributs venant s'intégrer dans la base LDAP. Des démons vont fournir des schémas pour intégrer des objets ou attributs à la base LDAP qu'ils vont ensuite utiliser.
Il est possible d'importer et d'exporter des données depuis un annuaire LDAP via des fichiers .ldif (LDAP Data Interchange Format).
LDAP est à mon avis difficile à prendre en main. C'est par contre la solution pour centraliser une authentification depuis plusieurs briques logicielles différentes. Il est également possible d'avoir un serveur de réplication, ce qui est dans le cadre de ce tutoriel indispensable pour assurer la redondance.
Les termes les plus courants utilisés par LDAP sont :
- dc: Domain Component ;
- dn: Distinguished Name ;
- cn: Common Name ;
- ou: Organisational unit.
Et voici un schéma sur l'organisation :
dc=FR
|
dc=EXEMPLE
/ \
ou=machines ou=personnes
/ \
cn=ordinateur cn=JeanCeci aboutissant à deux Distinguished Names :
- cn=ordinateur,ou=machines,dc=EXEMPLE,dc=FR
9-2-1. Installation▲
Nous allons installer l’implémentation OpenLDAP via le paquet slapd (Stand-alone LDAP Daemon).
apt-get install slapdIl vous sera demandé un mot de passe administrateur.
Nous configurons ensuite le service :
dpkg-reconfigure slapdLe premier écran vous demande si vous voulez « omettre la configuration », il faut donc répondre « non » pour effectuer celle-ci :
|
|
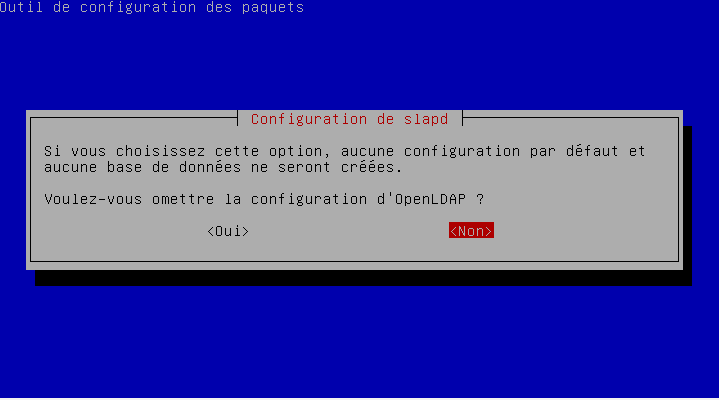
Nous allons ensuite entrer le « nom de domaine » LDAP. Dans l'exemple je vais utiliser developpez.com.
|
|
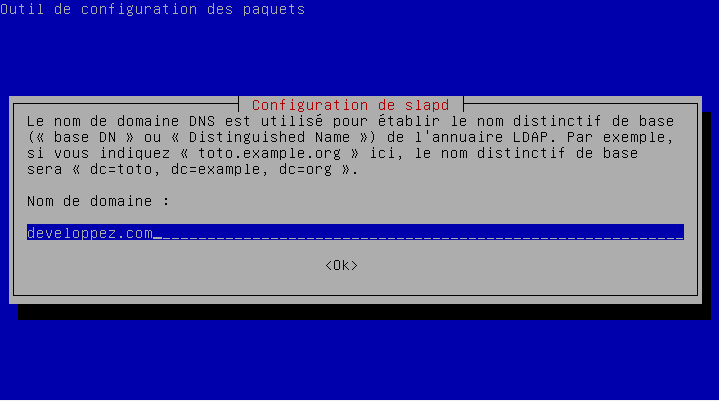
Le second écran demande le nom de l'organisation, je saisis « developpez »
|
|
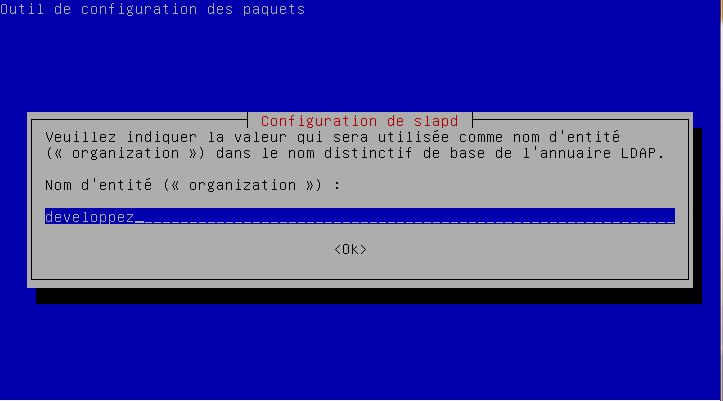
On vous demandera ensuite le mot de passe administrateur, ce qui est normal, car nous créons une nouvelle base. L'écran suivant demande le format de base de données à utiliser, nous laissons le choix proposé : MDB.
|
|
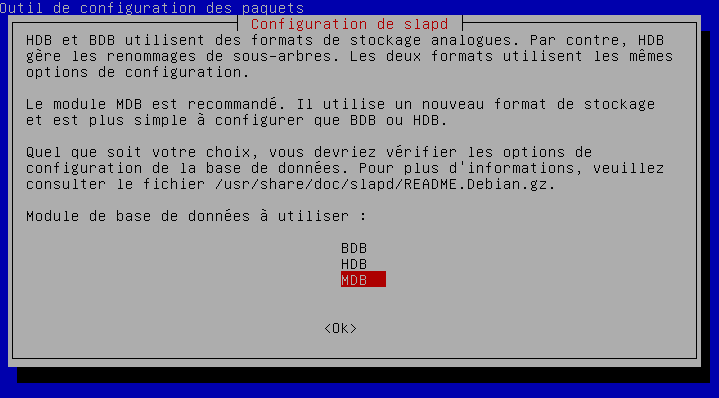
L'écran suivant demande s’il faut supprimer la base en cas de désinstallation de LDAP, et s’il faut déplacer l'ancienne base. Comme celle-ci est vide, nous pouvons répondre « non ».
9-2-2. Installation de LAM (LDAP Account Manager)▲
Pour éviter de devoir utiliser des lignes de commande intégrant des fichiers .ldif pour l'ajout d'utilisateurs, nous allons utiliser LAM (LDAP Account Manager) qui permet de piloter la base LDAP depuis un navigateur web.
Il est tout à fait possible de se passer de LAM et d'utiliser des fichiers .ldif et les commandes Shell. Ce tutoriel ciblera uniquement l'utilisation de LAM.
Pour installer LAM :
apt-get install ldap-account-managerAvant d'aller plus loin, nous allons commencer par activer le support de HTTPS. Si vous avez ajouté LAM sur une machine possédant déjà Apache avec un certificat, vous pouvez modifier directement le fichier VirtualHost. Sinon il va vous falloir installer un certificat ou en créer un autosigné.
Pour la création d'un certificat autosigné :
openssl req -new -x509 -days 365 -nodes -out /ets/ssl/certs/lam.crt -keyout /etc/ssl/private/lam.keyNous activons ensuite le module SSL d'Apache :
a2enmod sslModification de la configuration de LAM :
il va falloir éditer le fichier /etc/apache2/conf-enabled/ldap-account-manager.conf.
Nous entourons le contenu avec une balise <Virtualhost> et ajoutons les éléments de configuration SSL :
<VirtualHost *:443>
SSLEngine on
SSLCertificateFile /etc/ssl/certs/lam.crt
SSLCertificateKeyFile /etc/ssl/private/lam.key
… contenu original
</VitualHost>Nous redémarrons Apache :
service apache2 restartÀ ce stade, vous pourrez appeler LAM avec http://[adresse ip/nom DNS]/lam ou https://[adresse ip/nom DNS]/lam.
Il restera à éventuellement modifier la configuration pour forcer le passage en HTTPS.
Lors de la connexion, vous aurez l'écran suivant :
|
|
En lançant l'interface web, j'ai eu des messages d'erreur indiquant l'absence de support du XML et de zip avec ma version de PHP. Pour régler ce souci, il faut installer les paquets php-xml et php-zip et redémarrer Apache.
Passons à la configuration de LAM. Nous cliquons sur « Configuration de LAM » en haut à droite :
|
|
|
|
Il va nous falloir aller dans « modifier les profils » :
|
|
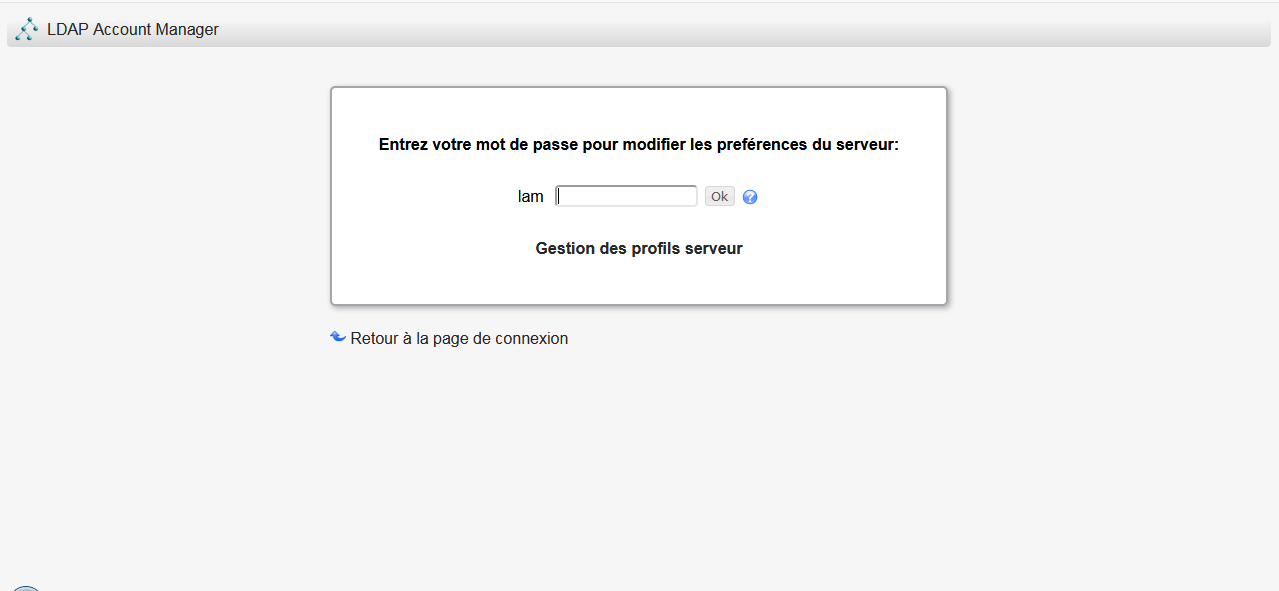
Le mot de passe par défaut est « lam », la première chose à faire est de le changer :
|
|

Ceci va changer le mot de passe de l'édition de profil. Nous allons ensuite créer un nouveau profil :
Configuration de LAM → Modifier les profils → Gestion des profils serveur :
|
|
.png)
Nous ajoutons un nouveau profil :
|
|
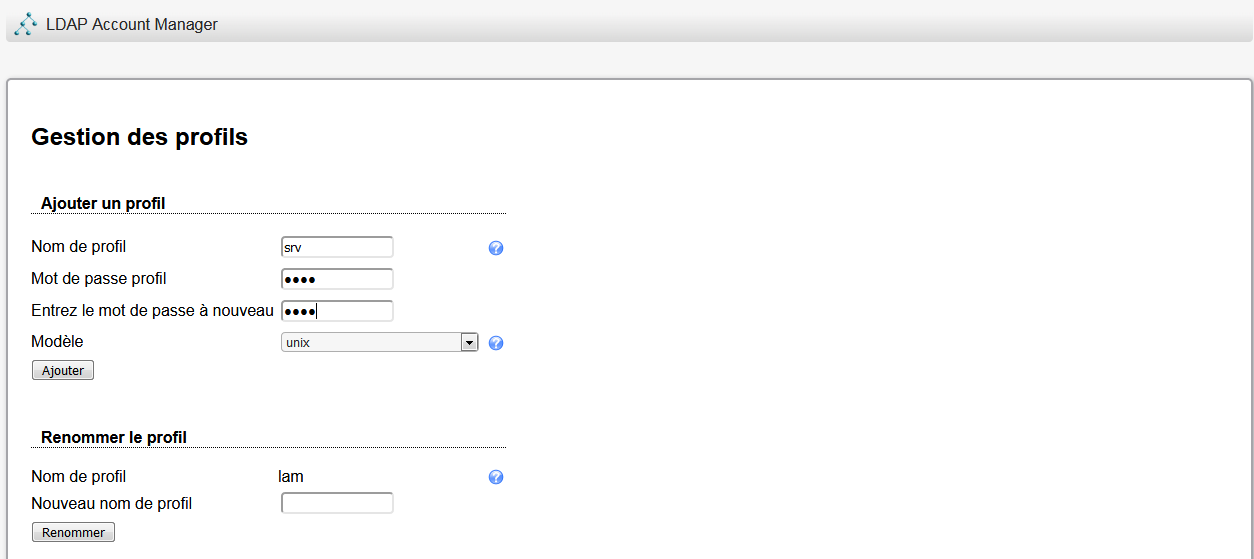
Il vous faudra entrer le mot de passe principal renseigné auparavant :
|
|
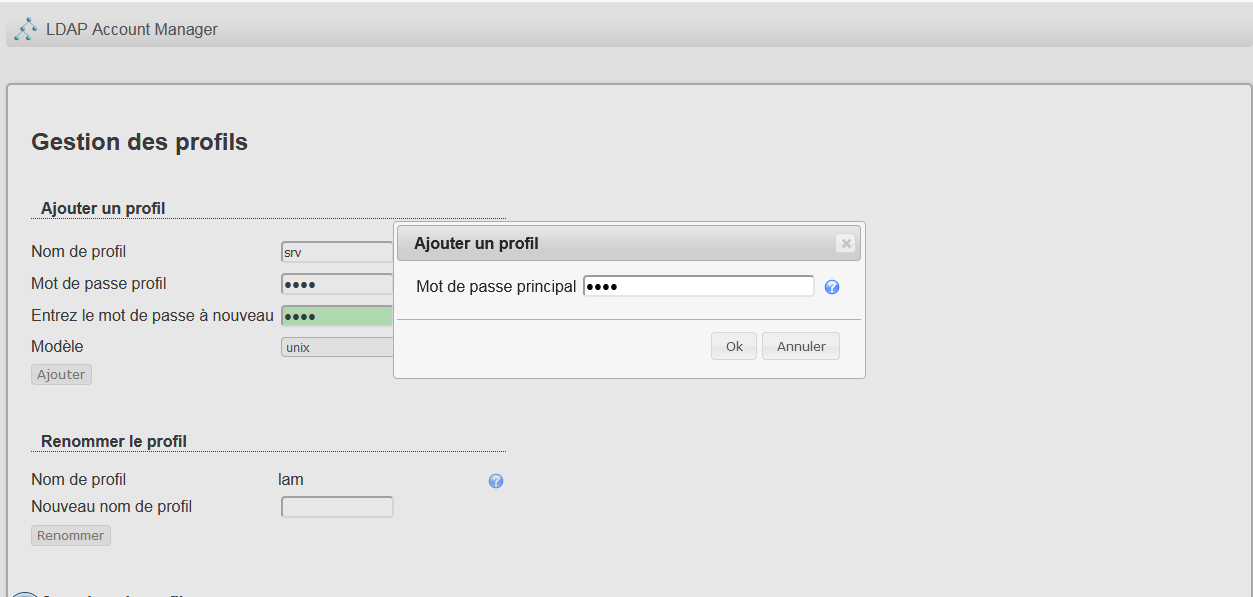
Nous passerons directement sur l'écran de configuration du nouveau profil :
|
|
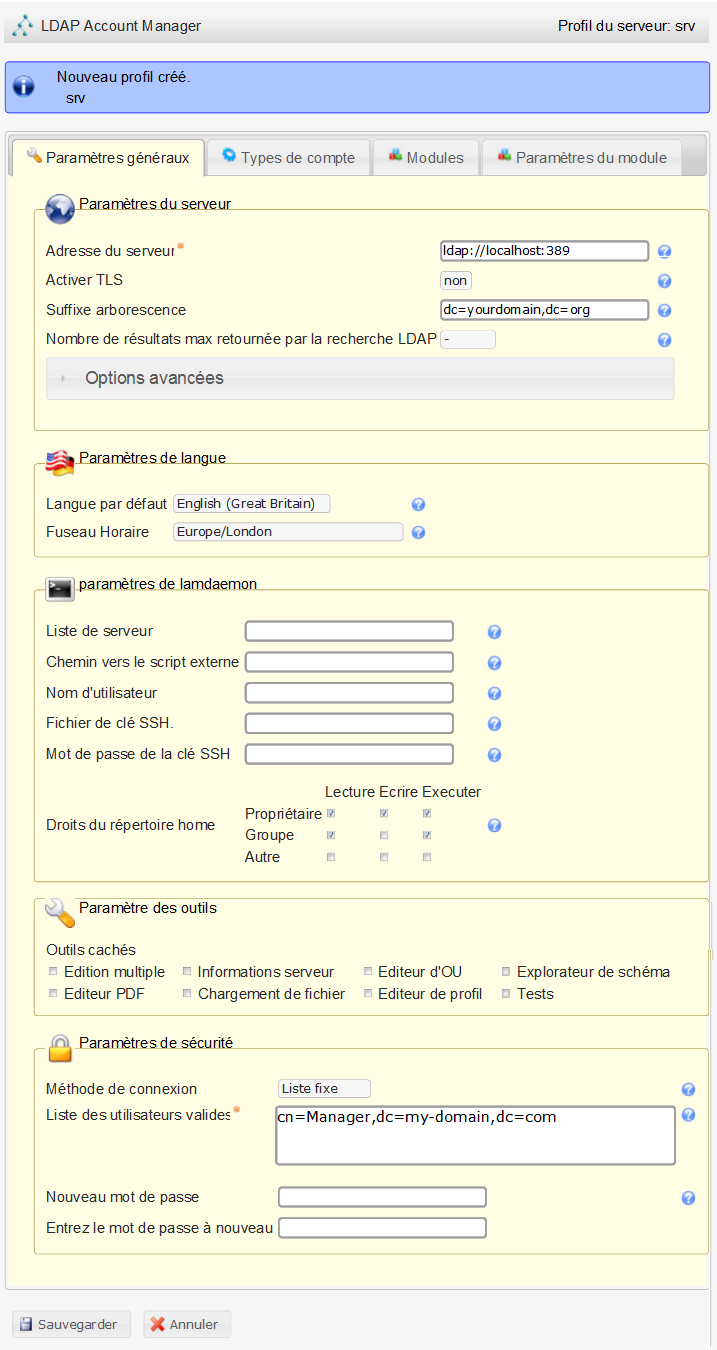
Il va nous falloir effectuer les réglages suivants :
- suffixe d'arborescence : remplacer dc=yourdomain,dc=org par dc=developpez,dc=com (le domaine que nous avions paramétré étant developpez.com) ;
- paramètre de langue : sélection du langage par défaut ainsi que du fuseau horaire ;
- paramètres de sécurité-->liste des utilisateurs valides : remplacer cn=Manager,dc=my-domain,dc=com par cn=admin,dc=developpez,dc=com. (admin est l'utilisateur administrateur par défaut sur un serveur LDAP) ;
- puis le mot de passe.
Avant de valider, il va falloir effectuer des modifications dans l'onglet type de compte :
|
|
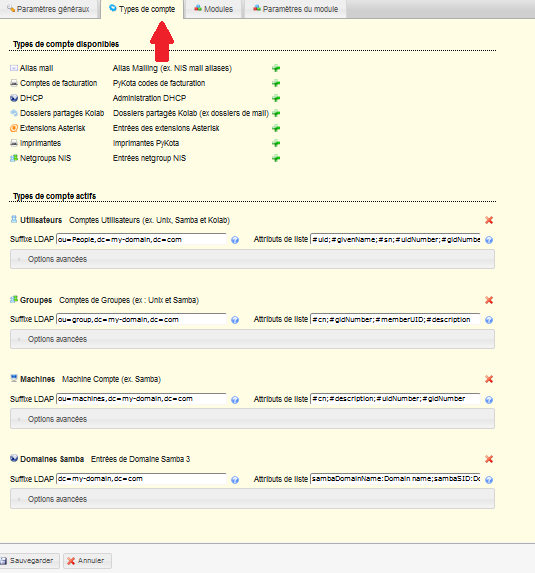
Il faut modifier les champs dc= des suffixes LDAP, pour les utilisateurs, les groupes, les machines, et les domaines Samba. Nous n'utiliserons que les suffixes utilisateurs (ou=People) et groupe (ou=group), mais fixons correctement les entrées machines et Samba, en cas d'utilisation ultérieure. Nous mettons dc=developpez,dc=com.
Une fois tous ces éléments entrés, vous pourrez vous connecter :
|
|
.png)
Pensez à retourner dans le gestionnaire de profil afin de supprimer le profil lam.
Lors de la première connexion, vous verrez l'écran suivant :
|
|
Si les éléments sont corrects, cliquez sur « Créer ». Vous aurez le message « Modifications effectuées avec succès ».
Il va nous falloir créer un groupe, sans quoi nous ne pouvons pas créer d’utilisateurs :
|
|
|
|
Je crée un groupe nommé « users ».
|
|
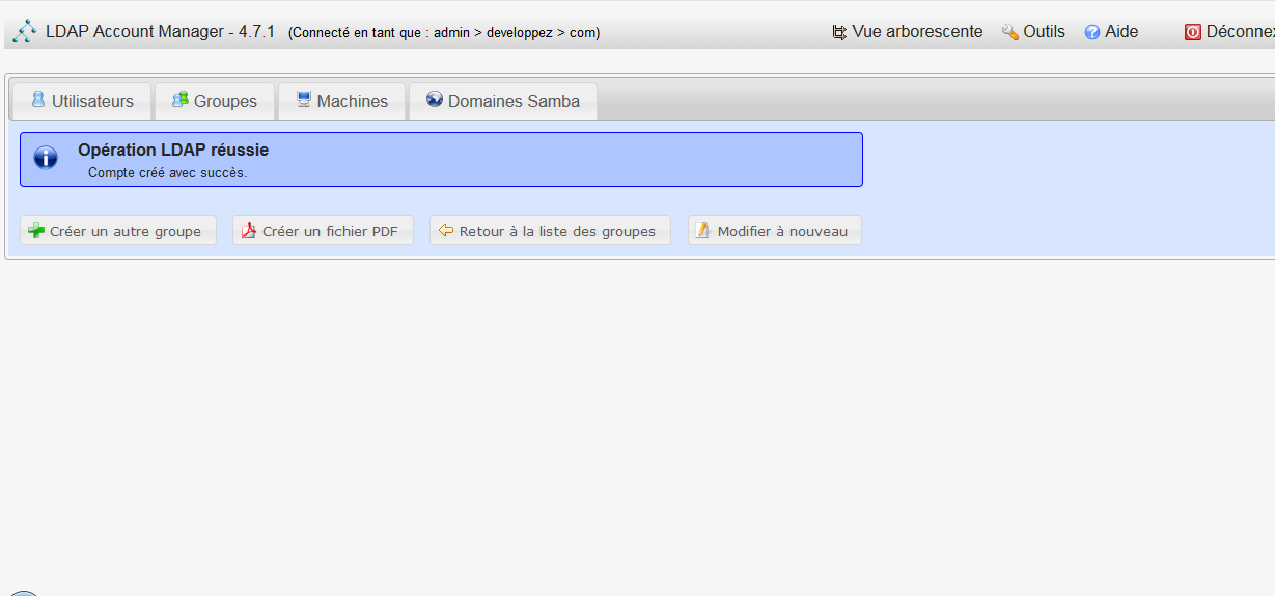
Nous voyons que l'opération est réussie, mais ne voyons pas le groupe. Un clic sur Groupes rafraîchira la page et nous verrons le groupe.
|
|
Nous créons ensuite un utilisateur « test ».
|
|
Beaucoup de champs sont à notre disposition, nous n'utiliserons que le champ nom (champ obligatoire).
Nous allons permettre plus tard une authentification Unix depuis ce compte (pour nos tests), il va falloir cliquer sur le bouton « Unix » à gauche. Vous verrez que le champ répertoire utilisateur est positionné sur /home/$user, le chemin normal des comptes utilisateurs dans une arborescence Unix, $user étant bien entendu remplacé par le nom de l'utilisateur. Si vous ne souhaitez pas qu'un utilisateur puisse lancer un Shell, il faudra positionner le champ Shell de connexion sur false.
Il vous faudra ensuite cliquer sur le bouton définir le mot de passe pour positionner celui-ci.
|
|
Et ensuite, dernière étape, enregistrer le compte en cliquant sur le bouton Sauvegarder.
En cliquant sur Vue arborescente en haut, vous aurez comme le nom l’identique, une vue arborescente, mais vous pourrez également importer et exporter des fichiers .ldif, et exporter également aux formats csv et vcard.
9-2-3. Authentification Linux avec une base LDAP▲
PAM (Pluggable Authentication Modules) est l'API utilisée sous Linux permettant de déléguer l'authentification à plusieurs services différents (LDAP, NIS, bases de données au format Berkeley, etc.). Cette API nous permettra d'effectuer une authentification transparente avec un utilisateur de notre annuaire LDAP. Nous nous authentifierons avec un compte LDAP avec la simple commande login. nssswitch (Name Service Switch) va travailler en collaboration avec le service PAM pour se substituer ou modifier les fichiers de configuration password, shadow, hosts, aliases.
Nous aurons besoin pour cela du paquet libnss-ldapd et ses dépendances :
apt-get install libnss-ldapdLe premier écran demandera l'adresse du serveur LDAP, nous remplaçons l'URL ldapi:// par ldap://127.0.0.1 pour une utilisation locale, et l'adresse IP du serveur depuis un poste client.
|
|
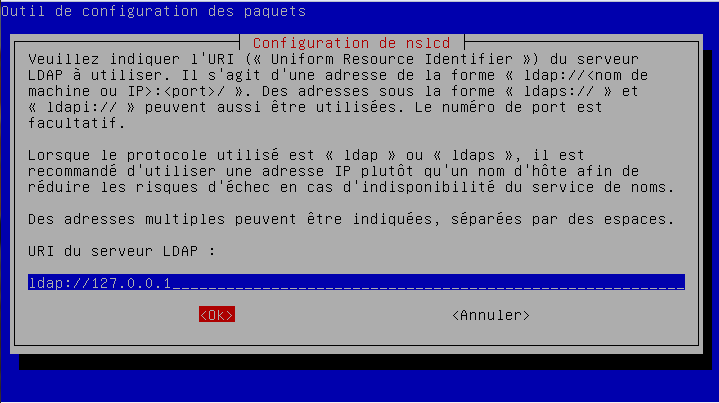
Sur le prochain écran, il faudra entrer le dn utilisé, soit : dc=developpez,dc=com :
|
|
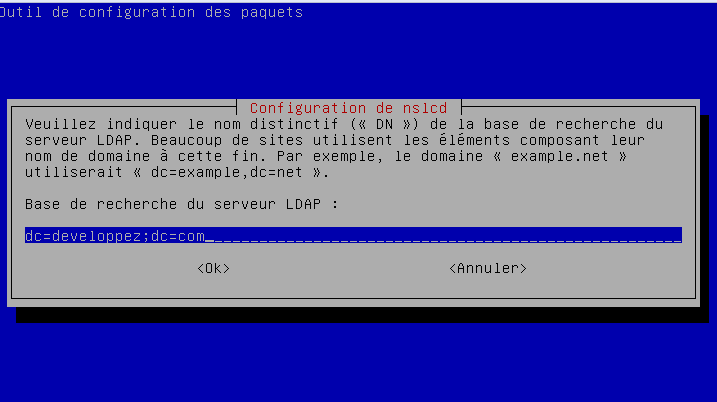
Le paquet vous demande les services à activer, il faudra au minimum cocher password et shadow.
|
|
Une fois la configuration effectuée, vous pourrez vous loguer depuis la console avec le compte « test ».
Une fois logué, vous vous trouverez à la racine. Le dossier utilisateur n'a pas été créé. lam ne crée pas automatiquement celui-ci. Dans le cadre de notre tutoriel, cela est très bien. Si vous souhaitez gérer cela, consulter la documentation de lam.
Si vous changez le mot de passe avec la commande passwd, celui mettra bien à jour le compte ldap :
Une fois l'authentification LDAP activée, il ne sera toujours pas possible de s'authentifier avec le compte root local. LAM ne vous laissera pas créer un compte avec un UID inférieur à 10 000, empêchant la création d'un compte root dans LDAP.
Si vous souhaitez ajouter un compte, en cas d'utilisation de la commande adduser, vous pourrez constater que le compte est créé en local et non dans la base LDAP. Pour ajouter un utilisateur LDAP, il faut utiliser la commande lpadadd avec en paramètre un fichier ldif, d’où l’intérêt d'utiliser LAM pour simplifier l'opération.
La création d'un compte utilisateur LDAP ne déclenche pas la création du dossier de l'utilisateur. Ceci peut être fait en ajoutant la ligne suivante au fichier /etc/pam.d/common-session :
session required pam_mkhomedir.so skel=/,etc/skel umask=00229-2-4. Authentification Mac OS avec une base LDAP▲
Mac OS permet de s'authentifier sur une base LDAP. La procédure est documentée ici. Mac OS peut se connecter sur un Active Directory et intègre dans sa version serveur Open Directory proposant des services similaires à Active Directory. Utiliser spécifiquement un serveur LDAP pour gérer la connexion utilisateur me parait faiblement justifié. Par ailleurs, les services tels qu'un serveur SMB ou serveur mail distant peuvent gérer de leur côté une authentification LDAP, transparente pour le client.
9-2-5. Authentification Windows sur un serveur LDAP▲
Aspect serveur
Il est possible de faire agir un contrôleur de domaine comme un serveur LDAP à l'aide du service ADLDS (Active Directory Lightweight Directory Service). Cela peut être utilisé pour un produit compatible LDAP, mais non compatible AD.
Aspect client
Windows ne permet pas nativement la connexion à un serveur LDAP. Ceci est justifié par l’existence d'Active Directory. Il n'est possible de se connecter sur un AD qu'avec une version Windows Pro. Si vous êtes sur une version Home, vous pourrez vous connecter sur un dossier partagé par un serveur Windows, mais ne pourrez pas bénéficier de la centralisation d'administration apportée par Active Directory.
Il existe un produit libre nommé pgina qui permet une authentification LDAP (ainsi que d'autres connexions de type MySQL par exemple via des plugins).
9-2-6. Sauvegarde restauration LDAP▲
9-2-6-1. Par copie des fichiers▲
Il faudra arrêter le service et copier les fichiers de configuration présents dans /,etc/ldap, et les fichiers de base dans /var/lib/ldap.
Ces fichiers devront être restaurés à leur endroit respectif.
9-2-6-2. Par import/export LDIF▲
L'export se fera par la commande :
slapcat -b rootsuffix -l fichier.ldifL'import par :
slapadd -c -b suffixroot -l fichier.ldifLe service ldap doit être préalablement stoppé.
Exemple de suffixroot : dc=exemple,dc=com.
9-2-7. Serveur secondaire LDAP▲
Le principe sera d'avoir un autre serveur LDAP qui hébergera une copie du serveur LDAP principal. La synchronisation pourra se faire via syncrepl, fourni avec slapd.
syncrepl sera configuré dans le fichier /etc/ldap.conf.
Le serveur principal sera le serveur maitre, le second le serveur esclave. Il sera possible de faire une relation maitre-maitre avec une première relation maitre-esclave entre le premier et second serveur, configuré sur le premier serveur ; et une seconde relation maitre-esclave entre le second et le premier serveur, configuré sur le second serveur.
Ceci n'a pas été étudié dans le cadre de ce tutoriel.
Il reste également possible d'effectuer un import/export comme vu au chapitre précédent.
9-3. Kerberos▲
Kerberos est un protocole d'authentification basé sur un échange de clés secrètes et générant des tickets d'authentification. Il ne vous servira pas à vous connecter directement, mais permettra à des services comme LDAP de vous identifier. Une fois authentifié, un ticket a une durée de vie et peut être invalidé, une reconnexion sera alors nécessaire.
Kerberos est assez répandu. Il est utilisé par l'Active Directory de Microsoft et il peut être utilisé avec LDAP (notamment via l'implémentation Linux Heimdal).
Voici comment fonctionne l’authentification Kerberos :
|
|
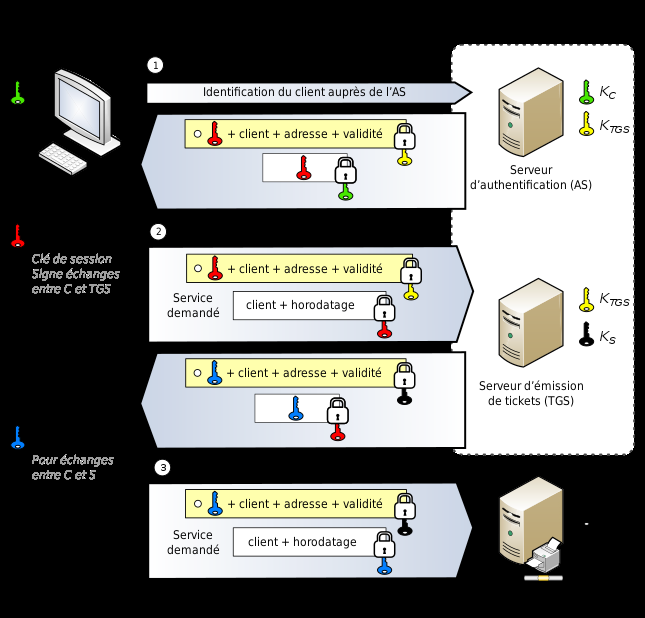
Kerberos se décompose en deux parties :
- Authentication Service (AS) : qui délivrera un ticket de demande d'accès en cas d'authentification réussie ;
- Ticket Granting Service (TGS) : qui fournira un ticket d'accès au service demandé.
Précisément, l'utilisateur s'authentifie auprès de l'AS via un ticket généré par son client Kerberos (couple login, mot de passe hashé (pas de mot de passe en clair), horodatage), si l'authentification est correcte, il reçoit un ticket TGT (clé de session TGS) : comparable à un contrôle d'identité par un vigile qui va vous délivrer un badge. Ce ticket n'est pas déchiffrable par l'utilisateur.
L'utilisateur va ensuite demander un ticket d'accès au TGS via la clé de session qu'il a reçue. Un peu comme une carte magnétique qui vous sera donnée en plus du badge par un second vigile après avoir passé le premier contrôle, et vous donnera accès à un étage ou non, carte magnétique délivrée en plus du badge et valable pour le porteur du badge pendant un temps précis et pour des choses précises.
Kerberos ne sert qu'à faire la preuve de votre identité. Les services utilisant Kerberos (exemple serveur de fichiers) sauront que vous avez été authentifié et que votre authentification est valide jusqu'à une heure précise, mais les droits d'accès restent à leur charge (dans le cas d'un serveur de fichiers un utilisateur A a accès au dossier X, mais pas au dossier Y).
Une extension à Kerberos nommée PKINIT permet de remplacer l'authentification via un couple login/mot de passe par une carte à puce.
9-4. Windows Server▲
En environnement Windows, Active Directory va centraliser la gestion des ressources (serveurs, ordinateurs, utilisateurs, partages). Active Directory s'appuie sur une implémentation LDAP propriétaire et utilise Kerberos. Active Directory permet aussi le déploiement d'applications (ou de systèmes complets), de politiques de sécurité (pouvant être vues comme des réglages comme l'impossibilité d'accéder à la configuration système, à la ligne de commande, lancement d'une seule application sans accès au système notamment avec le bureau à distance, fond d'écran paramétré à distance, etc.). Une infrastructure AD part d'une racine nommée forêt, qui va contenir un ou plusieurs domaines (comme une arborescence DNS). Un domaine va contenir au minimum un serveur qui fera contrôleur de domaine. Si un seul serveur est présent dans l’infrastructure, il fera office de contrôleur de foret et contrôleur de domaine. Les objets d'un domaine sont répliqués entre les différents contrôleurs membres du domaine.
9-5. Mac OS X▲
Mac OS Server intègre un système nommé OpenDirectory, fork d'OpenLDAP pour fournir son service centralisé d'authentification. OpenDirectory permet la connexion à un domaine Microsoft Active Directory.
Depuis Mac OS 10.8 Mountain Lion, Mac OS Server est une application à acheter sur l'Apple Store, qui devient une simple extension de Mac OS. Mac OS Server est depuis un moment en déclin notamment avec l'abandon des serveurs Apple Xserve. Mac OS High Sierra peut faire serveur Time Machine. La montée en puissance des NAS à prix abordable permettant l'utilisation de services proposés par Mac OS Server ne fait qu’accélérer son déclin.
9-6. Bilan▲
NIS n'est pas réputé pour être très sécurisé. Il est envisageable de l'utiliser à travers un réseau sécurisé en VLAN en interne ou via un tunnel VPN entre plusieurs sites. Il est spécifique au monde Unix et est plus que déprécié. Cette solution ne sera pas utilisée dans un environnement cloud.
LDAP n'est pas simple à implémenter, mais à l’avantage d'être un standard très répandu.
10. Réplication/clustering de bases de données▲
Nous verrons dans ce chapitre le cas des bases de données MySQL, mais le principe est applicable sur les autres moteurs de bases de données gérant cette possibilité.
10-1. Réplication▲
Le principe de réplication va consister à garder une ou plusieurs copies des bases de données en les synchronisant entre plusieurs machines.
Cette réplication peut être de type :
- maitre-esclave ;
- maitre-maitre.
10-1-1. Maitre-esclave▲
On écrit sur le maitre et on peut lire sur la ou les machines esclaves (ainsi que sur le maitre). La machine esclave peut-être considérée comme le client du maitre. Les esclaves sont en lecture seule.
10-1-2. Maitre-maitre▲
Les deux machines ont en même temps le statut de maitre et d'esclave la machine A étant l'esclave de la machine B et vice-versa. Par conséquent, une modification effectuée sur B sera répercutée sur A et inversement.
10-1-3. Détails▲
Les modifications effectuées sur un maitre sont synchronisées sur les autres membres du groupe de synchronisation. Les données peuvent être lues sur n'importe quelle machine, ce qui permet une répartition de charge et une tolérance de panne. Avec les dernières versions de MySQL, il est possible d’avoir plus de deux nœuds, mais il est conseillé d'utiliser un cluster.
Pour fonctionner en mode réplication, MySQL va écrire les modifications de la base dans des fichiers journaux (logs), qui seront transmis aux serveurs secondaires. Ceux-ci se mettront à jour depuis ces journaux en rejouant les modifications nécessaires depuis leur position actuelle dans ces logs vers la dernière position pour être à jour par rapport au serveur maitre. Une position peut être vue comme une ligne dans le journal.
10-1-4. Activation de la réplication entre un maitre et un esclave▲
Pour activer les journaux, il est nécessaire de modifier la configuration de MySQL (/etc/mysql/my.cnf). Il faut décommenter la ligne commençant par log-bin. Profitons-en pour décommenter la ligne server-id, chaque serveur devant avoir un id différent.
j'en profite pour modifier la ligne :
bind-addess = 127.0.0.1par :
bind-addess = 0.0.0.0Par défaut, MySQL n'autorise l'accès qu'à l'adresse de loopback (127.0.0.1).
MySQL autorise soit une seule adresse, soit toutes les adresses. Il n'est pas possible de n'autoriser que deux adresses par exemple. C’est au niveau du pare-feu qu’il faudra gérer des plages d’adresses autorisées.
Ces réglages seront pris en compte après redémarrage du démon.
Pour nos tests nous utiliserons srv1 (192.168.1.200) en serveur maitre, et srv2 (192.168.1.201) en serveur esclave.
Une fois la modification du fichier de configuration effectuée, nous commençons par donner les droits de réplication à un utilisateur que nous nommerons « sync ».
mysql -u root -p
Enter password :
Welcome to the MYSQL monitor. Commands end with ; or \g.
Your MySQL connection id is 94
Server version: 5.5.59-0+deb8u1-log (Debian)
Copyright ( c ) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registerd trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
Myslq > GRANT REPLICATION SLAVE ON *.* TO ‘sync’@'192.168.1.201’ IDENTIFIED BY 'motdepasse';
Query OK, 0 rows affected (0.00 sec)Nous forçons l'enregistrement des droits :
FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)Nous allons ensuite mettre un verrou sur les tables, le temps d'activer la réplication. À ce stade l'accès en écriture sera donc bloqué. Vous devrez donc avoir préparé srv2 avant pour minimiser le temps d’immobilisation.
FLUSH TABLES WITH READ LOCK;
Query OK, 0 rows affected (0.00 sec)Nous allons ensuite relever la position actuelle dans les journaux :
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 68145 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)Nous aurons besoin du nom du fichier journal (mysql-bin.000002 dans notre exemple) ainsi que de la position (68145 dans notre exemple).
Nous pouvons maintenant quitter le client MySQL avec exit.
Nous faisons ensuite un dump de nos bases :
mysqldump –all-databases -u root -p >export.sql
Enter password:
– Warning: Skipping the data of table mysql.event. Specify the –events option explicitly.Nous pouvons ensuite lever le verrou sur les tables :
mysql > UNLOCK TABLES ;
Query OK, 0 rows affected (0.00 sec)Nous transférons ensuite le dump sur srv2.
Avant de l'intégrer, nous modifions le fichier /etc/mysql/my.cnf pour changer le server-id (sans oublier de redémarrer le service).
Nous importons le dump :
mysql -u root -p <export,sql
Enter password:Nous procédons ensuite à l'activation de la réplication. Voici les opérations à effectuer :
mysql> STOP slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)puis :
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.200',
-> MASTER_USER='sync',
-> MASTER_PASSWORD='motdepasse',
-> MASTER_LOG_FILE='mysql-bin.000002',
-> MASTER_LOG_POS=68145;
Query OK, 0 rows affected (0.10 sec)Dans l'exemple ci-dessus, à la fin de la première ligne (après la virgule), un retour chariot a été fait, ceci afin de faciliter la lisibilité. Il aurait été possible d'écrire toute la requête sur la même ligne. Vous pouvez voir l'intégration de la position récupérée précédemment (nom du fichier et position).
Nous pouvons finalement démarrer l’esclave :
mysql> START slave;
Query OK, 0 rows affected (0.00 sec)La base devrait être maintenant répliquée. Il est possible de contrôler le résultat avec la commande suivante :
mysql> SHOW SLAVE STATUS \g
+----------------------------------+-------------+--------------+
| Slave_IO_State | Master_Host | Master_User | Master_Port | Connect_Retry | Master_Log_File | Read_Master_Log_Pos | Relay_Log_File | Relay_Log_Pos | Relay_Master_Log_File | Slave_IO_Running | Slave_SQL_Running | Replicate_Do_DB | Replicate_Ignore_DB | Replicate_Do_Table | Replicate_Ignore_Table | Replicate_Wild_Do_Table | Replicate_Wild_Ignore_Table | Last_Errno | Last_Error | Skip_Counter | Exec_Master_Log_Pos | Relay_Log_Space | Until_Condition | Until_Log_File | Until_Log_Pos | Master_SSL_Allowed | Master_SSL_CA_File | Master_SSL_CA_Path | Master_SSL_Cert | Master_SSL_Cipher | Master_SSL_Key | Seconds_Behind_Master | Master_SSL_Verify_Server_Cert | Last_IO_Errno | Last_IO_Error | Last_SQL_Errno | Last_SQL_Error | Replicate_Ignore_Server_Ids | Master_Server_Id |
+----------------------------------+-------------+--------------+
| Waiting for master to send event | 192.168.8.1 | sync | 3306 | 60 | mysql-bin.000003 | 19312 | mysqld-relay-bin.000003 | 19458 | mysql-bin.000003 | Yes | Yes | | | | | | | 0 | | 0 | 19312 | 36625 | None | | 0 | No | | | | | | 0 | No | 0 | | 0 | | | 1 |
+----------------------------------+-------------+--------------+
1 row in set (0.00 sec)\g à la place de ; en fin de requête permet l'affichage en format vertical, facilitant ainsi la lecture.
10-1-5. Activation de la réplication maitre-maitre▲
Une réplication maitre-maitre consiste à faire une réplication maitre-esclave du premier serveur vers le second, puis une autre du second vers le premier. Pour notre cas, nous reprenons l’état des serveurs comme à la fin de la section précédente : c’est-à-dire que la réplication maitre-esclave entre srv1 et srv2 est déjà en place. Nous allons donc en faire une entre srv2 et srv1.
Nous activons les logs sur srv2 comme vu précédemment.
Nous continuons par l'autorisation :
mysql> GRANT REPLICATION SLAVE ON *.* TO 'sync'@'192.168.8.200' IDENTIFIED BY 'motdepasse';
Query OK, 0 rows affected (0.00 sec)Puis nous récupérons la position :
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 265 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)Nous appliquons ensuite cette position sur srv1 :
mysql> STOP slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CHANGE MASTER TO
-> MASTER_HOST='192.168.1.200',
-> MASTER_USER='sync',
-> MASTER_PASSWORD='motdepasse',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=265;
Query OK, 0 rows affected (0.06 sec)
mysql> START slave;
Query OK, 0 rows affected (0.00 sec)Il est possible d'ajouter d'autres serveurs sur le principe d'une réplication maitre-esclave entre deux machines et de façon bidirectionnelle comme vu précédemment. Mais dans la réalité, la lourdeur et les risques de problème rendent cette idée aberrante. Dans le cas de plus de deux machines, l'utilisation d'un cluster me parait indispensable.
10-2. Le moteur Federated de Mysql Server▲
Le moteur Federated de MySQL Server permet de « voir » une table sur un serveur distant dans une base locale. Ceci n'a pas pour but d'apporter des fonctions de clustering, mais peut permettre par exemple la centralisation d'une table d'utilisateurs pour plusieurs serveurs.
Ce moteur comporte des contraintes :
- il faut démarrer MySql Server avec l'option –federated ;
- les transactions sont impossibles sur cette table ;
- pas de modification de la table en local, celle-ci doit impérativement être faite sur le serveur distant ;
- pas de cache de requêtes, les données proviennent de la base de données distante et ralentissent donc les lectures ;
- si le serveur distant est indisponible, la table FEDERATED l'est également.
Sa mise en place se fait comme suit :
Déclaration sur le serveur hébergeant la table :
CREATE TABLE test (
id int(20) NOT NULL auto_increment,
nom varchar(32) NOT NULL default '',
PRIMARY KEY (id),
KEY name (name),
)
ENGINE=InnoDB;Déclaration sur le serveur voulant utiliser la table distante :
CREATE TABLE test_distant (
id int(20) NOT NULL auto_increment,
nom varchar(32) NOT NULL default '',
PRIMARY KEY (id),
KEY name (name),
)
ENGINE=FEDERATED
COMMENT='mysql://utilisateur@serveur:9306/federated/test';10-3. Clustering▲
Un cluster de bases de données est un système distribué dans une grappe de serveurs. Celle-ci va permettre la répartition de charge et la tolérance de panne. Le principe est similaire aux systèmes de fichiers distribués.
Pour mettre en place notre cluster de bases de données, nous utiliserons Galera Cluster.
Galera Cluster est un cluster libre pour MySQL. Il se compose de deux parties :
- de Galera ;
- d’une version de MySQL, fournie intégrant l'API WSREP.
Galera cluster est fourni avec MariaDB.
10-3-1. Installation de Galera cluster avec MariaDB▲
Dans ce tutoriel, sur Debian Stretch, nous testerons Galera avec MariaDB, installé par défaut avec la commande apt-get install mysql-server.
10-3-1-1. Création du cluster▲
La première étape consiste en la création d’un cluster, c’est-à-dire d’un ensemble de machines.
Voici un fichier de configuration nous permettant la création d'un cluster nommé par le nom très original « mon-cluster ». Cette configuration sera stockée dans le fichier /etc/mysql/conf.d/galera.cnf :
[mysqld]
query_cache_size=0
binlog_format=ROW
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_doublewrite=1
bind-address=0.0.0.0
server-id = 1
# Configuration Galera
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_provider_options="gcache.size=4G"
wsrep_cluster_address=gcomm://
wsrep_cluster_name='mon-cluster'
wsrep_sst_method=rsync
wsrep_node_name='sql1'
# Tunning InnoDB à personnaliser selon ses besoins
#innodb_buffer_pool_size=4G
#innodb_file_per_table
#innodb_flush_log_at_trx_commit=2
innodb_log_file_size=100MPour plus de détails, je vous invite à consulter la documentation.
Les lignes importantes étant :
- binlog_format=ROW : activation des logs avec le format ROW, prérequis de Galera ;
- default_storage_engine=innodb : INNODB est le format de tables compatible avec Galera, c'est celui qui est utilisé par défaut avec MySQL à ce jour ;
-
Bind-address=0.0.0.0 : permet au serveur d'être contacté par d'autres machines, nécessaire pour le dialogue entre les différentes machines du cluster. Par défaut, seul localhost peut dialoguer avec MySQL ;
Rappel : Il n'est pas possible de choisir les machines autorisées à dialoguer avec MySQL. C'est soit localhost, soit toutes les machines du réseau.
-
wsrep_provider=/usr/lib/galera/libgalera_smm.so : c'est la ligne qui va charger les bibliothèques Galera ;
-
wsrep_cluster_address=gcomm:// : sur cette ligne apparaîtra la liste des machines du cluster (noms ou adresses IP) ;
-
wsrep_cluster_name='mon-cluster' : le nom du cluster ;
- wsrep_sst_method=rsync : c'est la méthode de transfert des changements entre les différents nœuds. rsync est l'option par défaut, les autres possibilités sont : mysqldump, xtrabackup (que nous verrons plus tard pour les sauvegardes) et xtrabackup-v2.
Une fois la configuration préparée, nous lançons la commande suivante :
/usr/bin/galera_new_clusterNous redémarrons mariaDB ;
service mysql restartNous testons l'état du cluster avec la commande suivante :
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 0 |
+--------------------+-------+
1 row in set (0.00 sec)Notre cluster ne contient aucune machine.
Ceci est dû au fait que l'option wsrep_on est désactivée par défaut. Nous pouvons le voir avec la commande SQL suivante :
SHOW VARIABLES LIKE 'wsrep_on';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_on | OFF |
+---------------+-------+
1 row in set (0.00 sec)Nous changeons la valeur de cette variable :
set GLOBAL wsrep_on=on;
Query OK, 0 rows affected (0.00 sec)Nous pouvons vérifier le nouvel état de la variable wsrep_on :
SHOW VARIABLES LIKE 'wsrep_on';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_on | ON |
+---------------+-------+
1 row in set (0.00 sec)Nous réinterrogeons wsrep_cluster_size, mais celle-ci est toujours à 0.
Nous plaçons la variable wsrep_on dans le fichier galera.cnf :
wsrep_on=onUne fois le service redémarré, cela fonctionne :
MariaDB [(none)]> show variables like 'wsrep_on';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_on | ON |
+---------------+-------+
1 row in set (0.00 sec)
MariaDB [(none)]> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
1 row in set (0.00 sec)À ce stable, nous avons un cluster SQL d'une machine.
Nous pouvons contrôler et voir l'état du cluster depuis des commandes SQL SHOW STATUS :
mysql> SHOW STATUS LIKE 'wsrep_local_state_comment';
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| wsrep_local_state_comment | Synced |
+---------------------------+--------+
1 row in set (0,01 sec)Nous créons ensuite une base de test avec quelques enregistrements.
10-3-1-2. Ajout d'une seconde machine au cluster▲
Comme pour la première machine, nous installons le paquet mysql-server. Cette seconde machine sera appelée, sans surprise, srv2. Nous recopions ensuite les fichiers /etc/mysql/conf.d/galera.cnf présents sur le premier serveur sur le nouveau serveur.
Nous ajoutons le nom de la première machine srv1 (nom déterminé par le fichier host de la première machine) sur la ligne wsrep_cluster_address=gcomm:// sur ce nouveau serveur.
Ce qui donnera :
wsrep_cluster_address=gcomm://srv1Nous modifions également le server-id :
server-id = 2Nous redémarrons ensuite le serveur MySQL de srv2 :
/etc/init.d/mysql restartLe démarrage prend un peu de temps, les bases devant se synchroniser.
Une fois la synchronisation effectuée, nous pouvons constater le fonctionnement en affichant les précédentes variables :
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_local_state_comment';
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| wsrep_local_state_comment | Synced |
+---------------------------+--------+
1 row in set (0.01 sec)
MariaDB [(none)]> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 2 |
+--------------------+-------+
1 row in set (0.01 sec)Un SHOW DATABASE depuis le second serveur nous montrera la présence de la base de test.
En allant consulter le dossier où MariaDB stocke les bases (/var/lib/mysql par défaut), nous pouvons constater la présence d'un dossier test contenant db.opt, essai.frm, essai.ibd (ma base de test contient une table nommée essai).
Si nous ajoutons une entrée dans la base, nous pourrons immédiatement constater sa présence sur l'autre machine.
10-3-2. Clustering Galera Cluster avec MySQL▲
Nous commencerons par l'installation des clés de dépôts :
apt-key adv --keyserver keyserver.ubuntu.com --recv BC19DDBAVous pourrez constater que le serveur de clés utilisé est celui d'Ubuntu. Cela ne posera pas de problèmes pour une installation sous Debian. C’est d’ailleurs la procédure d’installation officielle.
Ensuite, nous pouvons ajouter les dépôts de Galera dans le fichier /etc/apt/sources.list :
deb http://releases.galeracluster.com/mysql-wsrep-VERSION/DIST RELEASE main
deb http://releases.galeracluster.com/galera-3/DIST RELEASE mainN'hésitez pas à consulter la documentation officielle, les versions peuvent évoluer, et les noms de dépôts évoluer en conséquence.
Pour notre exemple nous utiliserons :
deb http://releases.galeracluster.com/mysql-wsrep-5.7/debian stretch main
deb http://releases.galeracluster.com/galera-3/debian stretch mainAprès un apt-get update, nous installons les paquets nécessaires :
apt-get install mysql-wsrep-5.7 galera-3 galera-arbitrator-3Contrairement à MariaDB, il vous sera demandé un mot de passe root pour MySQL. Sous MariaDB, l'utilisateur root peut se connecter par défaut au client MariaDB sans authentification.
Si vous aviez une autre version de MySQL d'installée, celle-ci sera remplacée. J'ai testé le remplacement d’une version MySQL classique ayant des données et ceci n'a créé aucune perturbation. Je recommande évidemment d'effectuer une sauvegarde avant toute manipulation.
Il va ensuite falloir créer le cluster. Pour ceci, j'utilise le même fichier de configuration que pour MariaDB.
J'arrête le serveur :
service mysql stopJe le redémarre ensuite avec l'option permettant la création du cluster :
mysqld_bootstrapCeci va démarrer le démon MySQL avec l'option -–wsrep-new-cluster.
Tout comme avec MariaDB, nous pourrons interroger les variables wsrep_cluster_size et wsrep_local_state_comment pour vérifier l’état de notre cluster et le nombre de machines l’intégrant.
Contrairement à MariaDB, il n'y a pas de variable ws_on à activer.
10-3-3. Maintenance : perte de srv2▲
Le processus de remise en service sera le même avec MariaDB qu’avec MySQL.
Avec la configuration actuelle, l’arrêt ou la perte de sql2 empêche l’utilisation de sql1.
Une requête SELECT nous retournera l'erreur :
MariaDB [test]> select * from essai;
ERROR 1047 (08S01): WSREP has not yet prepared node for application use
MariaDB [test]>Pour réactiver le cluster avec le seul nœud srv1, il va falloir modifier le fichier /var/lib/mysql/grastate.dat et remplacer :
safe_to_bootstrap : 0par :
safe_to_bootstrap : 1Il faut modifier le fichier lorsque le serveur SQL est arrêté. Une fois le serveur relancé, les bases seront à nouveau disponibles.
10-3-3-1. Remontage de srv2▲
Pour remonter srv2, il faut considérer la machine comme nouvelle et y recopier le fichier /etc/mysql/conf.d/galera.cnf.
Il faudra mettre à jour la ligne wsrep_cluster_address=gcomm:/ dans le fichier /etc/mysql/conf.d/galera.cnf et y ajouter srv1. Il faudra également mettre à jour le server-id.
Une fois les fichiers de configuration prêts, un démarrage du service déclenchera la synchronisation.
La synchronisation effectuée repositionnera la valeur safe_to_bootstrap du fichier /var/lib/mysql/grastate.dat à 0.
10-3-4. Maintenance : perte de srv1▲
La procédure de reprise sera exactement la même que pour srv2, la seule différence se trouvant dans la ligne wsrep_cluster_address qui doit être vide sur le poste « maitre » (l'initiateur du cluster), et le définir correctement pour le ou les autres serveurs.
10-3-4-1. Remise de srv1 en maitre▲
Nous arrêtons srv1 (l’esclave), puis srv2 (le maitre), le sens « maitre-esclave » ayant été inversé avec la réinstallation de srv1. Ceci n'est pas forcément utile.
Il suffira de modifier la ligne wsrep_cluster_address=gcomm:/ dans les fichiers /etc/mysql/conf.d/galera.cnf des deux machines pour remettre l'ordre voulu. Sur le maitre, la ligne wsrep_cluster_address=gcomm : doit être vide. L’esclave doit y spécifier l’adresse du maitre. Ensuite, il faut définir la variable safe_to_bootstrap à 1 sur le serveur maitre. Finalement, il faut redémarrer les serveurs dans l’ordre (maitre puis esclave).
10-3-5. Ajout d'un nouveau serveur▲
Pour ajouter des serveurs supplémentaires, la méthode sera la même. Il faudra insérer toutes les machines dans la ligne wsrep_cluster_address:// de chaque serveur.
10-3-6. Galera arbitrator▲
Le Galera arbitrator est un outil à part, fourni avec Galera Cluster. Celui-ci permet comme son nom l’indique d’arbitrer le cluster. Le démon Galera Arbitrator se nomme garbd. Il n’est pas configuré par défaut. Sa configuration est simple, il faut éditer le fichier /,etc/default/garb.
Il faudra décommenter les lignes :
GALERA_NODESet :
GALERA_GROUPGALERA_GROUP devra contenir le même nom du cluster mentionné dans la ligne wsrep_cluster_name du fichier de configuration de Galera.
|
|
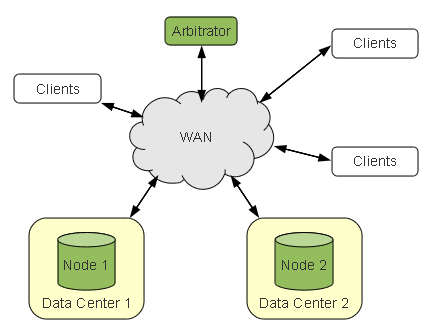
Il va gérer la notion de quorum (rôle d'arbitrage). En cas de coupure de liaison entre deux centres de données, ceux-ci vont pouvoir continuer à fonctionner chacun de leur côté et donc de manière indépendante. En conséquence, les données vont commencer à différer. Cette situation se nomme Split Brain : chaque serveur pense que l'autre ne fonctionne plus. Soit, les serveurs vont s'arrêter ou passer en lecture seule, soit ils vont fonctionner de façon autonome et cela posera un problème. Quel sera le nœud dont les données sont légitimes ? C’est là qu’intervient le quorum : en étant une machine indépendante, il y aura toujours une autorité contrôlant la légitimité des données. Si le quorum de machines minimal n'est pas présent, ou qu'une machine ne peut pas contacter la machine gérant le quorum,le système va se bloquer ou passer en lecture seule.
Avec trois serveurs, vous n’aurez pas besoin de l’arbitrator. Il est réellement nécessaire dans deux cas :
- vous avez un nombre pair de nœuds ;
- vous effectuez des sauvegardes via la méthode State Snapshot Transfer (SST).
10-3-7. Perte d’un nœud dans une configuration à plus de deux machines▲
La perte d’un des serveurs est transparente pour l’utilisation de la base, celle-ci sera simplement indisponible depuis le serveur tombé. Si le serveur revient en ligne, il se resynchronisera. Dans le cas où la synchronisation est impossible (position trop ancienne par rapport aux logs par exemple), celui-ci ne démarrera pas. Il faudra alors refaire la configuration.
10-3-8. Percona XtraDB cluster▲
Ayant évoqué Percona XtraBackup, je ne pouvais pas ne pas évoquer Percona XtraDB Cluster.
Son utilisation est identique à Galera cluster, Percona XtraDB Cluster utilisant la Galera Library et fournissant Percona XtraBackup.
Percona XtraDB Cluster peut utiliser le moteur InnoDB ou utiliser son propre moteur XtraDB, une version améliorée d'InnoDB.
Je vous laisse vous référer à sa documentation pour l’installation, celle-ci étant quasi identique.
10-4. Sauvegardes/restaurations▲
10-4-1. Sauvegarde par mysqldump▲
Pour effectuer une sauvegarde simple et efficace, il suffit de taper la commande :
mysqldump –all-databases -u root -p mot_de_passe >fichier.sqlL’option -all-databases permet de sauvegarder toutes les bases, il est possible de n’exporter qu’une seule base via :
mysqldump -u root -p mot_de_passe nom_de_la base>fichier.sqlLe fichier .sql créé est un simple fichier texte qui contiendra toutes les commandes pour recréer la base et la réalimenter avec son contenu.
10-4-2. Restauration d'une sauvegarde mysqldump▲
La restauration se fera avec la commande :
mysql -u root -p mot_de_passe <fichier.sqlou en cas de base unique :
mysql -u root -p mot_de_passe nom_de_la_base <fichier.sqlPar défaut, si la base existe déjà lors d'un import mysqldump, MySQL écrasera l'ancienne base.
mysqldump, effectuant un dump sur la sortie standard (stdout), il est possible de le compresser à la volée via une commande du type :
mysqldump –all-databases -u root -p mot_depasse |gzip >fichier.sql.gzet de la restaurer via :
zcat fichier.sql.gz| mysql -u root -p mot_de_passemysqldump permet de ne sauvegarder qu’une table précise, mais cela ne sera pas abordé dans ce tutoriel, l’idée étant d’avoir une sauvegarde complète.
L’avantage de la méthode mysqldump est sa simplicité et sa fiabilité. L’inconvénient est que le temps du dump, la base est bloquée.
Pour éviter cette situation, il faut utiliser des outils spécialisés permettant une sauvegarde sans interruption. Percona XtraBackup est l’un d’entre eux.
10-4-3. Sauvegarde avec Percona XtraBackup▲
Percona XtraBackup s’installe depuis un fichier .deb disponible sur le site :https://www.percona.com/downloads/Percona-XtraBackup-LATEST/
10-4-3-1. Réalisation d'une sauvegarde complète▲
Celle-ci s’effectua avec la commande :
xtrabackup --backup –target-dir=backup-full –user=utilisateur --password=mot_de_passebackup-full étant le dossier où nous effectuerons la sauvegarde.
Il est possible de stocker les identifiants dans un fichier /etc/mysql/conf.d/xtrabackup.cnf ayant pour contenu :
[xtrabackup]
user=<utilisateur>
password=<mot de passe>La commande doit se terminer avec une ligne :
completed OK!Il est à noter que la sauvegarde va inclure le fichier my.cnf.
10-4-3-2. Restauration d'une sauvegarde complète▲
Pour restaurer une sauvegarde effectuée avec XtraBackup, il est nécessaire de l’installer sur le poste de destination. De plus, il faut préparer la sauvegarde avec la commande :
xtrabackup --prepare --target-dir=backup-fulldevant toujours se terminer par :
completed OK!Ceci va utiliser les journaux pour mettre à jour la ou les bases par rapport aux commits et rollbacks. Ensuite, pour intégrer les données sauvegardées, il faut que le serveur soit arrêté :
service mysql stopNous supprimons ensuite le contenu de /var/lib/mysql.
Nous partons ici du postulat d'une restauration de toutes les bases. En cas de restauration d'une seule base parmi d'autres, il ne faudra effacer que la base concernée.
Nous appliquons ensuite la commande de restauration proprement dite :
xtrabackup --copy-back --target-dir=backup-fullEnsuite, il ne reste plus qu’à mettre les bons droits sur les fichiers :
chown -R mysql:mysql varlib/mysql/*À moins d'avoir utilisé le même compte que mysql pour effectuer la sauvegarde/restauration.
Il nous restera alors à redémarrer le service :
service mysql start10-4-3-3. Sauvegarde incrémentale▲
Une sauvegarde incrémentale va s’appuyer sur une première sauvegarde totale en lui appliquant des deltas, il faut donc commencer par effectuer une sauvegarde complète :
xtrabackup --backup --target-dir=backup-fullEffectuer une sauvegarde incrémentale n’est guère plus compliqué :
xtrabackup --backup –target-dir=backup-increment1 --incremental-basedir=backup-fullLa sauvegarde complète de base se trouvant dans le dossier backup-full, le delta correspondant à la sauvegarde incrémentale se trouvant dans le dossier backup-increment1. La sauvegarde incrémentale est bien sûr inexploitable sans la sauvegarde de base.
10-4-3-4. Restauration incrémentale▲
Nous commençons par préparer la sauvegarde de base :
xtrabackup --prepare --apply-log-only --target-dir=backup-fullNous appliquons ensuite le delta de la sauvegarde incrémentale :
xtrabackup --prepare --apply-log-only –target-dir=backup-full --incremental-dir=backup-increment1Il nous faudra ensuite effectuer les mêmes opérations que pour une restauration complète, vues précédemmentRestauration d'une sauvegarde complète :
- arrêt du service MySQL après préparation de la sauvegarde ;
- suppression ou sauvegarde du contenu de /var/lib/mysql ;
- application de la commande de restauration (xtrabackup --copy-back –target-dir=backup-full) ;
- application des droits.
Lisez attentivement ce qui concerne l'option -–apply-log-only dans le chapitre suivant.
10-4-3-5. Chaînage de plusieurs sauvegardes▲
Il est possible de chaîner les sauvegardes. Ceci permet de réduire la taille globale de la sauvegarde, d'avoir un versionning, mais nécessite de restaurer tous les points de sauvegarde, un par un, dans le bon ordre.
Le processus de sauvegarde, étalé dans le temps doit ressembler à :
xtrabackup --backup –target-dir=backup-full
xtrabackup --backup –target-dir=backup-increment1 –incremental-basedir=backup-full
xtrabackup --backup –target-dir=backup-increment2 –incremental-basedir=backup-increment1Vous pouvez voir que la seconde sauvegarde incrémentale utilise la première comme base.
La restauration se fera de la façon suivante :
xtrabackup --prepare --apply-log-only –target-dir=backup-full
xtrabackup --prepare --apply-log-only –target-dir=backup-full –incremental-dir=backup-increment1
xtrabackup --prepare -–target-dir=backup-full –incremental-dir=backup-increment2--apply-log-only doit être absent du dernier point de restauration.
Il m’a été possible de restaurer le point increment1 en omettant --apply-log-only. Il est donc possible de s’arrêter à une version précise tant que toutes les versions intermédiaires précédentes sont restaurées.
Je vous recommande d'utiliser des dates dans les noms des dossiers de sauvegardes incrémentales, ce qui vous permettra de facilement effectuer une restauration en appliquant les deltas dans le bon ordre.
Je vous invite à consulter les liens suivants :
https://www.percona.com/doc/percona-xtrabackup/LATEST/backup_scenarios/incremental_backup.html
https://www.percona.com/doc/percona-xtrabackup/LATEST/backup_scenarios/full_backup.html#full-backup
10-5. Autres bases que MySQL▲
PosGresSQL intègre la gestion de réplication. Le fonctionnement est similaire aux clusters MySQL en se basant sur les journaux de transactions.
Documentation sur la haute disponibilité, la répartition de charges, et la réplication pour PostGresSQL.
Microsoft SQL Server permet également la mise en place d'un cluster. Ceci se fera avec le rôle AD « cluster de basculement » (Failover Clustering).
11. Haute disponibilité▲
Un service est dit hautement disponible si sa moyenne de fonctionnement est supérieure à 99 % du temps.
Il est courant d'avoir des services proposés avec une disponibilité de 99,9% ou plus.
Un taux de disponibilité de 99 %, soit proche de 100 % représente une moyenne d'indisponibilité de trois jours par an, sept heures par mois, quinze minutes par jour.
Il s'agit d'une moyenne pouvant ne pas signifier grand-chose. Une panne pendant trois jours consécutifs sur un service aura un impact significatif au moment de celle-ci, mais pas sur le taux de disponibilité annuel, contrairement à une panne de trois jours étalés sur plusieurs heures ou plusieurs minutes sur l'année.
Sur un service mondial, une panne peut se présenter sur une zone géographique (régulièrement vu avec les services des GAFA) et ne pas impacter les autres régions, et donc avoir globalement une faible répercussion et ne pas impacter le taux de disponibilité, mais localement présenter un problème significatif.
Par ailleurs, si un dysfonctionnement des services mails de quelques minutes ou dizaines de minutes se verra à peine, voire pas du tout si les serveurs mails ne retournent pas d'erreur de connexion aux clients de messagerie, ce ne sera pas le cas pour un service utilisé massivement comme CloudFront ou Amazon S3 qui aura un impact immédiat sur un nombre considérable de services dont la cause de leur panne sera liée à un fournisseur externe.
Pour avoir un service à haute disponibilité, il ne faut aucun point de défaillance unique.
Exemples de point de défaillance unique :
- disque dur sans utilisation de RAID dans une machine ;
- une machine non répliquée et sans système de surveillance et de bascule ;
- une seule connexion vers Internet ;
- pas de serveur DNS secondaire ou sur le même réseau ;
- pas de redondance électrique en cas de coupure de courant (groupe électrogène) ;
- pas de redondance d'un système de refroidissement dans une salle serveur ;
- dépendance à l'utilisation de service externe (S3, CloudFront, etc.).
11-1. Répartition de charge▲
La répartition de charge (appelé aussi load balancing) permet :
- d’étaler la charge de travail sur plusieurs systèmes ;
- rendre transparent une panne matérielle ou au moins faire en sorte qu'il n'y ait pas de coupure de service, même si le service peut être dégradé.
Un load-balancer a pour rôle de répartir la charge de travail entre les différents nœuds participants. Il pourra utiliser un algorithme simple dit statique comme utiliser les machines à tour de rôle ou utiliser un algorithme dit dynamique qui va s'adapter à la situation.
11-2. Redondance▲
Pour qu'un système à charge répartie puisse rester en ligne, il ne doit y avoir aucun point de défaillance. Cela signifie que tous les éléments indispensables au système doivent être redondants, comme un nombre suffisant de machines sur un système de fichiers répartis, une redondance sur le système de load balancing, une redondance électrique ou de datacenter.
11-3. Les politiques de load balancing les plus connues▲
11-3-1. Le DNS Round-Robin▲
Le Round-Robin est un algorithme d'ordonnancement qui fait tourner des processus au sein d'une file d'attente dans un système à temps partagé.
Appliqué aux DNS, plusieurs machines (du moins leur adresse IP) vont être affectées à un FQDN.
À chaque requête DNS, une IP différente est retournée par la rotation des adresses enregistrées. Le client gardera ensuite cette IP dans son cache DNS.
Le fait que les DNS présentent des machines différentes de façon tournante lorsqu'une requête leur est faite va générer automatiquement une répartition de charge.
En cas de panne d'une machine, il sera nécessaire à un client déjà connecté de refaire une requête DNS pour obtenir une des autres adresses disponibles.
En cas de suppression d'une machine, ou de l'ajout d'une machine supplémentaire, la modification ne sera prise en compte qu'une fois le TTL de l'enregistrement DNS expiré.
Le point de défaillance est le serveur DNS lui-même, censé être pallié par un DNS secondaire.
11-3-2. Heartbeat▲
Heartbeat que l'on peut traduire par prise de pouls va surveiller la disponibilité de plusieurs serveurs. Ceux-ci vont communiquer depuis une interface réseau en UDP ou via un lien série. Le système sera accessible par une adresse IP que nous appellerons virtuelle. Elle sera le point d'entrée du service.
Chacun aura sa propre IP et une seule machine, la machine maitre aura l'IP sur laquelle se trouve le service (exemple un serveur web). Si le serveur maitre tombe, un des autres serveurs le détectera, deviendra le maitre et prendra l'IP virtuelle.
Il est possible de faire de la répartition de charge. Le gestionnaire servira à répartir cette charge. En cas de panne d'une des machines accueillant celle-ci, la charge sera distribuée aux autres. Le gestionnaire devra être redondé sous peine de service coupé en cas de panne de celui-ci.
Les algorithmes de répartition de charges suivants sont disponibles :
- Least-Connection (lc) : envoi de la demande vers la machine la moins chargée ;
- Weighted Least-Connection (wlc) : envoi de la demande vers la machine avec le moins de connexions ;
- Round-Robin (rr) : envoi de la demande à tour de rôle (vu au chapitre précédent) ;
- Weighted Round-Robin (wrr) : round robin pondéré ;
- Locality-Based Least-Connection (lblc) : envoi des demandes d'un client toujours vers la même destination en favorisant les machines qui ont le moins de connexions ;.
- Destination-Hashing (dh) : envoi des demandes d'un client vers une des destinations selon une table de hashage sur la destination ;
- Source-Hashing (sh) : envoi des demandes d'un client vers une des destinations selon une table de hashage sur la source ;
- Shorted Expected Delay (sed) : envoi sur le serveur qui doit statistiquement répondre le plus vite ;
- Never Queue (nq) : envoi de la demande sur un serveur inutilisé ou sinon vers le Shorted Expected Delay.
11-3-2-1. Exemple avec un serveur web▲
Nous préparons deux machines hébergeant un serveur web Apache et distribuant la même page HTML de test. Ces machines ont comme adresses IP 192.168.1.201 et 192.168.1.202. L'adresse 192.168.1.200 sera réservée au point d'entrée HeartBeat.
Pour facilement repérer le serveur actif, la page de test du 1er serveur affichera Essai 1, la page de test du second, Essai 2. Nous fixerons en conséquence les fichiers /,etc/hosts ainsi que le hostname.
Sur ces deux machines, nous aurons une carte réseau supplémentaire sur un autre réseau, cartes réservées au dialogue HeartBeat. Nous utiliserons pour ceci les adresses 10.1.1.1 et 10.1.1.2.
Commençons par installer Heartbeat sur la première machine :
apt-get install heartbeatIl va ensuite falloir créer trois fichiers de configuration :
- /etc/heartbeat/ha.cf : c'est le fichier de configuration principal, il va contenir les paramètres du cluster ;
- /etc/heartbeat/haressources : ce fichier va décrire les opérations à effectuer ;
- /etc/heartbeat/authkeys : ce fichier va contenir les réglages de sécurité.
Commençons par le fichier /etc/heartbeat/ha.cf :
logfile /var/log/ha-log
keepalive 2
deadtime 10
bcast eth1
node srv1 srv2
auto_failback no
respawn root /usr/lib/heartbeat/ipfail
apiauth ipfail gid=root uid=rootExplications :
- logfile : nom et emplacement du fichier de logs ;
- keepalive : intervalle de prise de pouls (en secondes, ajouter ms pour mettre en microsecondes) ;
- deadtime : temps nécessaire pour déclarer un nœud HS ;
- bcast : interface réseau utilisée pour faire la prise de pouls (dans notre cas, la seconde carte avec l'adresse en 10.1.1.x) ;
- node : les noms DNS des machines ;
- auto_failback : si positionné sur no, ne repasse pas la machine maitre en mode actif après remise en ligne ;
- respawn : permet de lancer un programme au démarrage de HeartBeat (1er paramètre : le nom d'utilisateur. Nous lançons ici ipfail, permettant de ne pas attendre de pulsations avant de prendre la main en cas de lien HS) ;
- apiauth : indique les utilisateurs autorisés à dialoguer avec les logiciels lancés par respawn, dans notre cas uniquement root.
Nous continuons ensuite avec le fichier /,etc/heartbeat/haressources :
srv1 Ipaddr::192.168.1.200 apache2Chaque action à appliquer doit être séparée par un espace, nous indiquons ici pour srv1 l'adresse IP à utiliser soit 192.168.1.200, puis le service à démarrer : apache2.
Si nous avions d'autres services à activer, il aurait fallu les indiquer les uns derrière les autres.
En action, il est également possible de monter un système de fichiers. Voici un exemple avec le montage d’un NFS :
srv1 Filesystem::192.x.x.x:/partage_distant::/point_de_montage::nfsLa documentation décrit les actions possibles.
Pour plus d'informations : http://linux-ha.org
Et enfin le dernier fichier : /etc/heartbeat/authkeys :
auth 1
1 sha1 "le precieux"Nous déclarons ici utiliser le protocole sha1 avec le mot de passe ajouté en paramètre. La ligne auth 1 étant un index pour le cas où plusieurs clés sont utilisées (non abordé dans ce tutoriel).
Les protocoles utilisables sont :
- crc : ne nécessite pas de clé, non sécurisé, utilisable dans le cas d'une liaison par port série ;
- md5 :faiblement sécurisé ;
- sha1 : plus sécurisé que md5, mais demande plus de ressources CPU.
Nous changeons les droits du fichier :
chmod 600 /,etc/heartbeat/haresourcesNous désactivons ensuite le démarrage automatique d'Apache :
systmctl disable apache2Nous arrêtons également le service :
systemctl stop apache2Nous lançons maintenant HeartBeat :
systemctl start heartbeatAprès son démarrage, le serveur web répond sur l'adresse 192.168.1.200 ainsi que sur son adresse d'origine 192.168.1.201.
ifconfig nous fait apparaître une interface supplémentaire : eth0:0
...
eth0:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.200 netmask 255.255.255.0 broadcast 192.168.1.255
ether 08:00:27:ba:77:c4 txqueuelen 1000 (Ethernet)
...Le système fonctionnant, nous l'activons au démarrage :
systemctl enable heartbeatNous recopions les fichiers de configuration sur la machine srv2 (192.168.1.202) précédemment préparée (serveur web configuré, heartbeat installé).
Nous modifions le fichier /,etc/heartbeat/haresource pour remplacer l'entrée srv1 par srv2.
Après démarrage du service sur srv2, pour tester, nous arrêtons srv1. Le serveur web répond toujours et nous pouvons constater le changement de machine par l'affichage de Essai 2 au lieu d'Essai 1.
En interrogeant HeartBeat sur son état avec :
cl_status hbstatus -vNous voyons que srv1 est inactif.
version: 3.0.6 (node: 958e11be8686759f1b99204c17812f2c2633b169)
managed by: "haresources"
srv2 active (nodetype: normal)
eth1 up
srv1 dead (nodetype: normal)
eth1 upUne fois srv1 redémarré, l'IP virtuelle reste sur srv2 (option auto_failback sur no). Le redémarrage du service HeartBeat sur srv2 rétablira la situation initiale.
Ceci fonctionnera pour un site statique et si la perte d'une session n'est pas problématique. Pour un site dynamique, il y aura pour commencer le problème de session démarrée sur le serveur HS, celle-ci sera perdue. Le module apache mod_session_dbd permet de stocker les sessions dans une base MySQL. Dans l'optique d'un système haute disponibilité, à tolérance de panne, un cluster MySQL comme vu précédemmentRéplication/clustering de bases de données répondra à la problématique. Il devrait également être possible de stocker les fichiers de session dans un système de fichiers distribué.
11-3-3. Pacemaker▲
Pacemaker permet de démarrer, arrêter, superviser des ressources (système de fichiers, adresse IP, service). Jusqu'en 2017, il faisait partie de HeartBeat.
11-3-4. Corosync▲
Corosync permet la gestion de la communication entre plusieurs nœuds, il devra être couplé avec un gestionnaire de ressources comme pacemaker.
Pus d'informations sur Cororosync.
11-3-5. Corosync/Pacemaker▲
Corosync est souvent couplé avec Pacemaker pour gérer un cluster de ressources.
11-3-6. Keepalived▲
keepalived est un autre système permettant l'équilibrage de charge et la haute disponibilité.
11-3-6-1. keepalived - tests▲
Comme pour les tests HeartBeat, nous préparerons deux serveurs Apache srv1 et srv2 avec pour adresse IP 192.168.1.201 et 202 respectivement. Nous réserverons l'adresse 192.168.1.200 pour l’adresse virtuelle du système. Il sera possible de directement appeler 192.168.1.201 ou 202, mais dans ce cas nous ne passerons pas le système de haute disponibilité/l'équilibrage de charge.
J'ai préparé deux serveurs apache 192.168.1.201 (srv1) et 192.168.1.202 (srv2) affichant « It Works <nom serveur> » selon le serveur répondant à la requête :
|
|
À ce stade, l'adresse web http://192.168.1.201 affiche « It works srv1 » et 192.168.1.202 affiche « it works srv2 ».
Ceci va nous permettre de voir facilement quel serveur répond depuis l'adresse IP virtuelle présentant le service réparti.
Nous effectuons les prérequis réseau en modifiant le fichier /etc/sysctl.conf :
- décommentage de la ligne net.ipv4.ip_forward=1 ;
- ajout de la ligne net.ipv4.ip_nonlocal_bind=1.
Pour prendre en compte les réglages :
~# sysctl -p
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
~#Nous installons ensuite keepalived :
apt-get install keepalivedNous créons ensuite un fichier de configuration sur srv1 (192.168.1.201) :
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 101
priority 100
virtual_ipaddress {
192.168.1.200
}
}Nous créons dans le fichier de configuration une instance VRRP (Virtual Router Redonduncy Protocol) avec les éléments suivants :
- state : valeurs MASTER|BACKUP : le MASTER est le serveur maitre, le BACKUP est le serveur de secours ;
- interface : le nom de l’interface réseau à l’écoute ;
- virtual_router_id : doit être identique sur chaque nœud ;
- priority : la priorité du serveur (la valeur la plus faible définissant le serveur prioritaire) ;
- virtual_ipadress : l'adresse IP virtuelle du cluster.
- nopreemt : (non présent dans la configuration en exemple) permet à un MASTER qui renaît de ne pas reprendre automatiquement l’IP qui avait basculé sur le serveur BACKUP.
Après redémarrage du service par systemctl restart keepalived, la machine répondra sur l’IP 192.168.1.200 et 201.
Nous installons ensuite le paquet sur le second serveur, modifions sysctl.conf, et copions le fichier de configuration.
Nous modifions la valeur priority de 100 à 101 sur srv2, de façon à ce que srv1 soit prioritaire dans son rôle de MASTER.
Pour des configurations plus importantes, il est possible de créer des groupes d’instances sous la forme :
vrrp_sync_group VG1 {
group {
VI_1
VI_2
}
}VI_1 et VI_2 étant des vrrp_instance.
11-3-6-2. Test▲
Nous coupons la liaison réseau de srv1. L’adresse 192.168.1.200 répond toujours. Nous pouvons voir la bascule de serveur par l’affichage de « It works srv2 » démontrant que svr2 a bien pris le relais.
Comme nous n’avons pas utilisé l’option noprempt, srv2 reste la machine active après remise en service de srv1. Il suffit de stopper le service keepalived sur srv2 le temps que srv1 reprenne la main pour repartir sur la configuration initiale.
À ce stade, keepalived garantira la disponibilité de l’ip 192.168.1.200, mais ne fera pas de répartition de charge. Pour cela, il faudrait ajouter un bloc « virtual_server » dans la configuration, ce que nous verrons un peu plus loin.
11-3-6-3. Détection de bascule ▲
keepalived peut vous avertir par mail en cas de bascule de l’IP virtuelle. Pour cela nous ajouterons un bloc « global_defs » avant notre bloc « vrrp » :
global_defs {
notification_email {
<adresse mail>
}
notification_email_from <adresse émettrice>
smtp_server <adresse ip/fqdn serveur mail>
smpt_connect_timeout 30
router_id 100
}11-3-6-4. Répartition de charge▲
Nous modifions la définition de l’instance VRRP comme ceci :
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 101
priority 100
virtual_ipaddress {
192.168.1.200
}
virtual_server 192.168.1.200 80 {
lb_algo wlc
lb_kind DR
#sorry_server 192.168.1.199
}
real_server 192.168.1.201 80 {
weight 1
inhibit_on_failure
}
real_server 192.168.1.202 80 {
weight 2
inhibit_on_failure
}
}Dans la définition de l'interface virtuelle, nous pouvons voir le choix du protocole wlc pour la répartition de charge. Les protocoles disponibles sont :
- wlc : Weighted Least-Connection ;
- lblc : Locality-based Least-connection ;
- lblcr : Locality-based Least-connection with replication ;
- rr : round-robin ;
- wrr : Weighted round-robin ;
- dh :Destination hashing ;
- sh :Source hashing ;
- sed : Shorted Expected Dealy ;
- nq : never queue.
Nous avons déjà vu ces protocoles dans la partie Heartbeat.
L'option lb_kind permet de choisir le type de réglage réseau (ici DR).
DR : il s'agit du mode de fonctionnement le plus simple, les adresses IP réelles des machines sont sur le même réseau que l'adresse IP virtuelle.
NAT : dans cette configuration, les machines réelles ne sont pas sur le même réseau que l'IP virtuelle. Le répartiteur de charge aura un accès aux deux réseaux, le réseau interne et le réseau externe. Les échanges entre le monde extérieur et les serveurs internes seront « natés », un peu comme ce que fait votre box Internet. Cette solution permet notamment d'utiliser des serveurs réels avec d'autres systèmes d'exploitation que Linux sur lesquels keepalived ne peut être installé.
TUN : les paquets à destination des serveurs réels sont transmis via un tunnel encapsulant le trafic. Il s'agit ici d’une configuration particulière nécessitant des compétences réseau avancées.
Vous pouvez voir dans la configuration la définition sorry_server commentée. Ce paramètre permet de définir les réglages d'un serveur devant répondre en cas d'indisponibilité d'une machine réelle.
11-3-6-5. Test de fonctionnement d’un serveur▲
Pour tester le fonctionnement d’un serveur, il est possible de lancer un script à intervalle régulier. Ce script testera ce que vous souhaitez (IP répondant, service actif, capacité mémoire/disque, etc.) et devra retourner 0 si OK et 1 sinon (exit 0 ; ou exit 1).
Pour cela il faudra ajouter le nom du script dans le bloc vrrp_instance comme ceci :
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 101
priority 100
virtual_ipaddress {
192.168.1.200
}
virtual_server 192.168.1.200 80 {
lb_algo wlc
lb_kind DR
#sorry_server 192.168.1.199
}
track_script {
test_ip
}
real_server 192.168.1.201 80 {
weight 1
inhibit_on_failure
}
real_server 192.168.1.202 80 {
weight 2
inhibit_on_failure
}
}L'option weight va permettre de générer une incidence sur la priorité d'utilisation d'un serveur réel par rapport à une autre.
L'option inhibit_on_failure permet de désactiver le load-balancing sur un serveur ne répondant pas.
Nous ajoutons également le bloc vvrp_script ci-dessous avant l'instance vrrp :
vvrp_script test_cluster {
script "/usr/share/test_cluster.sh"
interval 5 # test toutes les 5 secondes
fall 2 # nécessite deux échecs pour déclarer un KO
rise 2 # nécessite deux réussites pour déclarer un OK
}Un nouveau bloc vvrp_script, dans notre exemple test_cluster est ajouté au fichier pour définir le script à exécuter, et il est déclaré dans l’instance vvrp.
Il est possible d’appeler plusieurs vrrp_script les uns à la suite des autres.
Voici un exemple de script testant une IP :
#!/bin/bash
if ping -c 1 192.168.1.201 >/dev/null
then
exit 0;
else
exit 1;
fiExemple de test permettant de vérifier le fonctionnement d'un serveur Apache (répondant sur l'adresse 192.168.1.201) :
#!/bin/bash
test=$(wget -qO- 192.168.1.201>>/dev/null;echo $?)
if $test=0
then exit 0 ;
else exit 1 ;
fiAjouter dans l'instance une entrée notify suivi du nom du script va permettre d’effectuer des traitements supplémentaires, par exemple, arrêter le service apache :
#!/bin/bash
TYPE=$1
NAME=$2
STATE=$3
case $STATE in
"MASTER") service apache2 start
exit 0
;;
"BACKUP") service apache2 stop
exit 0
;;
"FAULT") service apache2 stop
exit 0
;;
*) echo "unknown state"
exit 1
;;
esac- TYPE contiendra GROUP ou INSTANCE ;
- NAME contiendra le nom du groupe ou de l’instance ;
- et enfin STATE contiendra MASTER, BACKUP, ou FAULT.
On trouvera plus de détails dans la documentation officielle de Keeplived.
12. Surveillance▲
Dans le cadre d'utilisation de services cloud grand public, vous n'aurez pas à vous préoccuper de la surveillance du bon fonctionnement du système, ceci étant effectué par votre fournisseur de services. Les drives type Google ou DropBox gardent en général par défaut une rétention des modifications et suppressions pendant 30 jours. Pour ce qui est des sites web mutualisés pouvant contenir des systèmes critiques tels que des CMS, des ERP fonctionnant sur les technologies PHP/MySQL, il vous faut connaître ce que propose votre hébergeur en termes de sauvegarde : sauvegarde intégrée (voir la fréquence et la rétention)/pas de sauvegarde, service gratuit/payant. Vous pourrez avoir des alertes automatiques notamment sur des comportements suspects (exemple :connexion inhabituelle), mais la surveillance du bon fonctionnement en dehors du matériel et du système reste à votre charge.
Une sauvegarde autonome hors hébergement (sur disque externe par exemple) reste indispensable, en cas de bug, de piratage de comptes, et aussi par le fait que les hébergeurs sont de plus en plus visés par des attaques de type cryptolockers.
Pour les services professionnels, votre prestataire vous garantira la disponibilité des ressources qu'il vous fournit, mais vous serez responsable de vos contenus et de leur protection, donc de leur sauvegarde. Des outils pourront vous être fournis pour vous faciliter la tâche.
Le terme informatique adopté et utilisé pour cette activité est la supervision.
12-1. Le plus simple : par mail▲
La plupart des services (au sens démon) seront capables de vous envoyer des mails en cas de problèmes. Cela peut être un moyen simple, mais pas forcément fiable. Exemple si le module générant les erreurs ou le serveur mail sont en défaut, vous ne recevrez plus les alertes. Ce système peut suffire si vous pouvez recevoir un rapport de bon fonctionnement. Dans ce cas, la non-réception de celui-ci indiquera un problème.
12-2. Syslog▲
syslog est un protocole de gestion de logs. Ceci permet à un logiciel de centraliser ses logs vers un serveur syslog plutôt que de les gérer dans son coin. La plupart des services sont capables de se greffer sur un serveur syslog. syslog gère dans ses messages des niveaux de priorité et de gravité.
Utiliser syslog dans un logiciel est simple, la fonction libc syslog le permettant.
Il existe des utilitaires permettant l'analyse des messages syslog.
syslog reste une solution bas niveau (c.-à-d. pour l'administrateur système) avec ses avantages et ses inconvénients.
12-3. Nagios▲
Nagios est un logiciel de supervision libre faisant référence. Il permet une surveillance centralisée de plusieurs équipements. Il se compose de son moteur de supervision, d'une interface web permettant une vue globale, et de greffons dédiés à la surveillance d'éléments précis, les plus simples étant la réponse au ping, l'état S.M.A.R.T d'un disque, l'état d'occupation disque, mémoire ; ainsi que des greffons plus poussés comme la présence d'un processus, il est possible de créer ses propres greffons.
Il existe des options similaires gratuites et payantes.
12-4. Prometheus/Grafana▲
Prometheus est un logiciel de surveillance et d'alerte libre créé à l'origine par SoundCloud pour ses besoins internes.
Grafana est un logiciel libre de génération de tableaux de bord et graphiques.
Les deux produits vont utiliser des informations stockées dans une base de données, dans notre cas la base sera alimentée par Prometheus, puis exploitée par Grafana.
Les deux solutions couplées vous permettront de générer votre propre système de surveillance personnalisé comme présenté dans ce tutoriel.
12-5. Solution maison▲
Si vous trouvez que Nagios est une usine à gaz, vous pourrez utiliser des outils existants ou développer votre propre solution maison.
Il vous faudra commencer par déterminer les points à surveiller. Nous mettons de côté la réponse au ping, le contrôle de l'espace disque qui sont les éléments de base à surveiller et considérés comme des prérequis.
Si nous devons surveiller le fonctionnement d'un site web par exemple, il vous faudra automatiser un dialogue avec celui-ci avec cUrl (client URL request Library) par exemple de façon à vérifier le comportement normal du site. Une simple requête HTTP ne permettra que de tester si le serveur HTTP est opérationnel, mais ne permettra pas de détecter un site en erreur.
Pour une solution à grande échelle, Nagios sera le produit adapté, car considéré comme un standard, il pourra être pris en main par n'importe quel administrateur système et non pas uniquement par vous suite à la mise en place d'une solution « exotique ».
13. Orchestration▲
L'orchestration consiste en la coordination et la gestion automatique d'un système informatique.
Dans les systèmes cloud à grande échelle, c'est ce qui va vous permettre la mise en service d'une machine virtuelle en 2-3 clics. C’est ce qui permet à un hébergeur de vous déployer un site web sans intervention humaine, quasi instantanément.
La partie la plus visible de l'orchestration est donc le déploiement. Kubernetes que nous avons déjà évoqué est une plateforme permettant le déploiement automatique de conteneurs, qui fait référence. Pour les machines virtuelles, cela se présentera sous forme de templates que l'on peut voir comme des modèles de machines virtuelles à déployer. Le déploiement d'un template est bien sûr automatisable.
Une des plateformes les plus connues de déploiement se nomme Ansible. Ansible est utilisable sous Windows pour certaines tâches, mais le serveur devra être installé sous Linux.
Dans le monde Microsoft, vous pourrez utiliser le serveur de déploiement WDS. D'autre part, Active Directory est conçu de façon à pouvoir installer automatiquement des logiciels depuis des stratégies de groupe qui sont appliquées à des utilisateurs, des groupes, des ordinateurs lors de la connexion au domaine Active Directory.
14. Conclusion▲
J'espère que ce tutoriel vous a éclairé sur ce qu'est le cloud computing et son principe de fonctionnement, j'ai essayé d'aborder tous les aspects possibles, de solutions cloud toutes faites à des solutions à mettre en place soi-même, plus ou moins complexes. Le domaine est vaste et le lecteur est invité à continuer ses recherches et ses expérimentations sur le sujet.
15. Remerciements▲
Je remercie Mickael Baron, khayyam90, LittleWhite, et Louis-Guillaume Morland pour leur relecture technique.
Je remercie Claude Leloup pour sa relecture orthographique.